




一、构造张量
1. 一维张量
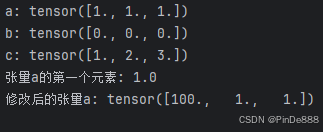
import torch
# 创建一个大小为3的一维张量,用1.0填充
a = torch.ones(3)
print("a: {}".format(a))
b = torch.zeros(3)
print("b: {}".format(b))
c = torch.tensor([1.0, 2.0, 3.0])
print("c: {}".format(c))
# 访问
print("张量a的第一个元素: {}".format(a[0]))
# 修改
a[0] = 100
print("修改后的张量a: {}".format(a))
输出结果:
2. 多维张量
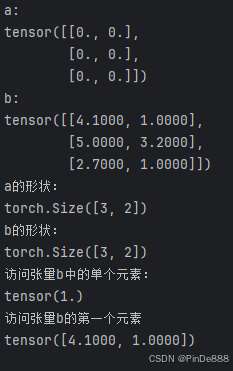
import torch
a = torch.zeros(3, 2)
print("a: ")
print(a)
b = torch.tensor([[4.1, 1.0], [5.0, 3.2], [2.7, 1.0]])
print("b: ")
print(b)
# 查看张量的形状
print("a的形状:")
print(a.shape)
print("b的形状:")
print(b.shape)
# 访问
# 张量b中的单个元素
print("访问张量b中的单个元素:")
print(b[0, 1])
# 张量b的第1个元素
print("访问张量b的第一个元素")
print(b[0])
输出结果:
二、索引张量
import torch
a = torch.tensor([[0, 1, 2], [1, 2, 3]])
print("第1行之后所有的行,隐含所有列:")
print(a[1:])
print("第1行之后所有的行,所有列:")
print(a[1:, :])
print("第1行之后的所有行,第1列:")
print(a[1:, 0])
print("增加大小为1的维度:")
print(a[None])

三、张量的元素类型
- 使用标准python数字类型可能不是最优的,原因如下:
(1)python中的数字是对象,如果存储数百万的数据会非常低效。
(2)python中的列表属于对象的顺序集合,没有为有效地获取两个向量的点积或将向量求和而定义的操作。python列表无法优化其内容在内存中的排列,因为它们是指向python对象的指针的可索引集合,这些对象可能是任何数据类型而不仅仅是数字。最优python列表是一维的,尽管我们可创建列表的列表,这同样非常低效。
(3)python解释器与优化后的已编译的代码相比速度很慢。在大型数字类型的数据集合上执行数学运算,使用编译过的更低级语言(如C语言)编写的优化代码可以快很多。
鉴于这些原因,pytorch提供数字类型的数据的有效底层实现和相关操作,并将这些封装爱一个方便的高级API中。要实现这一点,张量内的对象必须都是相同类型的数字,pytorch必须跟踪这个数字类型。
- 使用dtype指定数字类型
import torch
double_a = torch.ones(10, 2, dtype=torch.double)
short_b = torch.tensor([[1, 2], [3, 4]]).short()
print(double_a.dtype)
print(short_b.dtype)
short_a = double_a.to(torch.short)
print(short_a.dtype)
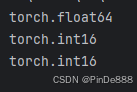
在底层,to()方法会检查转换是否是必要的,如果必要,则执行转换。
参考资料
[1] 

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









