





Low-Light Image Enhancement via Generative Perceptual Priors(AAAI,2025)
本文将对 Low-Light Image Enhancement via Generative Perceptual Priors,这篇暗光增强算法进行讲解。参考资料如下:
专题介绍
在低光照环境下,传统成像设备往往因画面昏暗、细节丢失而受限。LLIE(低照度暗光增强)技术应运而生,它通过提升图像亮度、对比度,减少噪点并恢复色彩细节,让暗夜变得清晰可见。
LLIE技术从传统方法如直方图均衡化、Retinex模型等起步,近年来借助深度学习,尤其是卷积神经网络(CNN),GAN模型,扩散模型实现了质的飞跃。这些算法能自动学习图像特征,精准处理低光照图像,效果显著优于传统技术。
本专题将聚焦LLIE技术的核心原理、应用案例及最新进展,让我们一起见证LLIE如何点亮暗夜,开启视觉新视界!欢迎一起探讨交流!
系列文章如下
【1】ZeroDCE
【2】HVI
【3】CLIP-LIT
【4】GLARE
【5】Retinexformer
【6】SG-LLIE
一、研究背景
暗光增强由于实际场景中光照条件复杂多样,生成视觉上逼真的增强效果仍是一个非常有难度的任务。本文作者提出了一种基于生成感知先验(GPP-LLIE)的新型低光照图像增强框架,该框架的生成感知先验源自视觉语言模型(VLMs)。
二、GPP-LLIE方法
1.总体方案及创新点
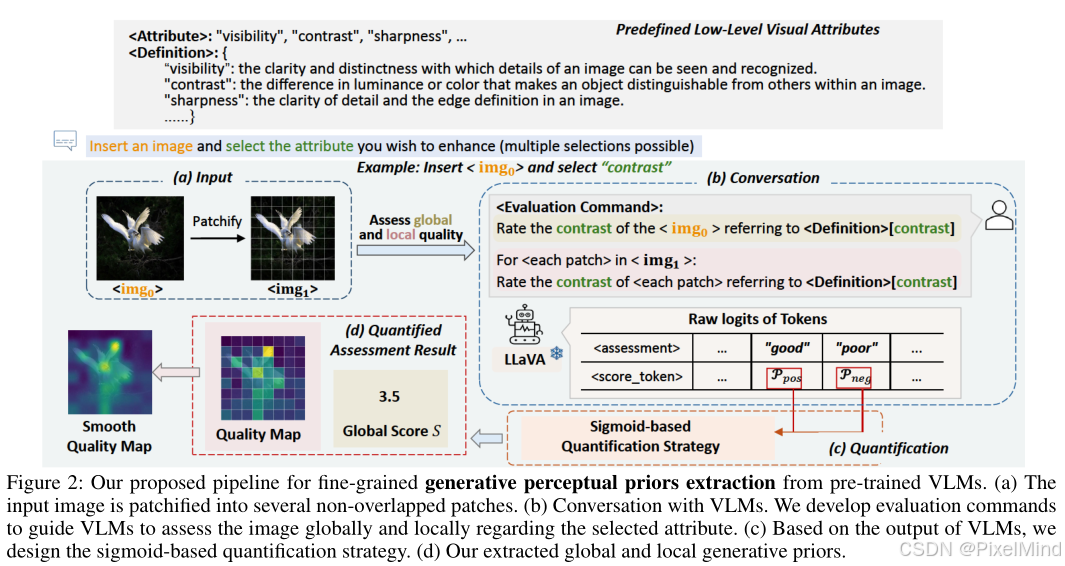
具体而言,作者首先提出了一个pipeline,引导视觉语言模型评估低光照图像的多种视觉属性,并将评估结果量化,以输出全局和局部感知先验。
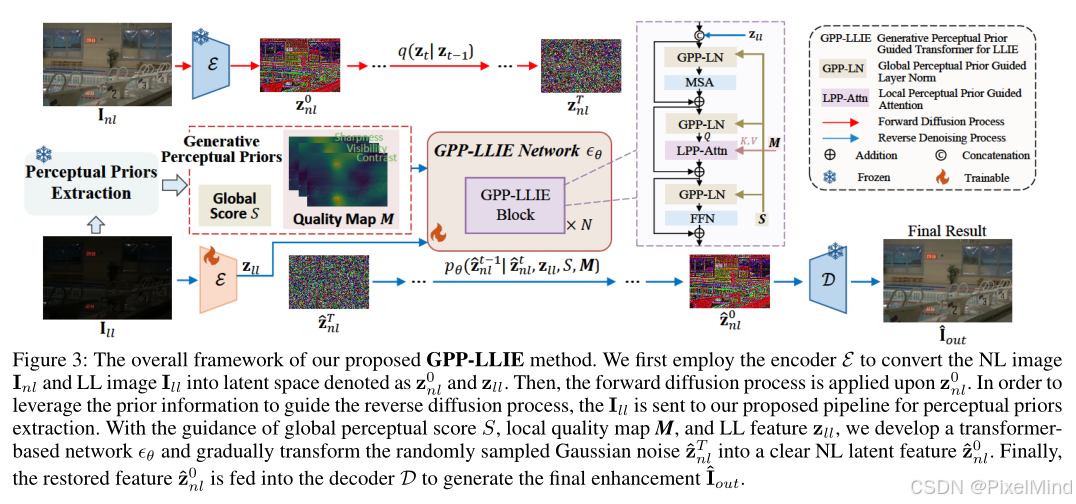
随后,为了将这些生成感知先验融入低光照图像增强过程,在扩散过程中引入了一个基于Transformer的主干网络,并开发了一种由全局和局部感知先验引导的新型层归一化(GPP-LN)和注意力机制(LPP-Attn)。
本文创新点如下:
- (1) 基于预训练的视觉语言模型(VLM),从全局和局部获取低光图像的生成感知先验。
- (2) 在全局和局部生成感知先验的指导下,为低光图像增强(LLIE)开发了一种基于Transformer的高效扩散框架(GPP-LLIE)。
- (3) 引入全局感知先验来调节层归一化(GPP-LN),并利用局部感知先验来引导transformer中的注意力机制(LPP-Atn)以改善增强过程。
2.详细方案
主要分为三个部分:
- 说明在低光照图像增强(LLIE)任务中采用源自视觉语言模型(VLM)的指导的动机。
- 提出了一种创新的pipeline,该pipeline引导视觉语言模型(VLM)从全局和局部评估低光照图像的视觉属性,然后通过引入基于Sigmoid的量化策略提取感知先验。
- 开发了一个基于Transformer的扩散结构,并结合这些先验来指导反向扩散过程。
2.1 动机
低光照图像增强普遍遇到的情况是训练数据和真实遇到的情况难以保证一致,当前的LLIE方法普遍无法在不同光照条件下自适应地增强图像。因此,使模型能够自主感知并适应各种视觉失真至关重要。受近期涌现的视觉语言模型(VLM)在低级视觉感知与理解方面所展现能力的启发,作者想到了利用VLM的这些感知能力来推动低光照图像增强任务的潜力。
需要注意的是利用语言模型进行图像增强任务并不罕见,比如之前介绍的CLIP-LIT,也是利用了语言模型作为损失函数进行增强。其实,并非暗光增强任务可以用语言模型作为先验,其他图像增强复原任务也可以,比如图像复原,图像去雾,图像超分等。
2.2 VLM提取感知先验
视觉语言模型(VLMs)通常使用数百万个文本-图像对进行训练;因此,利用视觉语言模型中固有的先验信息来帮助低光照图像增强(LLIE)模型在恢复过程中做出更合适的决策,从本质上来说是很有前景的。本文采用的视觉语言模型是LLaVA(LLaVA 是由 Haotian Liu 等人开发的开源端到端训练的大型多模态模型,全称为 Large Language and Vision Assistant,旨在实现 GPT - 4 级别的视觉 - 语言交互能力)。
在本文中,作者通过设计文本提示;引导LLaVA评估低光照图像的多种视觉属性;引入量化策略,输出量化的全局评估和局部质量图;来作为低光照图像增强的感知先验。 流程图是上图Figure2。
-
设计文本提示
作者提供了几个低层次视觉属性供选择,并给出相应的定义,以帮助视觉语言模型更好地理解评估任务。具体来说,给定一张图像 < i m g 0 > <img_{0}> <img0>,可以从中选择属性进行评估。由于低光照图像增强旨在提高低光照图像的对比度、可见度和清晰度,我们可以在低光照输入中依次评估这些属性。 -
进行评估
①全局评估:对全图进行评估;
②分块评估:考虑到低光图像中对比度、可见度和清晰度的变化,作者提出了提取局部评估以进行细粒度增强。具体来说,输入的被分割成几个不重叠的图像块 < i m g 1 > <img_{1}> <img1>,每个图像块都输入到LLaVA中以获取局部评估。
对话期间的整体评估指令定义为图2中的<Evaluation_Command>。 -
量化策略
这里可以理解为如何把VLMs模型的评估转化成数值进行量化
本文策略是依据“好”与“差”在评价结果中出现的概率来设计的。量化的全局分数S计算为 S = ( 1 + e − ( P p o s − P n e g ) / α ) − 1 S=(1+e^{-(P_{pos }-P_{neg }) / \alpha})^{-1} S=(1+e−(Ppos−Pneg)/α)−1 ,这个公式可以看出来是使用了一个Sigmoid操作进行调整。表示“好”和“差”的概率分别用 P p o s P_{pos } Ppos和 P n e g P_{neg } Pneg表示, α \alpha α是调整系数,在本文中设置为3。
同样,计算 < i m g 1 > <img1> <img1>中每个图像块的分数,然后得到质量图 M M M。针对低光照图像增强(LLIE)任务,对三个属性(“对比度”、“可见度”和“清晰度”)进行评估,并将平均全局分数和拼接后的质量图作为感知先验指导引入到后面提出的LLIE模型中。
2.3 基于感知先验的网络结构
Figure3是GPP-LLIE方法的整体框架。首先使用编码器ε将自然光照图像 I n l I_{nl} Inl和低光照图像 I l l I_{ll} Ill转换到隐空间,分别表示为 z n l 0 z_{nl}^{0} znl0和 z l l z_{ll} zll。然后,对 z n l 0 z_{nl}^{0} znl0应用正向扩散过程。为了利用先验信息来指导反向扩散过程,将 I l l I_{ll} Ill输入到本文提出的感知先验提取流程中。在全局感知分数S、局部质量图M和低光照特征 z l l z_{ll} zll的引导下,构建了一个基于Transformer的网络 ϵ θ \epsilon_{\theta} ϵθ,并逐渐将随机采样的高斯噪声 z ^ n l T \hat{z}_{nl}^{T} z^nlT转换为清晰的自然光照隐特征 z ^ n l 0 \hat{z}_{nl}^{0} z^nl0。最后,将恢复的特征 z ^ n l 0 \hat{z}_{nl}^{0} z^nl0输入到解码器D中,生成最终的增强图像 I ^ o u t \hat{I}_{out} I^out。
GPP-LLIE网络 ϵ θ \epsilon_{\theta} ϵθ如Figure3所示,有如下特点:
-
拼接与移除策略:在每个GPP-LLIE模块内,首先将低层级特征 z ℓ ℓ z_{\ell \ell} zℓℓ拼接到输入中,以便将低层级信息引入反向扩散过程,从而提高保真度。而在后半部分移除这个操作。为了达到保真度和质量的权衡。
-
全局感知先验引导层归一化(GPP-LN):为了将从视觉语言模型(VLMs)中导出的全局分数S有效地整合到GPP-LLIE模块中,需要对层归一化过程进行调制。这种调制由受S影响的缩放和平移参数 γ \gamma γ 和β 驱动,以更好地反映全局感知先验所提供的感知先验信息。给定输入特征 z i n z_{in } zin ,GPP-LN通过以下公式计算: z o u t = γ ⋅ L N ( z i n ) + β z_{out }=\gamma \cdot LN(z_{in })+\beta zout=γ⋅LN(zin)+β ,其中 γ \gamma γ 、 β = M L P ( S ) \beta = MLP(S) β=MLP(S) 。
-
局部感知先验引导注意力(LPP-Attn):为降低空间自注意力机制带来的巨大计算成本,在GPP-LLIE模块中沿通道维度计算注意力图。此外,除了多头自注意力(MSA),还设计了另一种由局部质量图M引导的通道注意力机制。
具体来说,查询元素基于输入特征计算,而键(key)和值(value)元素的计算则由局部感知先验M引导。
三、实验结果
1.定量实验
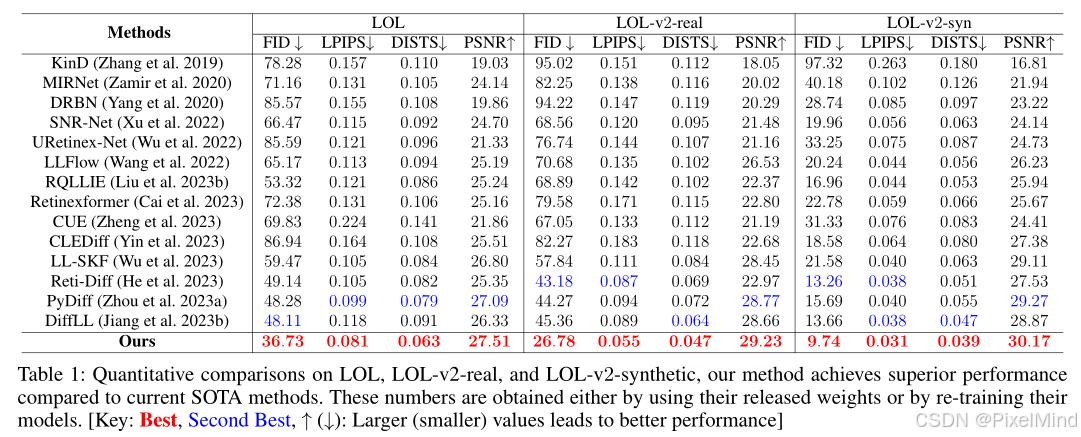
表1总结了该方法与当前最先进方法之间的定量比较。在3个常用基准测试中取得了卓越的性能,凸显了其先进性和出色的泛化能力。值得注意的是,在LOL、LOL-v2-real和LOL-v2-syn 上,该方法的FID分数比最先进方法中的最佳分数分别高出23.6%、37.4%和26.5%。
此外,LPIPS值比PyDiff高出18.4%,显著优于它。这些数据表明本文增强方法在感知质量上的优越性,并证明了生成感知先验的有效性。
2.定性实验

成对数据集的定性结果。增强结果表明,本文方法能够生成具有宜人光照、正确颜色还原和增强纹理细节的图像。例如,第一行中盆栽植物丰富的结构细节,第二行中保存完好的木地板表面及其边缘轮廓,以及第三行中增强的嫩枝边缘。相比之下,以前的方法往往输出模糊的结果,缺乏丰富的纹理(第二行中的Retinexformer和PyDiff),并且难以保持颜色保真度和光照协调性(第一行中的LLFlow和RQ - LLIE)。
3.模型在真实世界数据集上性能
真实世界数据集上的性能。为了进一步验证该方法的泛化能力,将评估扩展到真实世界的低光照数据集。

如表2所示,此处采用了NIQE指标。可以看出,模型在前三组数据集上取得了最佳性能,在NPE数据集上取得了第二好的结果,从而在真实世界数据上显著优于其他方法。
3.消融实验

消融实验如上表所示,也说明了本文提出的基于视觉语言模型提供的先验的有效性;以及本文基于该先验设计的网络结构的有效性。
四、总结
本文提出了一种基于视觉语言大模型生成感知先验的低照度图像增强方法。传统图像增强(如降噪、超分辨率)多基于像素级算法,缺乏对图像内容的语义认知;而视觉语言大模型可通过理解图像语义信息,实现更符合人类认知的增强效果。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。
















 2977
2977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









