



一、实验目的
编写python爬虫代码,获取豆瓣评分排名前50的经济学类书籍,包括书名、作者、出版日期、评分等信息。
二、实验方法
1. 获取url
url打开网页复制即可
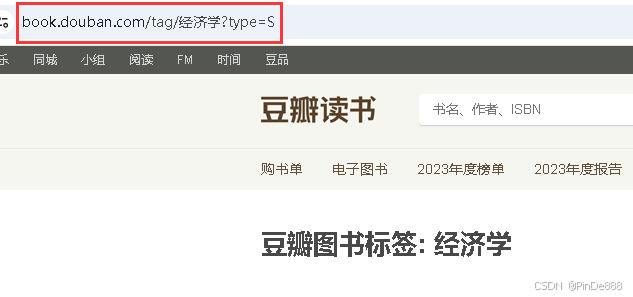
url = 'https://book.douban.com/tag/%E7%BB%8F%E6%B5%8E%E5%AD%A6?type=S'
# %E7%BB%8F%E6%B5%8E%E5%AD%A6为“经济学”三个中文汉字的URL编码
2. 获取user-agent
User-agent用于模拟浏览器的行为,避免被网站识别为爬虫,从而减少被封禁IP或限制访问频率的风险
按F12打开网页开发者工具,在Network--Headers下找到User-Agent,复制其内容
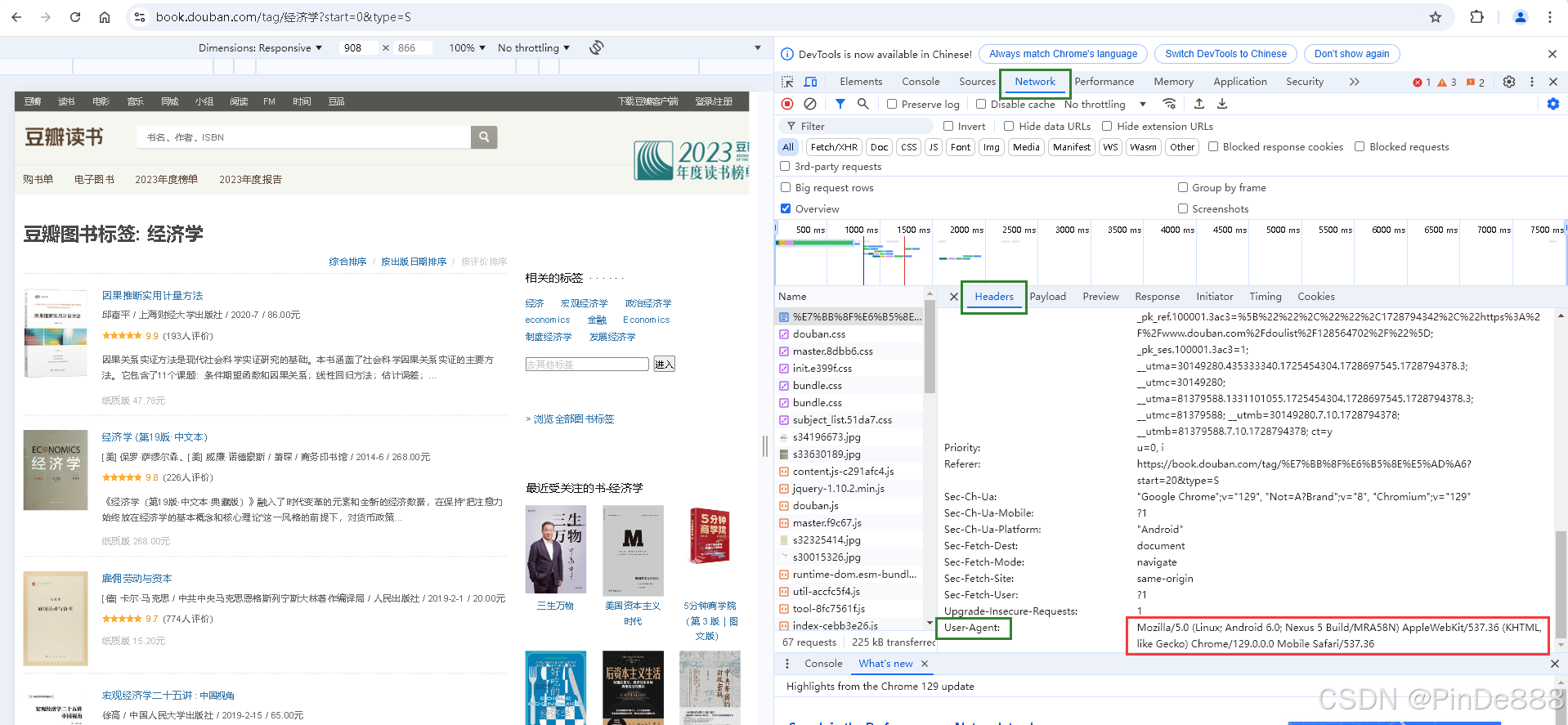
headers = { # 模拟浏览器行为
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Mobile Safari/537.36'
}
3. 找到目标信息与网页结构之间的关联 【关键步骤】
网页第一页仅显示20本书籍
点开第二页,发现url中出现start参数,并且随页数改变
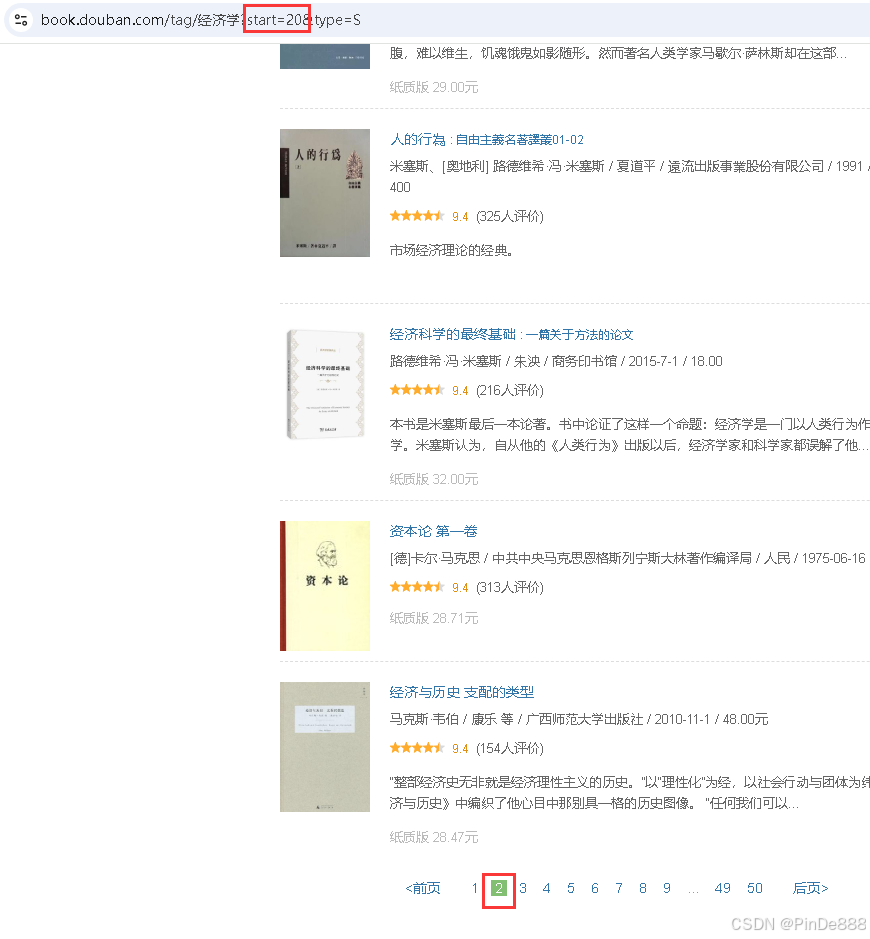
故可通过start参数构造循环语句,来获取第二页及以后的信息。
# 获取前五页的书籍内容
for i in range(0, 5):
url = 'https://book.douban.com/tag/%E7%BB%8F%E6%B5%8E%E5%AD%A6?start={}&type=S'.format(i*20)
4. 解析HTML文档,提取所需信息 【关键步骤】
打开网页源码,发现每本书籍的信息都分别储存在标签<li class="subject-item"><li>内

# 获取该页所有20本书籍的信息
# 注意class是Python关键词,后面要加下划线_
li_elements = soup.find_all('li', class_='subject-item')
for li in li_elements:
# 其中每一本书籍的信息
info = li.get_text()
三、实验结果
部分结果如下图
附、完整代码
import requests # 发送html请求
from bs4 import BeautifulSoup # 解析html文本
headers = { # 模拟浏览器行为
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Mobile Safari/537.36'
}
index = 1 # 书籍排名
for i in range(0, 5): # 获取前五页的书籍内容
url = 'https://book.douban.com/tag/%E7%BB%8F%E6%B5%8E%E5%AD%A6?start={}&type=S'.format(i*20)
response = requests.get(url=url, headers=headers)
# 获取HTML文本
soup = BeautifulSoup(response.text, 'html.parser')
# 解析HTML文本内容
# 获取该页面所有书籍信息
# 注意class是Python关键词,后面要加下划线_
li_elements = soup.find_all('li', class_='subject-item')
for li in li_elements:
# 其中一本书籍的信息
info = li.get_text()
# 输出爬虫结果
# 格式处理,去除所有换行符
info = info.replace("\n", "")
# 去除冒号前的空格
parts = info.split(':', 1)
if len(parts) > 1:
parts[0] = parts[0].rstrip()
print("No.{}: ".format(index) + ':'.join(parts))
index = index + 1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









