




0
使用CLIP进行IQA:CLIPIQA(2023 AAAI)
本文将围绕《CLIPIQA: Exploring CLIP for Assessing the Look and Feel of Images》展开完整解析。
该研究首次探索了CLIP 模型在图像的质量感知(look)和抽象感知(feel)评估中的潜力,提出了CLIP-IQA模型,其核心改进为反义词提示词配对策略和移除位置嵌入,无需任务特定训练即可实现评估。在多个 IQA 基准数据集(KonIQ-10k、LIVE-itW、SPAQ 等)上,CLIP-IQA 性能优于多数无监督 IQA 方法且媲美部分有监督方法,微调后的CLIP-IQA⁺更接近 SOTA 水平;同时该模型可完成亮度、噪点等细粒度质量属性及情绪、美学等抽象属性评估,在用户研究中抽象感知判断准确率达80%,但存在提示词选择敏感、专业术语识别弱等局限性。参考资料如下:
[1]. 代码地址
[2]. 论文地址
论文整体结构思维导图如下:

专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
【7】Q-align
【8】GMSD
【9】NIQE
【10】MUSIQ
【11】CDI
【12】Q-BENCH
【13】Q-Instruct
【14】A-Fine
【15】MANIQA
一、研究背景
作者指出图像感知分为质量感知(look)和抽象感知(feel):前者是可量化属性(如曝光、噪点),后者是抽象概念(如情绪、美学),这里的情绪指看到这幅图像的心情。
现有图像评价的总结:
- 传统方法缺陷:无监督 IQA 依赖手工特征(如自然场景统计),与人类感知相关性低;
- 有监督方法需大量标注且任务专用,泛化性差;抽象感知评估完全依赖标注数据,成本极高。
在此背景下,CLIP 通过大规模图文对预训练,具备强大的视觉 - 语言语义关联能力,作者认为其可迁移至图像感知评估,实现无任务训练的通用评估。如下图所示:
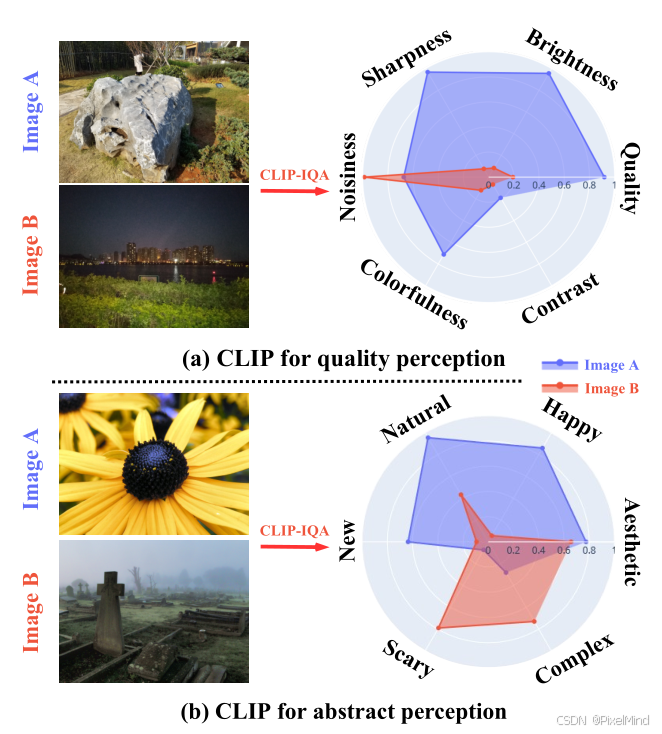
作者用clip完成了细粒度质量的评估和抽象的感知,图(a)展示了对噪声、对比度等指标的评估,图(b)展示了美学和情绪的评估。
二、CLIPIQA方法
论文整体结构如下所示:
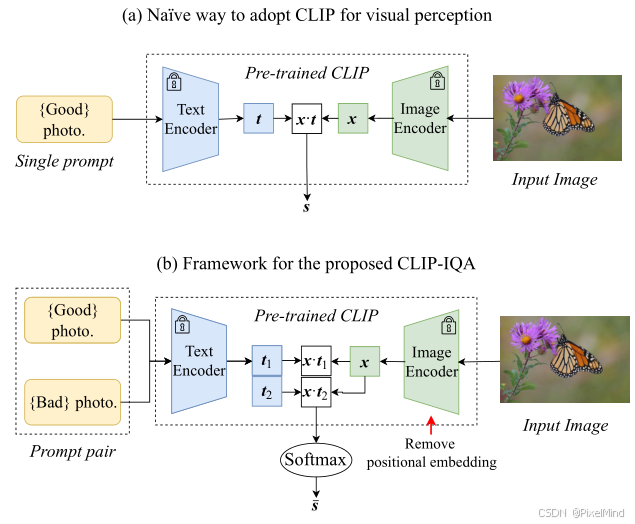
原有的CLIP做视觉感知的方法是直接评估与Good photo语句的相关性,如下式所示:
s
=
x
⊙
t
∥
x
∥
⋅
∥
t
∥
s=\frac{x \odot t}{\| x\| \cdot\| t\| }
s=∥x∥⋅∥t∥x⊙t其中
x
∈
R
C
x \in \mathbb{R}^{C}
x∈RC 代表输入图像经CLIP图像编码器提取的特征向量(
C
C
C 为特征通道数);
t
∈
R
C
t \in \mathbb{R}^{C}
t∈RC 代表文本提示词经CLIP文本编码器提取的特征向量;
⊙
\odot
⊙ 代表向量点积运算;
∥
⋅
∥
\|\cdot\|
∥⋅∥ 代表
ℓ
2
\ell_2
ℓ2 范数(欧几里得范数);
s
∈
[
0
,
1
]
s \in [0,1]
s∈[0,1] 代表图像与提示词的语义匹配得分。
作者认为这种方式不合理,容易有歧义,做了以下两点改进:
-
修改为图(b)的两个prompt对,计算一个softmax的方式,如下式所示: s i = x ⊙ t i ∥ x ∥ ⋅ ∥ t i ∥ , i ∈ { 1 , 2 } s_{i}=\frac {x\odot t_{i}}{\| x\| \cdot\| t_{i}\| }, \quad i\in \{ 1,2\} si=∥x∥⋅∥ti∥x⊙ti,i∈{1,2}其中 x x x、 ⊙ \odot ⊙、 ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 含义同公式(1); t 1 t_1 t1、 t 2 t_2 t2 代表一对语义相反的文本提示词特征向量; s i s_i si 代表图像与第 i i i 个提示词的余弦相似度得分; i ∈ { 1 , 2 } i \in \{1,2\} i∈{1,2} 代表提示词对的索引(1为正向、2为反向)。
最终的得分可用下式所示来计算: s ‾ = e s 1 e s 1 + e s 2 \overline{s}=\frac{e^{s_{1}}}{e^{s_{1}}+e^{s_{2}}} s=es1+es2es1其中 s 1 s_1 s1、 s 2 s_2 s2 代表公式(2)中两个反义词提示词对应的余弦相似度得分; e ⋅ e^{\cdot} e⋅ 代表自然指数函数; s ‾ ∈ [ 0 , 1 ] \overline{s} \in [0,1] s∈[0,1] 代表最终的图像感知评估得分(值越大越符合正向提示词属性)。 -
选用 ResNet 骨干并移除位置嵌入:基于transformer的VIT架构来提取特征,必须将图像进行resize,IQA任务引入resize会对于分辨率不敏感,如果强行去除position embedding,则基于vit的结构效果大大降低,因此作者选用了Resnet的clip网络并移除了位置嵌入,打破 CLIP 固定输入尺寸限制,避免图像缩放 / 裁剪引入的失真。
以上,作者做了CLIPIQA的两个版本:
- CLIP-IQA:基础版本,无任何任务特定训练,直接基于 CLIP 预训练权重和改进策略实现评估。
- CLIP-IQA⁺:基于 Coop方法微调提示词(网络权重固定,训练prompt,此时good和bad是学习的),在 KonIQ-10k 上训练 10 万轮(SGD 优化器、学习率 0.002、批次 64、MSE 损失),提升评估性能。
2.1 Quality Perception
- 整体图像质量评估:只需要以下的prompt:

对比了一些无监督和有监督的NR IQA方法,效果是可见的。
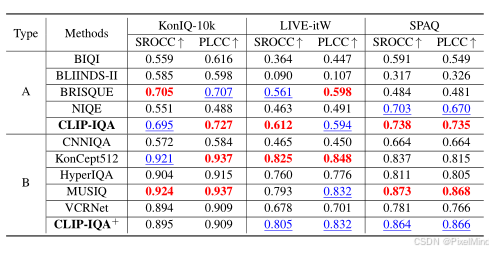
有以下结论:
- 基础版 CLIP-IQA(无任务训练)在所有无监督 IQA 方法中性能最优,SROCC/PLCC 均超过 BIQI、BLIINDS-II 等传统无监督方法,且媲美轻量化有监督方法 CNNIQA;
- 微调版 CLIP-IQA⁺(仅微调提示词)性能大幅提升,在 KonIQ-10k 上 SROCC 达 0.895、PLCC 达 0.909,接近 MUSIQ 等 SOTA 有监督模型,且跨数据集泛化性优于多数任务专用模型;
- 在合成失真数据集 TID2013 上,CLIP-IQA⁺虽性能低于专门针对合成失真优化的方法,但仍显著高于基础无监督方法,验证了对合成失真的感知能力。
展示了一些高分和低分的效果图,与人类认知一致。

- 细粒度的质量评估:在之前的基础上加上跟属性相关的内容,例如“Bright photo.” 和 “Dark photo.”。以下是作者做的一个相关度分析,合理的。
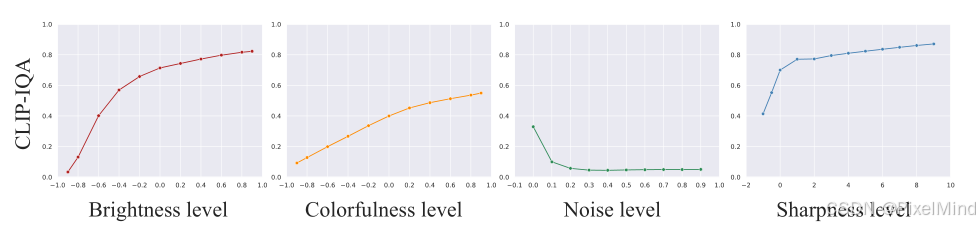
另外又针对于各种图像增强算法处理前的lq和gt进行了对比。

所有修复基准中,高质量图像的 CLIP-IQA 得分均显著高于低质量图像(如 LOL 低光图得分 0.012,真值图得分 0.809;RealBlur 模糊图得分 0.001,去模糊图得分 0.342)。
2.2 Abstract Perception
作者评估了以下的几个方面: complex/simple, natural/synthetic, happy/sad, scary/peaceful, new/old。选出了一部分代表性的展示了CLIP的有效性。

然后又做了user study证明其有效性。

三、讨论
3.1 prompt的设计

其中(1)(2)(3)分别是3种不同的prompt,表格上方文字可见, 可以得到以下结论:
- 提示词模板对性能影响极大:“[text] photo.” 模板(如 “Good photo.”)的性能是 “A photo of [text].” 模板的 6 倍以上(SROCC 0.695 vs 0.116);
- 形容词选型偏好:日常形容词(Good/Bad)比专业术语(High quality/Low quality)适配性更强,SROCC 提升约 0.16;
- 反义词配对策略的性能显著高于单一提示词策略,SROCC 平均提升 0.23,验证了该策略对语言歧义的缓解作用。
3.2 图像编码器的Backbone
还是table2。
① ResNet 骨干移除位置嵌入后性能大幅提升(SROCC 从 0.383 升至 0.695),且支持任意尺寸图像输入,无缩放 / 裁剪失真;
② ViT 骨干依赖位置嵌入,移除后性能小幅下降(SROCC 从 0.416 降至 0.391),不适用于该任务;
③ 最终选择 ResNet-50 作为 CLIP-IQA 的骨干网络,兼顾性能与输入尺寸灵活性。
3.3 局限
作者提到了以下3点:
- 对提示词选择高度敏感,缺乏系统化选型方案;
- 无法识别 “三分法”“浅景深” 等专业摄影术语;
- 与任务专用模型存在性能差距,无专用架构设计。
四、总结
文章第一次成功尝试使用CLIP来进行IQA的评估,取得了一些进展。后续作者将会从3个方面优化提示词设计策略;用专业术语图文对预训练 CLIP;融合任务专用架构与 CLIP 的视觉 - 语言先验。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









