






源码:
「yolov11检测网页版1.0(HTML+Fastapi+sqlite)」
链接:https://pan.quark.cn/s/4569ef78d186链接:https://pan.quark.cn/s/4569ef78d186
链接:https://pan.quark.cn/s/4569ef78d186
功能:
1、实现图片预测
2、实现视频预测
-----------------------------------
3、可以查看预测记录(图片和视频)
数据库是使用的sqlite,不需要配置任何关于数据库的东西
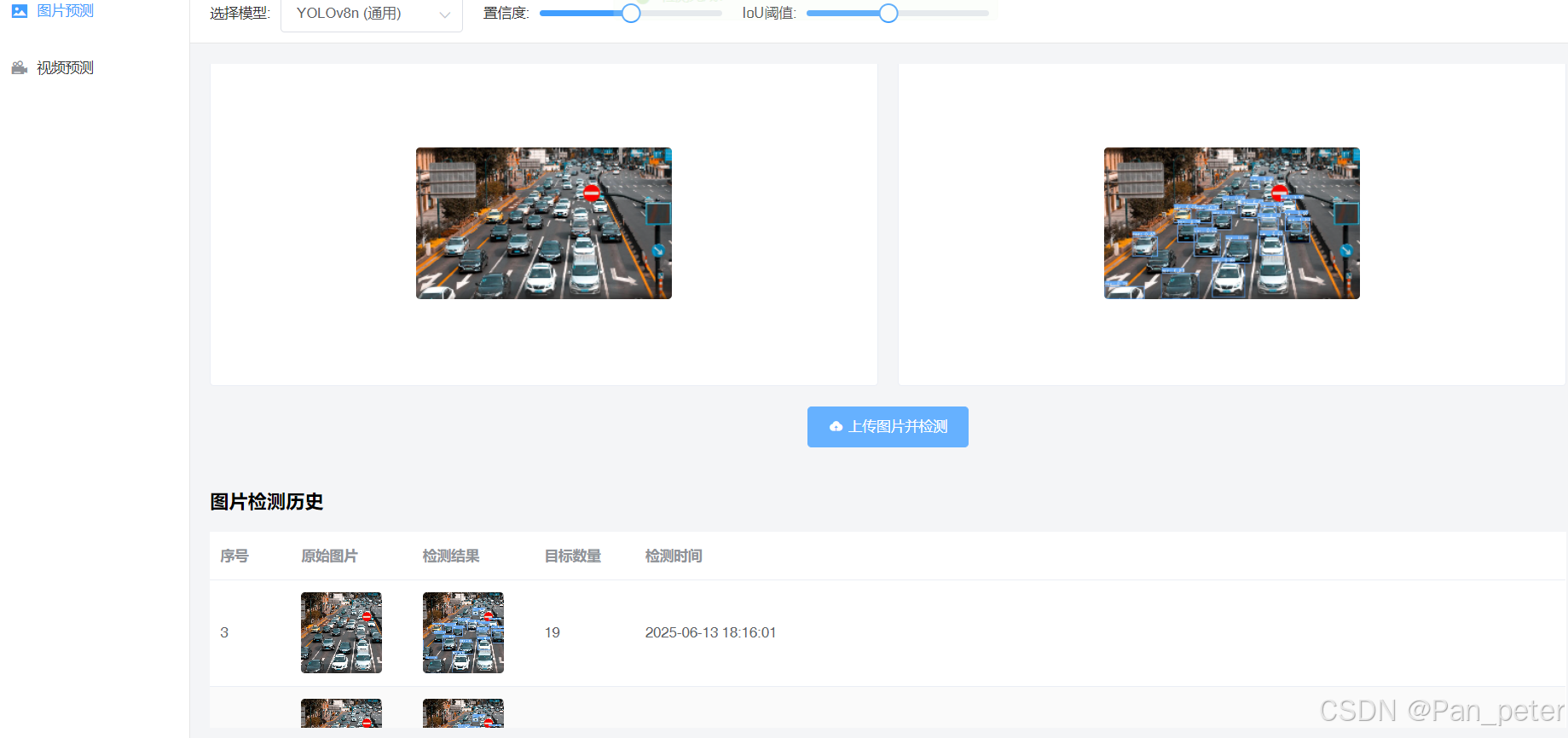
图片预测
点击表格里面的图片,会可以放大查看图片
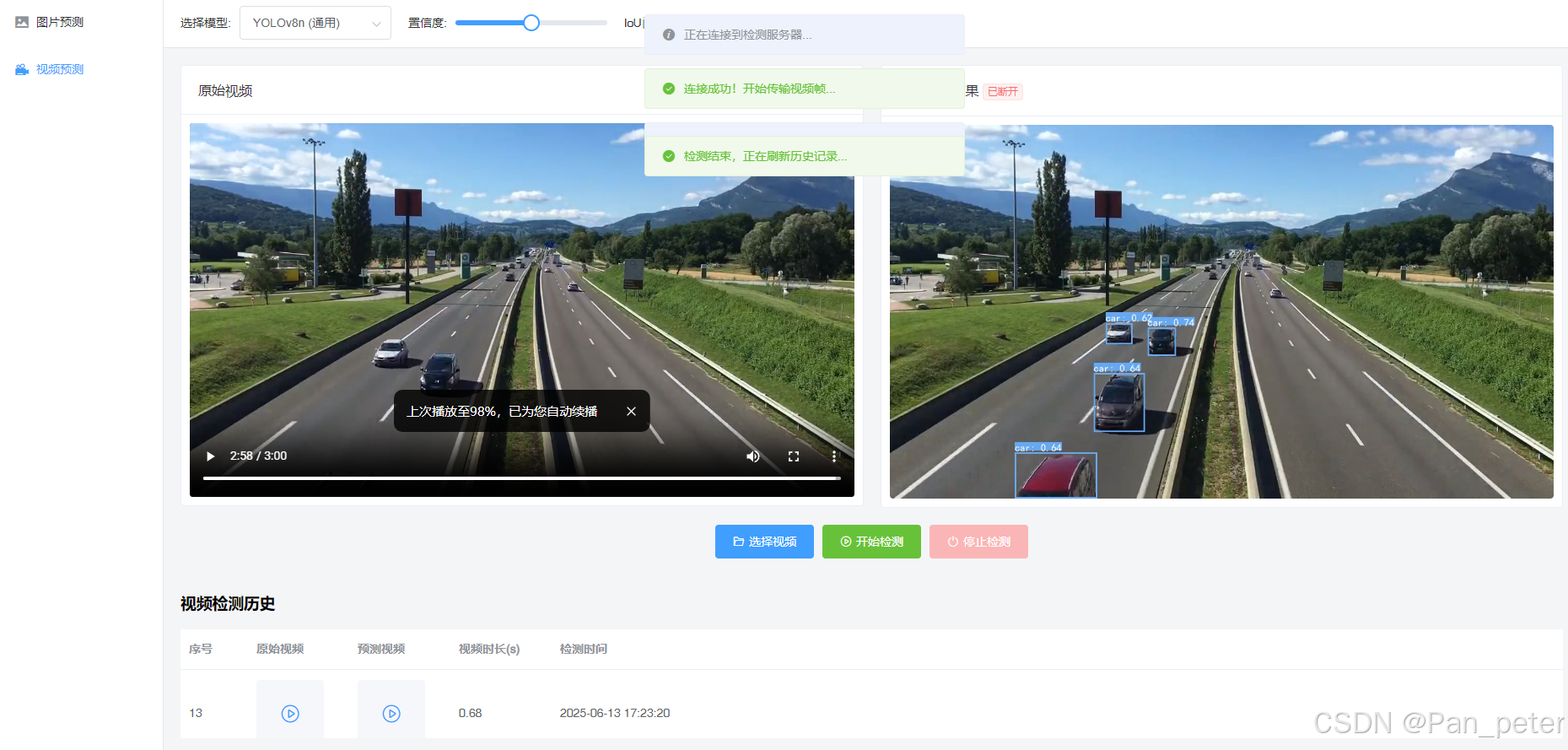
视频预测
查看结果(点击表格里面的视频):

数据库是使用的sqlite,不需要配置任何关于数据库的东西
有很多小伙伴因为学校作业,需要搞yolo,还有很多零基础的,甚至不是计算机专业的
这对于他们来说很折磨
这里就提供了最简单的方法,直接HTML网页+Fastapi后端
1、网页打开即可使用
2、后端只需要有对应Python解释器和第三方库即可运行
网页打开即可使用(双击:yolov11网页.html)
后端如何启动?
1、Python环境 (3.9以上)2、安装第三方库
pip install fastapi uvicorn ultralytics opencv-python-headless pillow numpy pydantic python-multipart python-dotenv3、运行main.py

project/ │ ├── main.py # 后端主程序(FastAPI 应用) ├── models/ # 模型存储目录 │ └── yolov8n.pt # YOLOv8n 通用模型(示例) │ ├── static/ # 静态资源目录 │ ├── before_img/ # 原始图片存储 │ ├── after_img/ # 标注图片存储 │ ├── before_video/ # 原始视频存储 │ └── after_video/ # 标注视频存储 │ ├── detect_image_history.db # 检测历史数据库 └── simhei.ttf # 中文字体文件(用于标注文字显示)
快速启动
- 下载项目代码:https://pan.quark.cn/s/4569ef78d186
- 安装后端依赖:
pip install -r requirements.txt- 准备模型文件:将 YOLO 模型(.pt 格式)放入
models/目录- 准备字体文件:将中文字体(如 simhei.ttf)放入项目根目录
- 启动后端服务:
python main.py- 前端直接打开
index.html文件(需确保后端服务已启动)
环境要求
- 后端:
- Python 3.8+
- CUDA(可选,GPU 加速)
- 依赖包:
fastapi uvicorn ultralytics paddleocr opencv-python numpy pillow sqlite3- 前端:
- 现代浏览器(Chrome/Firefox/Edge 等,支持 WebSocket 与 Canvas)
视频检测流程
- 用户选择视频文件,前端通过 Video 标签加载
- 用户点击 "开始检测",前端建立 WebSocket 连接
- 前端定时从视频中提取帧,转换为 Base64 发送到后端
- 后端接收帧数据,进行 YOLO+OCR 检测,返回标注帧
- 前端接收标注帧并显示,形成实时检测效果
- 检测完成后,后端将原始视频与标注视频保存,记录到数据库
图片检测流程
- 用户上传图片 -> 前端将图片转换为 Base64 格式
- 后端接收图片数据,加载对应 YOLO 模型进行检测
- 对检测到的目标(如车牌)进行 PaddleOCR 文字识别
- 在原图上绘制检测框与识别结果,生成标注图片
- 保存原始图片与标注图片到本地,记录到数据库
- 返回标注图片 Base64 数据到前端显示
前端技术栈
- 框架:Vue.js 2.0
- UI 组件:Element UI(响应式界面组件库)
- 多媒体处理:Canvas(图片渲染)、Video(视频播放与帧提取)
- 通信:WebSocket(与后端实时交互)
- 文件处理:FileReader(图片 / 视频文件解析)
后端技术栈
- 框架:FastAPI(高性能 Web 框架)
- 深度学习:
- YOLOv8(Ultralytics 实现)用于目标检测
- 数据库:SQLite(本地存储检测历史记录)
- 视频处理:OpenCV(帧提取与图像处理)
- 实时通信:WebSocket(视频帧传输与实时检测结果返回)


















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











