



1. 引言:LLM 很强,但多数 Agent 用不上那么强
过去几年,大模型(LLM)像“万能插件”一样被应用在各种 Agent 里:代码 Agent、检索 Agent、行动规划 Agent……但实际工程实践更接地气:
绝大多数 Agent 的任务既不需要大模型的通用性,也不需要通篇长对话,它们只需要少量、可控、可复用的推理能力。
NVIDIA 的最新论文《Small Language Models are the Future of Agentic AI》 (arXiv: https://arxiv.org/abs/2506.02153)也明确表达了这种趋势:
SLMs 在 Agent 时代的重要性远被低估,它们将成为主力模型。
2. 什么是 SLM?
2.1 定义(来自公开资料 + 论文)
SLM(Small Language Model)通常指:
- 参数量 <10B(论文也采取此定义)
- 可以在 消费级设备(如个人 GPU、笔记本、手机) 上运行
- 具备足够低的延迟,支持 Agent 场景的实时推理
通俗讲:
SLM 就是能跑在你电脑上、推理够快、专做某件事的“小模型专家”。
2.2 为什么 SLM 的能力迅速逼近 LLM?
过去一年 SLM 进步巨大,主要原因:
- 更好的数据(高质量 instruction 数据集公开)
- 更强的训练方法(如 DPO、R1-Distill)
- 更高效的架构(如 Mamba、HybridAttention)
- 推理时多步思考(Test-time Scaling)让小模型表现“更聪明”
例如:
- Phi-3-mini (7B):在推理与常识能力上逼近 70B 模型
- Nemotron-H 2/4.8/9B:代码与工具调用能力接近 30B 级别
- DeepSeek-R1-Distill 1.5B–7B:在推理能力上超过不少闭源 LLM
因此,SLM 不再是“玩具模型”,而是真实可用的 Agent 模型基础设施。
3. 为什么说 SLM 才是未来 Agent 的主力?
本节解决的问题:LLM 的弱点是什么?为什么 Agent 的真实需求非常适合 SLM?
核心观点:
SLMs 足够强、天然更适合、也更经济,因此它们是未来 Agent 架构的核心。
4. SLMs核心优势
(1)SLM 的能力已经足够强
大量实验表明:
- 2B–7B 的模型已能胜任:推理 / 工具调用 / 代码生成 / 指令跟随
- 训练手段(R1 Distill、自注意力结构、LoRA 微调)让 SLM 的性能逼近老一代 LLM
- 大量任务是 重复性、结构化、非开放式,SLM 能轻松胜任
(2)SLM 更经济
大量数据表明:
- 单次推理 10–30× 更便宜
- 延迟更低
- 能直接跑在本地(无需云 GPU)
- LoRA 微调只需几小时即可完成
这意味着:
SLM 可以让 Agent 规模化,而不会被推理成本拖垮。
(3)SLM 天然更适合 Agent 的结构
Agent 的真实任务非常窄,而 LLM 是为通用性设计的,这是一种巨大错配。
Agent 的典型行为:
- 调工具(需要格式严格、不可犯错)
- 做一次判断
- 分段执行流程
- 重复任务(如摘要、结构化抽取、代码生成)
这些任务 都适合稳定、可控、便宜的小模型
Agent 其实只用到 LLM 的极小部分能力。
例如:
- 格式化输出
- 填充参数
- 解析指令
- 生成工具调用
这些都不是 LLM 的“强项”,而是 SLM 通过微调可以做到“更稳定”的地方。
Agent 中模型调用链路,每个节点的能力需求
(4)Agent 对行为对齐的要求极高,而 SLM 更好调
- 工具调用必须 100% 符合格式
- 输出必须是严格 JSON 或结构化格式
- 不能随意发挥
- 控制 token 更容易
SLM 更容易通过微调强制保持稳定输出格式。
(5)Agent 系统天然支持多模型协作(SLM + LLM)
- 主决策层可用 LLM
- 子任务可由多个 SLM 完成
- 之后整个系统逐步迁移到 SLM-first
LLM orchestrator + 多 SLM worker
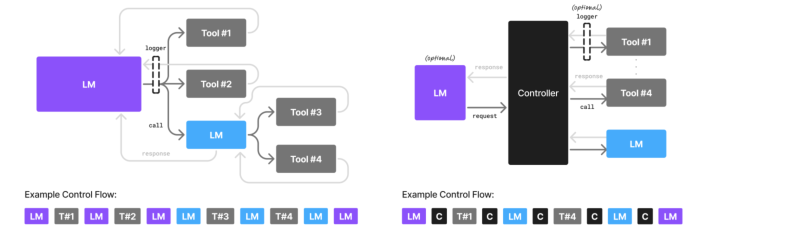
每次 Agent 调用其实都在生成“未来 SLM 微调的数据”
Agent 的操作日志、本地指令调用、本地失败案例
→ 都能反向作为 SLM 的训练集
→ 系统越用越好
这让“靠 SLM 替换 LLM”变成一个自增强循环。
5. 从 LLM 迁移到 SLM 的工程方法
SLMs 已能覆盖绝大多数 Agent 的关键子任务(工具调用、结构化生成、代码生成、格式化输出等),并在延迟、成本、部署灵活性上全面优于 LLM。更重要的是,Agent 本身就是“多步骤 + 多工具 + 强格式约束”的工程系统,其中每次模型调用都只需要执行非常窄的能力片段,因此本质上更适合由小模型担当执行器,而 LLM 则作为 orchestrator 按需调用即可。在工程落地层面,论文还提出了一套从 LLM 迁移到 SLM 的完整方法:先在真实 Agent 流程中通过日志收集模型输入/输出(S1),接着进行隐私与敏感内容清洗(S2),然后基于任务模式进行聚类(S3),为每类任务选择合适的小模型(S4),再通过 LoRA/QLoRA 或蒸馏做小模型微调(S5),最后在系统运行中持续迭代优化(S6)。这意味着 SLM-first 不只是理论趋势,而是基于现有 Agent 架构即可逐步实现的现实路径。总结来看:未来的 Agent 系统将从“大模型全包”走向“LLM 负责协调、SLM 负责执行”的多模型协作架构,而这将带来更低成本、更强可控性与更高系统可扩展性。
6. 什么时候不能全用 SLM?
行业阻力:
- 云厂商在 LLM 上投入巨大(数十亿美元)
- 工程团队默认用 LLM,缺乏 SLM 认知
- 基准测试仍偏向通用能力,而非 Agent 任务
技术限制:
SLM 有些任务仍不适合:
- 开放式对话
- 高复杂度长文档推理
- “未知领域”的迁移能力
7. 总结:未来是「LLM 作 orchestrator,SLM 作执行器」
结合论文观点与工程趋势,可总结为:
未来 Agent 的架构不再是一个大模型,而是一组可组合的“小模型专家”。
它们具备:
- 更高性价比
- 更强可控性
- 更稳定的结构化输出
- 更适合工程管线
- 更容易进化(可通过自身调用日志反向微调)
在“Agent 工程化”的时代,
SLM-first 架构是更现实、也更可扩展的方向。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









