 yolov11车牌识别网页版系统搭建
yolov11车牌识别网页版系统搭建







源码:
「yolov11车牌识别网页版(HTML+Fastapi)」
链接:https://pan.quark.cn/s/ae85e6b776c0链接:https://pan.quark.cn/s/ae85e6b776c0
链接:https://pan.quark.cn/s/ae85e6b776c0
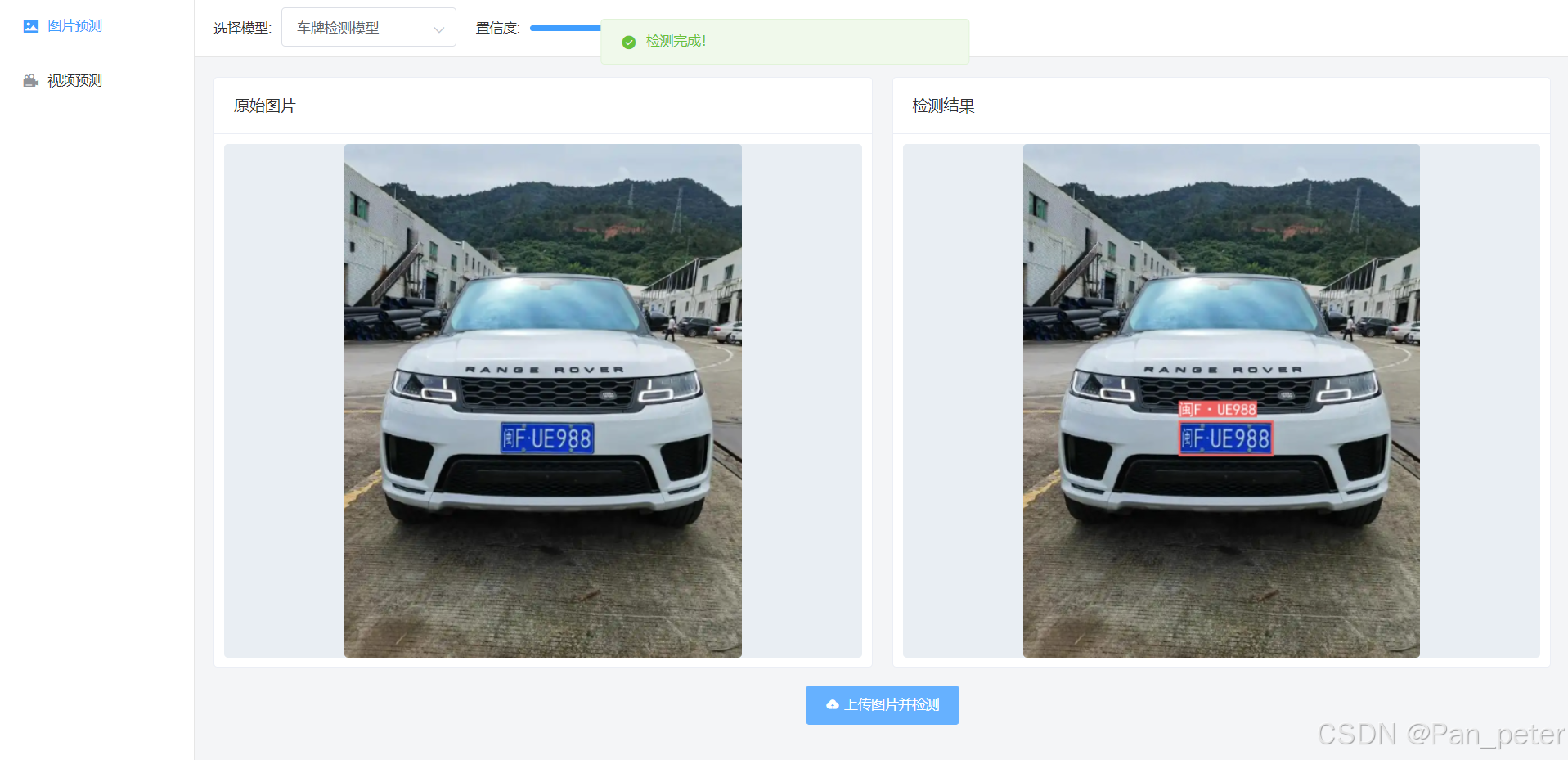
检测页面:
快速开始
1、双击打开【yolov11车牌识别网页.html】即可看见网页
2、安装Python3.9以上的解释器
3、下载Python的第三方库
pip install fastapi uvicorn ultralytics opencv-python-headless pillow numpy pydantic paddlepaddle paddleocr4、使用 "python main.py" 命令直接运行此服务
前端系统(Vue.js + Element-UI)
- 框架:Vue.js 2.x(响应式数据驱动)。
- UI 组件:Element-UI(提供菜单、按钮、滑块等组件)。
- 通信:WebSocket(实时传输视频帧与检测结果)。
- 工具:HTML5
<video>和<canvas>(视频播放与帧抓取)。
后端系统(FastAPI)
- 框架:FastAPI(高性能异步 Web 框架)。
- 模型:
- 目标检测:Ultralytics YOLOv8(
ultralytics库)。- OCR 识别:PaddleOCR(百度开源 OCR 库,支持中文车牌识别)。
- 工具:
- OpenCV(图像处理,如帧解码、图像标注)。
- Pydantic(数据校验与序列化)。
- Uvicorn(ASGI 服务器,用于部署 FastAPI 应用)。
系统演示
- 图片检测流程:
- 上传图片 → 选择模型 → 调整参数 → 点击检测 → 显示标注结果。
- 视频检测流程:
- 上传视频 → 点击开始检测 → 实时显示原始视频与检测帧 → 支持暂停 / 继续 / 停止。
总结
该项目是基于YOLOv11的车牌识别网页系统,包含前端(Vue.js+Element-UI)和后端(FastAPI)两大模块。前端采用WebSocket实现实时通信,使用HTML5视频和画布元素处理视频帧;后端整合了YOLOv8目标检测和PaddleOCR文字识别,通过OpenCV进行图像处理。系统支持图片和视频检测,提供参数调整功能,可实时显示检测结果。部署需Python3.9+环境及FastAPI等第三方库,运行main.py即可启动服务
YOLOv8 + PaddleOCR 是最优解,精度高、速度快。
CNOCR 在中文车牌识别上表现优秀,但速度稍慢。
EasyOCR 适合轻量级应用,但对模糊车牌适应性较差。
Tesseract OCR 适用于标准化文本,但车牌识别表现较差。
PaddleOCR>CNOCR>EasyOCR >Tesseract OCR



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











