



大模型技术迭代的速度正以“月”为单位颠覆行业认知——2025年的面试战场,早已不是比拼手写Transformer公式或调参技巧的擂台。随着技术落地深水区的到来,企业对人才的筛选逻辑发生剧变:能否用大模型撕开商业缺口,成为衡量价值的唯一标尺。
本文基于上百场真实面试复盘,提炼出2025年大厂高频考题的四大核心模块:
- 技术深水区攻坚(如多模态对齐中的模态冲突消解、MoE架构的动态负载优化)
- 工程化绞杀战(千亿模型端侧部署、推理延迟与成本的帕累托最优解)
- 商业闭环设计(从Agent工作流重构传统业务,到AB测试框架量化模型收益)
- 合规性攻防(模型幻觉的实时监测、数据隐私与输出安全性的平衡术)
题目覆盖字节“直播场景多模态实时互动方案”、阿里“大模型驱动的供应链决策系统”、腾讯“游戏NPC人格一致性保持”等真实业务场景,每道题附三阶解析:技术方案设计→工程陷阱预判→ROI测算推演。
无论你是想冲刺大厂的应届生,还是计划从传统算法转型的老兵,这份手册将帮你跳过“技术内卷”的泥潭,直击“技术变现”的靶心——2025年,大模型的竞争注定属于那些左手握算法,右手执商业的“双核破壁人”。
字X跳动 大模型高频面试题
- 能否概述一下 Transformers 的架构?
- 下一句预测(NSP)在语言建模中是如何使用的?
- 如何评价语言模型的性能?
- 生成语言模型如何工作?
- 大型语言模型上下文中的标记是什么?
- 在NLP中使用基于Transformer的架构与基于LSTM的架构有何优势?
- 能是供一些大型语言模型中对齐问题的例子吗?
- 自适应 Softmax在大型语言模型中有何用处?
- BERT训练如何进行?
- Transformer 网络比比CNN和RNN有何优势?
- 有没有办法训练大型语言模型(LLM)来存储特定的上下文?
- 您可以在LLM中使用哪些迁移学习技术?
- 什么是迁移学习?为什么它很重要?
- 编码器和解码器模型有什么区别?
- Wordpiece和 BPE有什么区别?
- (LLMD) 中的全局注意力和局部注意力有何区别?
- LLM 中的next-token-prediction和 masked-language-modeling有什么区别?
- 为什么基于Transformer 的架构中需要多头注意力机制?
- 为什么要使用编码册-解码册RNN而不是普通的序列到序列RNN进行自动翻译?
- 解释一下Transformer 架构中的Self-Attention机刷是什么?
- 迁移学习如何在(LLM)中发挥作用?
- LLM参数与神经网络中的权量有何关系?
- 精细调整LLM有哪些缺点?
- BERT 中的Word Embedding、Position Embedding和 PositionalEncoding有什么区别?
- 基于特征的迁移学习与(LLM)中的微调有何区别?
- 为什么transformer 需要位量编码?


腾X 大模型高频面试题
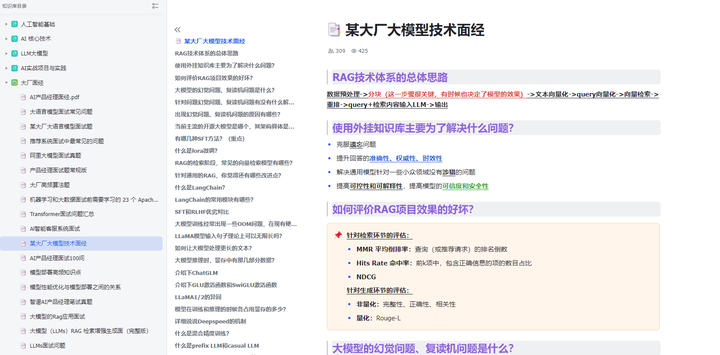
- RAG技术体系的总体思路
- 使用外挂知识库主要为了解决什么问题?
- 如何评价RAG项目效果的好坏?
- 大模型的幻觉问题、复读机问题是什么?
- 针对问题幻觉问题、复读机问题有没有什么解决办法?
- 出现幻觉问题、复读机问题的原因有哪些?
- 当前主流的开源大模型是哪个,其架构具体是怎样的?
- 有哪几种SFT方法?(点)
- 什么是lona微调?
- RAG的检素阶段,常见的向量检素模型有哪些?
- 针对通用的RAG,你觉得还有哪些改进点?
- 什么是LangChain?
- LangChain的常用模块有哪些?
- SFT和RLHF优劣对比比
- 大模型训练经常出现一些OOM问题,在现有硬件基础下,有什么性能提升trick
- LLaMA模型输入句子理论上可以无限长吗?
- 如何让大横型处理更长的文本?
- 大模型推理时,显存中有那几那分数据?
- 介绍下ChatGLM
- 介绍下GLU撇活语数和SwiGLU邀活通数
- LLaMA1/2的异同
- 模型在训练和推理的时候各占用显存的多少?
- 详细说说Deepspeed的机制
- 什么是混合精度训练?
- 什么是prefix LLM和casual LLM
- 说一说针对MHA后续的一些计算优化工作
- 说说attention几种常见的计算方式

阿X巴巴 大模型高频面试题
一、基础面
- 目前主流的开源模型体系有哪些?
- prefixLM和causal LM区别是什么?
- 涌现能力是啥原因?
- 大模型LLM的架构介绍?
二、进阶面
- 什么是LLMS复读机问题?
- 为什么会出现LLMS复读机问题?
- 如何缓解LLMS复读机问题?
- llama输入句子长度理论上可以无限长吗?


大厂LLM面试必考题
- Transformer的优缺点
- Encoder端和Decoder端是如何进行交互的?
- 为什么需要multi-head attention?
- QK为什么要除以dk来进行Scale?
- 为什么使用不同的K和Q,为什么不能使用同一个值?
- 在计attention score的时如何对padding做mask操作?
- self-attention是什么?
- 关于 self-attention为什么它能发挥如此大的作用?
- Transformer 中的Add & Norm 模块,具体是怎么做的?
- 简单介绍一下Transformer的位量编码?有什么意义和优缺点?
- 为什么transformer块使用LayerNormi而不是BatchNorm?
- Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
- Transformer attention的注意力矩阵的计算为什么用乘法而不是加法?
- Transformer的残差结构及意义
- Transformer的并行化体现在哪里,Decoder可以做并行化吗?

由于篇幅限制就只截图展示部分内容了!
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









