+--------------------------------------------------------------------------------------------------------+
| npu-smi 25.0.rc1.1 Version: 25.0.rc1.1 |
+-------------------------------+-----------------+------------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) Hugepages-Usage(page) |
| Chip Device | Bus-Id | AICore(%) Memory-Usage(MB) |
+===============================+=================+======================================================+
| 2 310P3 | OK | NA 49 24 / 24 |
| 0 0 | 0000:01:00.0 | 0 1706 / 44216 |
+-------------------------------+-----------------+------------------------------------------------------+
| 2 310P3 | OK | NA 47 0 / 0 |
| 1 1 | 0000:01:00.0 | 0 1367 / 43757 |
+===============================+=================+======================================================+
| 3 310P3 | OK | NA 52 0 / 0 |
| 0 2 | 0000:03:00.0 | 0 1484 / 44216 |
+-------------------------------+-----------------+------------------------------------------------------+
| 3 310P3 | OK | NA 49 0 / 0 |
| 1 3 | 0000:03:00.0 | 0 1456 / 43757 |
+===============================+=================+======================================================+
| 5 310P3 | OK | NA 49 0 / 0 |
| 0 4 | 0000:81:00.0 | 0 1599 / 44216 |
+-------------------------------+-----------------+------------------------------------------------------+
| 5 310P3 | OK | NA 47 0 / 0 |
| 1 5 | 0000:81:00.0 | 0 1341 / 43757 |
+===============================+=================+======================================================+
| 6 310P3 | OK | NA 51 0 / 0 |
| 0 6 | 0000:83:00.0 | 0 1505 / 44216 |
+-------------------------------+-----------------+------------------------------------------------------+
| 6 310P3 | OK | NA 50 0 / 0 |
| 1 7 | 0000:83:00.0 | 0 1433 / 43757 |
+===============================+=================+======================================================+
+-------------------------------+-----------------+------------------------------------------------------+
| NPU Chip | Process id | Process name | Process memory(MB) |
+===============================+=================+======================================================+
| 2 0 | 2450404 | python | 98 |
| 2 0 | 2526327 | python | 99 |
| 2 0 | 2522713 | python | 98 |
+===============================+=================+======================================================+
| No running processes found in NPU 3 |
+===============================+=================+======================================================+
| No running processes found in NPU 5 |
+===============================+=================+======================================================+
| No running processes found in NPU 6 |
+===============================+=================+======================================================+
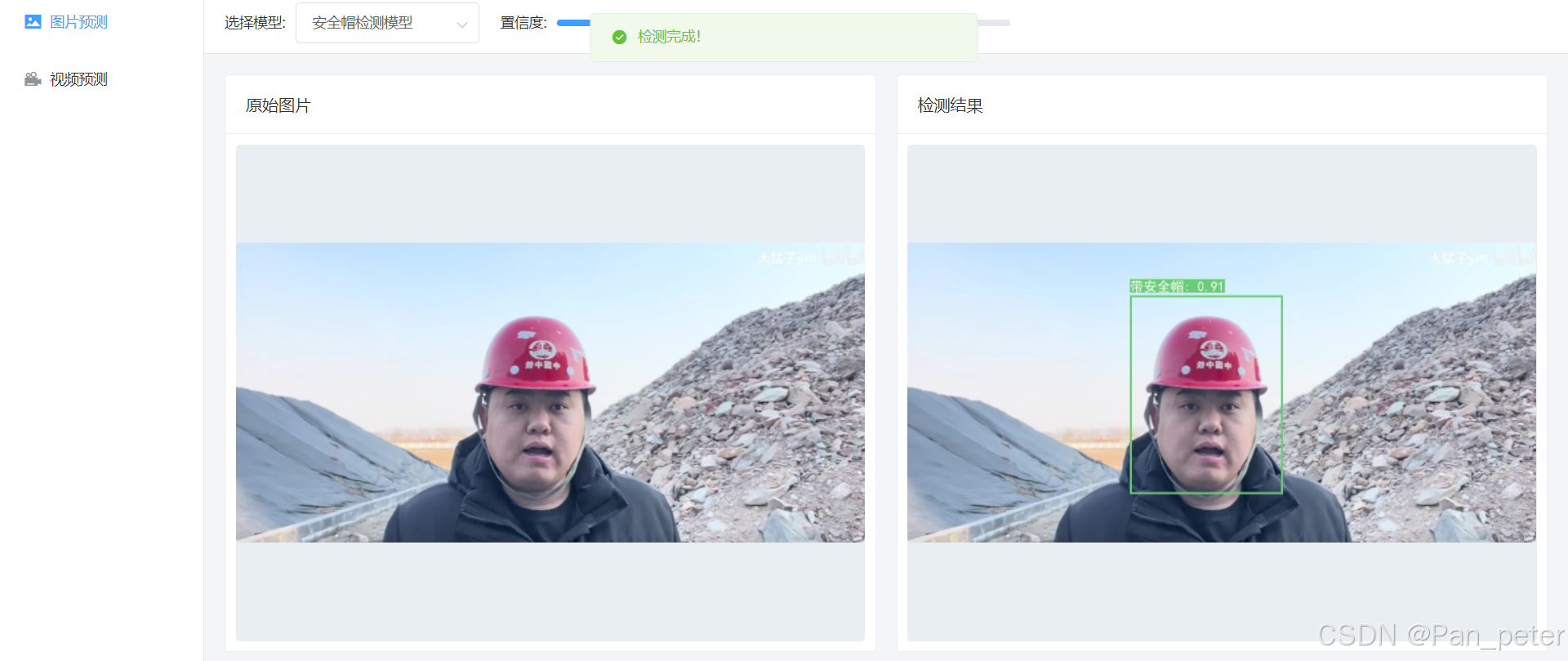
这是当前npu的使用状态,现在需要怎么办,代码中有错误吗,还是代码衔接问题
import os
import io
import cv2
import time
import logging
import numpy as np
from PIL import Image
from fastapi import FastAPI, File, UploadFile, Request
from fastapi.responses import JSONResponse
from fastapi.staticfiles import StaticFiles
from pydantic import BaseModel
from typing import Optional, List, Dict, Any
from datetime import datetime
# 华为昇腾推理API
import acl
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
app = FastAPI(title="Ascend-OM Object Detection API")
RESULT_DIR = 'results'
os.makedirs(RESULT_DIR, exist_ok=True)
app.mount("/gqj_check/img", StaticFiles(directory=RESULT_DIR), name="results")
CUSTOM_NAMES = {
"A_安全帽": "安全帽", "B_安全带": "安全带", "C_绝缘靴": "绝缘靴", "D_绝缘手套": "绝缘手套",
"E_验电器": "验电器", "F_工具包": "工具包", "G_钳子": "钳子", "H_力矩扳手": "力矩扳手",
"I_钢丝刷": "钢丝刷", "J_头灯": "头灯", "K_力矩头": "力矩头", "L_防护旗": "防护旗",
"M_扳手": "扳手", "N_螺丝刀": "螺丝刀", "O_脚扣": "脚扣", "P_水平尺": "水平尺", "Q_手锤子": "手锤子"
}
class ImageUrl(BaseModel):
image_url: str
class DetectionItem(BaseModel):
class_name: str
count: int
confidence: float
class ApiResponse(BaseModel):
code: int
msg: str
request_time: str
end_time: str
total_time: str
status: Optional[str]
data: List[DetectionItem]
inference_time: Optional[str]
image_url: Optional[str]
source_url: Optional[str]
# --------- 昇腾 NPU 推理相关 ---------
class AscendModel:
def __init__(self, om_path):
logger.info("初始化ACL环境...")
self.acl_init()
self.context, self.stream = None, None
self.model_id, self.model_desc = None, None
self.input_size = (960, 960) # 需与模型输入一致
self.input_data = None
self.output_data = None
logger.info("加载模型...")
self.load_model(om_path)
logger.info("模型加载完成")
def acl_init(self):
"""初始化ACL环境"""
ret = acl.init()
if ret != 0:
raise Exception(f"ACL初始化失败,错误码: {ret}")
def load_model(self, om_path):
"""加载OM模型并准备输入输出缓冲区"""
if not os.path.exists(om_path):
raise FileNotFoundError(f"模型文件不存在: {om_path}")
# 创建上下文和流
self.context = acl.rt.create_context(0)
self.stream = acl.rt.create_stream()
# 加载模型
self.model_id = acl.mdl.load_from_file(om_path)
self.model_desc = acl.mdl.create_desc(self.model_id)
# 准备输入输出缓冲区
self._prepare_buffers()
def _prepare_buffers(self):
"""准备模型输入输出缓冲区"""
# 获取输入描述
input_num = acl.mdl.get_num_inputs(self.model_desc)
input_desc = acl.mdl.get_input_desc(self.model_desc, 0)
input_size = acl.mdl.get_desc_size(input_desc)
self.input_data = acl.rt.malloc(input_size, acl.rt.mem_type_device)
# 获取输出描述
output_num = acl.mdl.get_num_outputs(self.model_desc)
self.output_data = []
for i in range(output_num):
output_desc = acl.mdl.get_output_desc(self.model_desc, i)
output_size = acl.mdl.get_desc_size(output_desc)
output_buf = acl.rt.malloc(output_size, acl.rt.mem_type_device)
self.output_data.append(output_buf)
def preprocess(self, image: Image.Image):
"""图像预处理"""
img = image.resize(self.input_size)
img = np.array(img)
if img.shape[2] == 4:
img = img[:, :, :3] # 去除alpha通道
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
img = img.astype(np.float32) / 255.0
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, 0)
return img
def infer(self, img_np: np.ndarray):
"""执行模型推理"""
logger.info("开始推理...")
start_time = time.time()
# 将数据拷贝到设备
img_flat = img_np.flatten()
acl.rt.memcpy(self.input_data, img_flat.nbytes,
acl.util.numpy_to_ptr(img_flat), img_flat.nbytes,
acl.rt.memcpy_host_to_device)
# 执行推理
inputs = [self.input_data]
outputs = self.output_data
ret = acl.mdl.execute(self.model_id, inputs, outputs)
if ret != 0:
raise Exception(f"推理执行失败,错误码: {ret}")
# 处理输出(根据实际模型输出格式调整)
# 这里假设输出是检测框数组 [class_id, conf, x1, y1, x2, y2]
output_buffer = outputs[0]
output_size = acl.mdl.get_desc_size(acl.mdl.get_output_desc(self.model_desc, 0))
host_output = np.zeros(output_size // 4, dtype=np.float32) # 假设是float32类型
acl.rt.memcpy(acl.util.numpy_to_ptr(host_output), output_size,
output_buffer, output_size, acl.rt.memcpy_device_to_host)
# 解析输出为检测框格式
dets = []
num_dets = int(host_output[0]) # 假设第一个元素是检测框数量
for i in range(num_dets):
base_idx = 1 + i * 6
if base_idx + 5 >= len(host_output):
break
class_id = int(host_output[base_idx])
conf = host_output[base_idx + 1]
x1, y1, x2, y2 = host_output[base_idx+2:base_idx+6]
dets.append([class_id, conf, x1, y1, x2, y2])
inference_time = time.time() - start_time
logger.info(f"推理完成,耗时: {inference_time:.3f}秒")
return dets
def __del__(self):
"""资源释放"""
logger.info("释放资源...")
if hasattr(self, 'model_id') and self.model_id:
acl.mdl.unload(self.model_id)
if hasattr(self, 'model_desc') and self.model_desc:
acl.mdl.destroy_desc(self.model_desc)
if hasattr(self, 'input_data') and self.input_data:
acl.rt.free(self.input_data)
if hasattr(self, 'output_data') and self.output_data:
for buf in self.output_data:
acl.rt.free(buf)
if hasattr(self, 'stream') and self.stream:
acl.rt.destroy_stream(self.stream)
if hasattr(self, 'context') and self.context:
acl.rt.destroy_context(self.context)
acl.finalize()
# --------- FastAPI 业务逻辑 ---------
model = None # 延迟初始化,通过命令行参数加载
def process_image(image: Image.Image, request_time: datetime, original_filename: Optional[str] = None):
"""处理图像并返回检测结果"""
timestamp = request_time.strftime("%Y%m%d_%H%M%S_%f")
# 生成文件名
if original_filename:
base_name = os.path.basename(original_filename)
name, ext = os.path.splitext(base_name)
original_filename = f"{name}_{timestamp}{ext}"
else:
original_filename = f"original_{timestamp}.jpg"
original_path = os.path.join(RESULT_DIR, original_filename)
result_filename = f"detection_{timestamp}.jpg"
result_path = os.path.join(RESULT_DIR, result_filename)
# 保存原图
image.save(original_path)
logger.info(f"原图保存至: {original_path}")
# 推理过程
logger.info("开始预处理和推理...")
start_inference_time = time.time()
img_np = model.preprocess(image)
results = model.infer(img_np)
end_inference_time = time.time()
inference_time = end_inference_time - start_inference_time
logger.info(f"推理耗时: {inference_time:.3f} 秒")
# 解析推理结果
class_counts = {}
detected_objects = []
opencv_image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
height, width = opencv_image.shape[:2]
for det in results:
class_id, conf, x1, y1, x2, y2 = det
# 过滤低置信度结果
if conf < 0.5:
continue
# 检查类别ID有效性
if 0 <= class_id < len(CUSTOM_NAMES):
class_name = list(CUSTOM_NAMES.values())[int(class_id)]
else:
class_name = f"未知类别({class_id})"
logger.warning(f"检测到未知类别ID: {class_id}")
# 更新计数
class_counts[class_name] = class_counts.get(class_name, 0) + 1
detected_objects.append({"class_name": class_name, "confidence": conf})
# 绘制检测框(确保坐标在有效范围内)
x1 = max(0, min(int(x1), width))
y1 = max(0, min(int(y1), height))
x2 = max(0, min(int(x2), width))
y2 = max(0, min(int(y2), height))
cv2.rectangle(opencv_image, (x1, y1), (x2, y2), (0,255,0), 2)
cv2.putText(opencv_image, f"{class_name}:{conf:.2f}",
(x1, max(10, y1-10)),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,255,0), 2)
# 保存结果图
cv2.imwrite(result_path, opencv_image)
logger.info(f"结果图保存至: {result_path}")
# 构建返回结果
detection_result = []
for class_name, count in class_counts.items():
class_detections = [d for d in detected_objects if d["class_name"] == class_name]
max_confidence = max([d["confidence"] for d in class_detections]) if class_detections else 0
detection_result.append({
"class_name": class_name, # 与DetectionItem保持一致
"count": count,
"confidence": round(max_confidence, 4)
})
return {
"detection_result": detection_result,
"inference_time": inference_time,
"original_path": original_path,
"result_path": result_path
}
@app.post("/gqj_check/localfile")
async def detect_objects(request: Request, file: UploadFile = File(...)):
request_time = datetime.now()
if model is None:
end_time = datetime.now()
return JSONResponse(
content={"code": 500, "msg": "模型未加载", "request_time": str(request_time),
"end_time": str(end_time), "total_time": "0", "data": []},
status_code=500
)
try:
contents = await file.read()
image = Image.open(io.BytesIO(contents))
result = process_image(image, request_time, file.filename)
end_time = datetime.now()
base_url = str(request.base_url)
result_filename = os.path.basename(result["result_path"])
debug_image_url = f"{base_url}gqj_check/img/{result_filename}"
response_data = {
"code": 200,
"msg": "成功",
"request_time": str(request_time),
"end_time": str(end_time),
"total_time": f"{(end_time-request_time).total_seconds():.3f}秒",
"status": "success",
"data": result["detection_result"],
"inference_time": f"{result['inference_time']:.3f}", # 与模型保持一致
"debug_image_url": debug_image_url
}
logger.info("检测完成,返回结果")
return JSONResponse(content=response_data)
except Exception as e:
end_time = datetime.now()
logger.error(f"检测异常: {str(e)}", exc_info=True)
return JSONResponse(
content={"code": 500, "msg": str(e), "request_time": str(request_time),
"end_time": str(end_time), "total_time": "0", "data": []},
status_code=500
)
if __name__ == "__main__":
import argparse
import uvicorn
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', type=str, required=True, help='OM模型路径')
parser.add_argument('--port', type=int, default=8000)
parser.add_argument('--input_size', type=int, nargs=2, default=(960, 960), help='模型输入尺寸')
args = parser.parse_args()
logger.info(f"正在加载模型: {args.model_path},服务端口: {args.port}")
model = AscendModel(args.model_path)
model.input_size = tuple(args.input_size) # 设置输入尺寸
logger.info(f"模型加载完成,输入尺寸: {model.input_size},服务启动中...")
uvicorn.run(app, host="0.0.0.0", port=args.port)


























 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











