





Q-Instruct:提升MLLM的IQA能力(2024 CVPR)
本文将围绕《Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models》展开完整解析。
为提升多模态基础模型(MLLMs)的低阶视觉能力(如图像清晰度、噪声、质量评估等),研究团队构建了包含58K 人类反馈的 Q-Pathway 数据集(覆盖 18,973 张多源图像),并通过 GPT 将其转化为含200K 指令 - 响应对的 Q-Instruct 数据集;采用 “与高阶视觉数据集混合训练” 和 “高阶训练后追加低阶训练” 两种策略,在 LLaVA-v1.5、mPLUG-Owl-2 等 4 个基线模型上验证了 Q-Instruct 的有效性 —— 模型在低阶视觉感知(MCQ 准确率平均提升 5%-10%)、描述(相关性 + 0.31)和质量评估(“未见过” 数据集 SRCC 平均提升 0.243)任务上表现显著提升,为 MLLMs 适配低阶视觉任务奠定基础。参考资料如下:
[1]. 项目地址
论文整体结构思维导图如下:

专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
【7】Q-align
【8】GMSD
【9】NIQE
【10】MUSIQ
【11】CDI
【12】Q-BENCH
一、研究背景
多模态基础模型(MLLMs)已实现高阶视觉任务(图像 caption、VQA)的统一处理,但在低阶视觉任务中存在明显短板 —— 低阶视觉属性识别(如噪声、模糊)、图像质量评估(IQA)等任务准确率不足,且现有训练数据多聚焦高阶视觉,缺乏低阶视觉专用数据集。如下图所示:

未进行微调的LLaVA大模型无法完成这个任务。
为了进一步提升MLLM模型IQA的准确性,作者收集了第一个在low level角度上使用人类语言反馈组成的数据集Q-Pathway,每个反馈提供了一个图像的low level属性的全面描述,最终组成一个全面的质量评估。进一步的,为了使得MLLM能够熟练的完成其他查询任务,作者提出了一种gpt参与的转换,将这些反馈转化为了一组丰富的200K指令响应对,称为Q-instruct。
接下来就将介绍这两个数据集。
二、Q-Insturct数据集
包含两个部分,第一个部分是Q-Pathway,它包含了多个来源采集的数据集以及人类对他们的low level属性描述+ 整体质量结论,第二个是Q-insturct,此是利用GPT根据描述回答的一系列指令问题组成的新的指令相应对数据。
2.1 Q-Pathway
首先是收集数据集,如下图所示:

分为两步:
-
采样:从 7 个来源采样以平衡低阶视觉外观,包括 4 个in-the-wild IQA 数据集(KonIQ-10k、SPAQ 等)、2 个 AI 生成图像数据集(AGIQA-3K、ImageRewardDB)、1 个人工失真数据集(15 种失真处理的 COCO 子集),最终采样后图像 MOS 分布更均衡(整体 μMOS=49.87,σMOS=19.08),如上图(a)所示,整体数据如下表所示。

-
收集:在这一步中,邀请人类受试者直接反馈他们对各种图像的low level属性的感知和理解,包含两个部分,第一点是必须对基本属性(模糊、噪声、亮度等)进行详细描述,描述中还必须包含上下文信息,即描述出哪个位置;其次必须根据这些属性对整体质量进行推理,并进行总结,因此Q-pathway数据集不仅包含了对low level属性的感知过程,还包含了IQA的推理过程。这种方式能够有效的使MLLM与人类对齐。下面是作者给出了一个feedback示例。

可以看到所有的描述包含了上下文的low level信息,并最终给出了质量评价结果,这里的红色代表负面评价,绿色代表正面评价,紫色代表上下文或条件信息。
作者还对数据集中一些属性进行了统计,例如回复的长度、词语的频次等。


2.2 Q-Instruct
为了激活MLLM更多的功能,作者设计了将Q-pathway的反馈转换为指令回答对的Q-insturct数据集,使用了GPT来完成这项功能,如下图所示:

通过以上的方式能够生成一个low level层面的视觉回答(VQA)数据集,在GPT的帮助下可以生成一系列如为什么会发生扭曲以及如何提高图像质量的回答。最后作者可以应用这些数据集微调MLLM模型。

微调后的MLLM模型可以完成多项功能,例如描述、感知、问答以及质量评估。接下来是作者举得一些例子:

可以如Q-pathway一样描述图像(a),可以进行问答(b),可以做扩展谈话(c)。
2.3 Q-Instruct微调MLLM
如下图所示:

作者讨论了两种不同的训练MLLM的策略,一般来说训练MLLM包含两个阶段,第一个阶段是将多模态的信息进行对齐,即visual和LLM的embedding使用百万级web数据对齐,后续再根据人工标记的数据集进行微调,一般的策略是直接使用Q-insturct和现已有的数据集进行混合,另一种更快的方式是直接使用Q-insturct进行微调,这两种方式都可以提升mLLM性能。
三、实验
以下是作者使用的baseline模型。

这里作者也做了跟Q-bench(加入引用后续)一样的多角度能力的评估,包含低层次感知能力、低层次描述能力以及分数评估能力,不熟悉的读者可以看一些Q-bench。
3.1 低层次感知能力(A1):整体准确率
如下图所示:通过 MCQ (Multiple Choice Question)测试低阶属性识别准确率,含 Yes-or-No、What、How 等子类型;
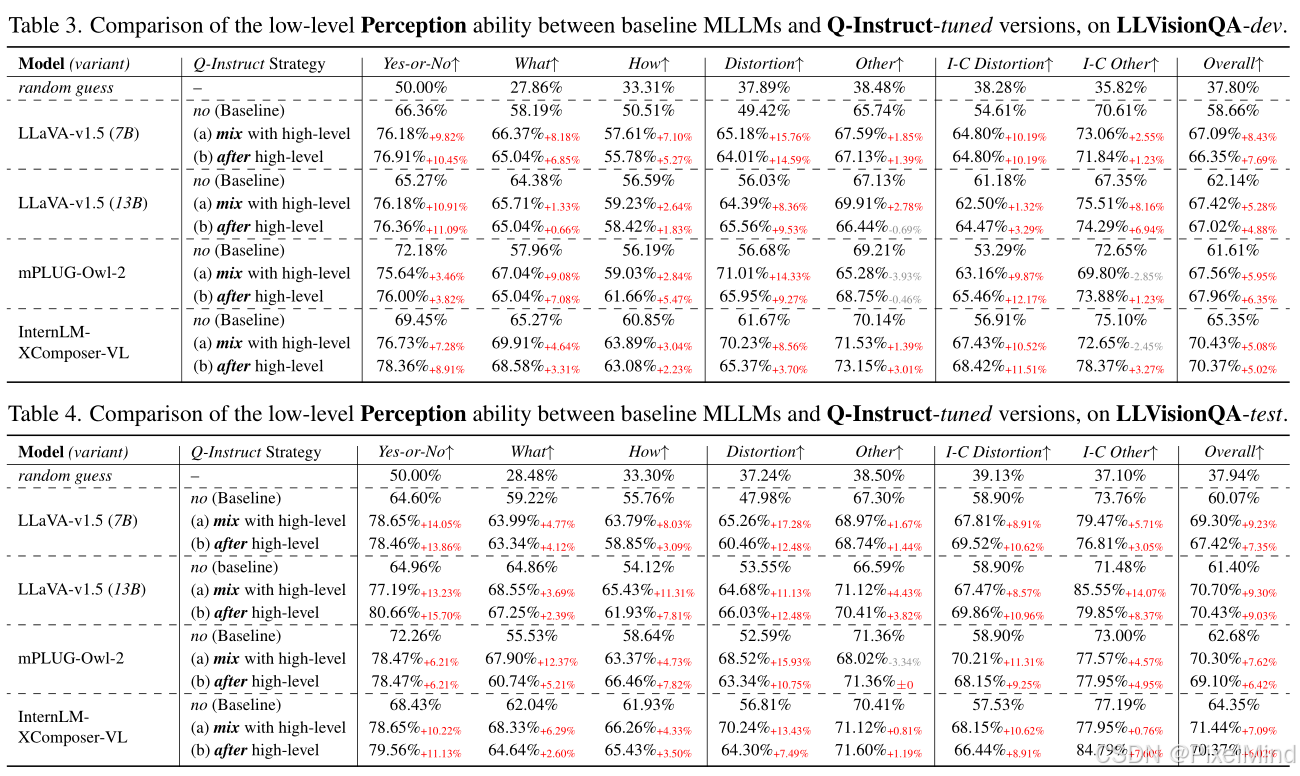
所有模型经 Q-Instruct 微调后,MCQ 整体准确率平均提升 5%-10%,其中 Yes-or-No 类问题提升最显著(如 LLaVA-v1.5-7B 在测试集上从 64.60% 升至 78.65%),失真类问题准确率提升高于美学、摄影技术类;
3.2 低层次描述能力(A2):总分(3 维度之和)
如下图所示:

描述任务:模型描述的相关性提升最明显(平均 + 0.31),完整性 + 0.17,精确性 + 0.04,说明现有指令格式更适配属性相关性表达;
3.3 质量评估能力(A3):平均 SRCC/PLCC
如下图所示:
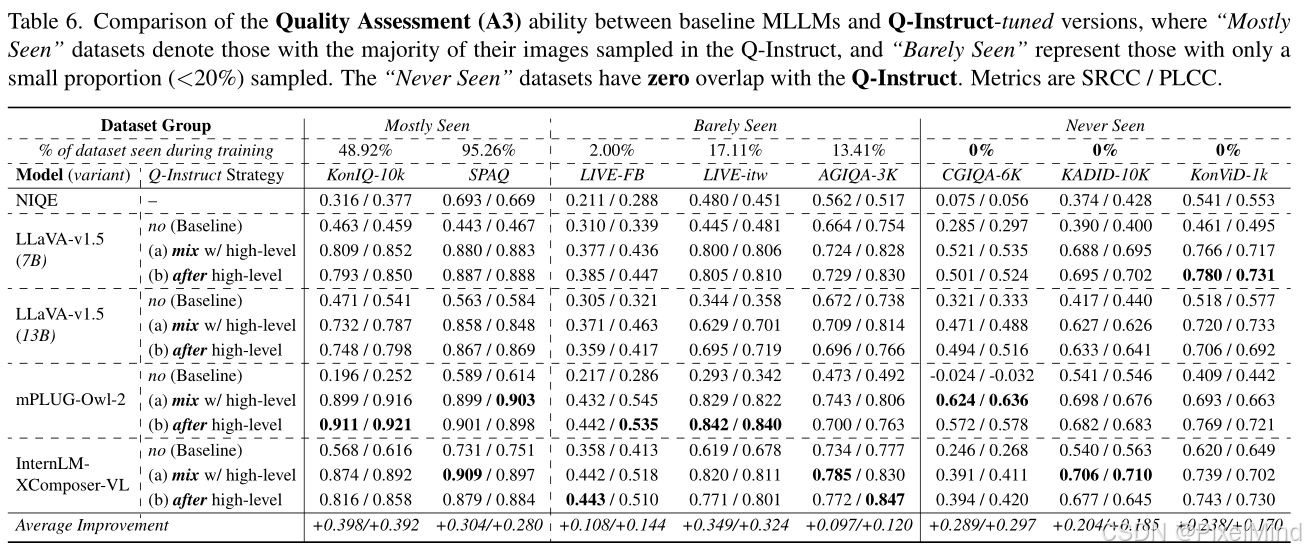
无需数值监督(如 MOS),模型在 “常见” 数据集(如 KonIQ-10k)SRCC 提升 0.398,在 “未见过” 数据集(如 KonViD-1k 视频帧)SRCC 平均提升 0.243,证明泛化能力强。
3.4 消融实验
-
数据规模影响:扩大 Q-Instruct 数据量可持续提升模型低阶视觉准确率,现有 200K 规模仍未达性能饱和;如下图所示:

-
联合训练优势:Q-Instruct 多子集联合训练的效果优于单独训练(如仅用 VQA 子集),因子集间源自同一人类反馈,可互补信息;如下图所示:

-
high level认知必要性:若用 Q-Instruct 替代high level训练数据集,模型low level能力提升会显著下降,证明高阶视觉认知是低阶能力的基础。

四、总结
该论文首次构建低阶视觉专用指令微调数据集,填补 MLLMs 低阶视觉训练数据空白,验证了 “文本驱动的指令微调” 可让 MLLMs 对齐人类低阶视觉认知,无需依赖数值标签,从而为 MLLMs 统一低阶视觉任务(感知、描述、IQA)提供可行方案。
局限在于:模型微调后在通用语言任务(如文本推理)上性能下降;模型低阶视觉任务准确率(68%-71%)仍低于人类平均水平(约 74%);数据集以野生图像为主,对特殊类型图像(如医学影像)的适配性待验证。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









