






 文章介绍了如何利用YOLOv8和LPRNet进行车牌检测与识别的Python项目,结合了GitHub上的开源代码,强调了项目对Python版本的要求(需3.8及以上),并提供了下载项目包的链接。文章还提到了项目的运行步骤,包括库的安装、配置修改和路径设置,并给出了参考视频链接,展示项目效果。该项目具有高识别速度和准确性。
文章介绍了如何利用YOLOv8和LPRNet进行车牌检测与识别的Python项目,结合了GitHub上的开源代码,强调了项目对Python版本的要求(需3.8及以上),并提供了下载项目包的链接。文章还提到了项目的运行步骤,包括库的安装、配置修改和路径设置,并给出了参考视频链接,展示项目效果。该项目具有高识别速度和准确性。
目录
四、运行项目 (教程)
12月更新:
因为有兄弟想要流畅调用摄像头,我就用MTSP的项目改了一下。
更新项目:Python——yolov8识别车牌2.0-优快云博客
时间:2023年12月26日12:57:52
一、前言
YOLOv8+LPRNet车牌定位与识别
最近做了有一个车牌识别的小需求,今天完成了,在此记录和分享https://www.bilibili.com/video/BV1vk4y1E7MZ/
首先,我去了GitHub上面找开源项目,就找到了3个大佬的项目,于是融合一下就完成了
基于YOLOV8的车牌识别的项目参考项目:
- GitHub - mmastererliu/master_liuContribute to mmastererliu/master_liu development by creating an account on GitHub.https://github.com/mmastererliu/master_liu
- https://github.com/Jai-wei/YOLOv8-PySide6-GUIhttps://github.com/Jai-wei/YOLOv8-PySide6-GUI
- GitHub - MuhammadMoinFaisal/Automatic_Number_Plate_Detection_Recognition_YOLOv8: Automatic Number Plate Detection YOLOv8Automatic Number Plate Detection YOLOv8. Contribute to MuhammadMoinFaisal/Automatic_Number_Plate_Detection_Recognition_YOLOv8 development by creating an account on GitHub.https://github.com/MuhammadMoinFaisal/Automatic_Number_Plate_Detection_Recognition_YOLOv8
二 、完成效果

三、 项目包
YOLOv8-license-plate-recognize.zip - 蓝奏云文件大小:24.4 M|
注意Python版本!要3.8及以上!!!
注意Python版本!要3.8及以上!!!
注意Python版本!要3.8及以上!!!
python>=3.8
四、运行项目
4.1、下载库——ultralytics (记得换源)
# 安装对应版本的库 pip install ultralytics==8.0.48 pip install pyside6==6.4.2
4.2、更改配置(CPU & GPU)

4.3、更换路径
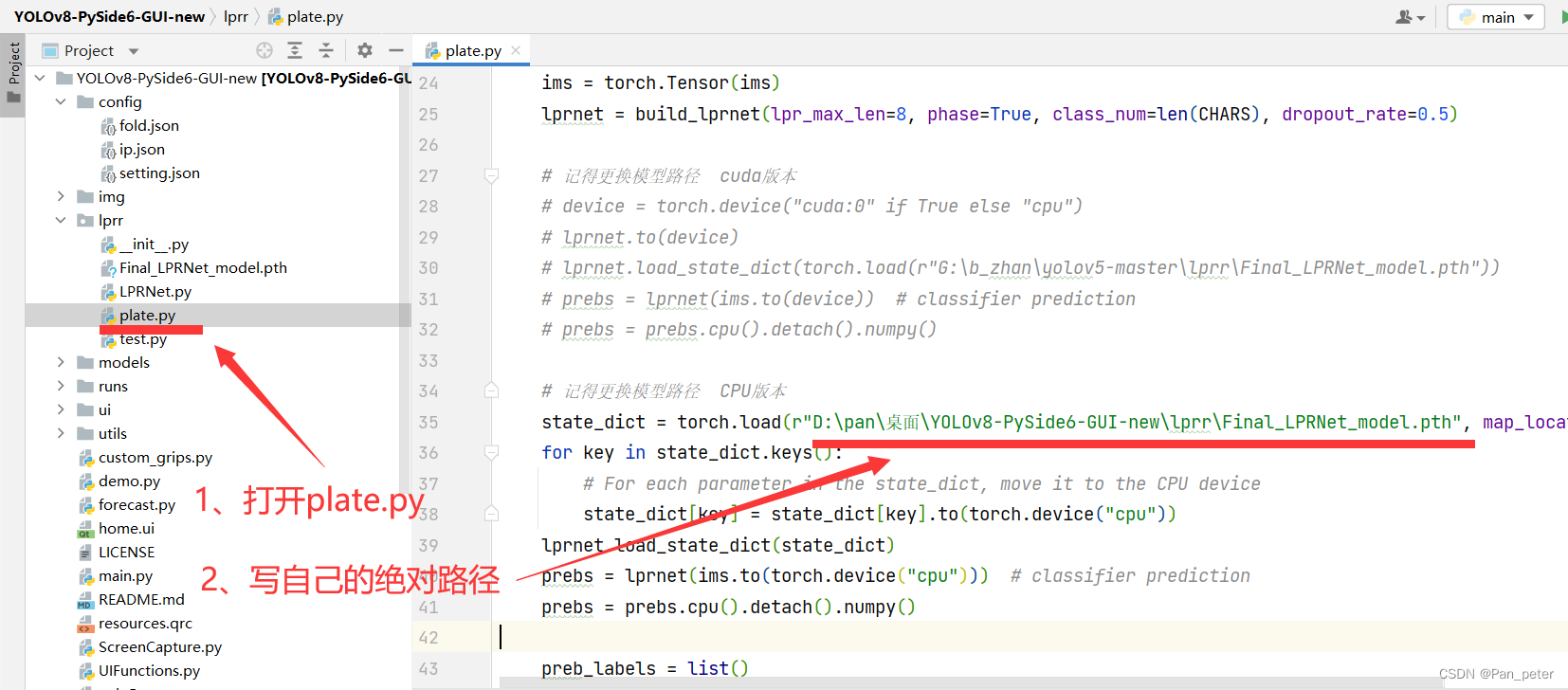
4.4、运行项目

5、参考视频
yolov5车牌号检测+识别_哔哩哔哩_bilibili继上期视频做的检测任务上做的识别,视频是一帧一帧做的检测,没有声音,由于数据集中部分场景不足,会造成对标识牌的误检。对较近的车牌效果还是可以的。如果喜欢或者对你有用,就给我github点个赞吧。代码已经开源:https://github.com/Buster-maker/plate,链接:https://pan.baidu.com/s/1ivZMy33mnPRaJWULt2-b5Q 提取码:6mn, 视频播放量 11802、弹幕量 2、点赞数 126、投硬币枚数 73、收藏人数 306、转发人数 88, 视频作者 Excelsior007, 作者简介 保持热爱,奔赴星海。,相关视频:YOLOv7+YOLOv5车辆识别+车辆测距+车辆测速+反应时间+防碰撞检测(原创作品),yolov5检测车牌号(后期加上识别),道路监控摄像头--YOLOv5算法实时检测过往车辆和车牌,YOLOv3+CRNN实现车牌检测与识别,yolov5+lprnet yolov5实现的是车牌检测 lprnet实现的是字符识别,效果还是说的过去的,基于YOLOv5+LPRNet进行车牌检测及识别,YOLOv5+LPRNet完成车牌定位与识别,基于pyqt5+yolov5+lprnet实现车牌检测和车牌识别系统,基于YOLOv5+LPRNet进行车牌检测及识别,数字图像处理大作业-车牌识别
项目介绍:
基于YOLOv8+LPRNet进行车牌检测及识别,包括对车辆的车牌区域精确定位,利用校正探测器对定位的车牌进行边框校正处理,使用增强神经网络模型对车牌区域进行超分辨率技术处理和光学字符识别。经过多次试验测试,可以对视频中的车辆车牌实时识别以及图片中的车辆车牌进行准确定位和识别,识别速度快,准确率高,比那些传统车牌识别方法效果好很多。
结语:
- 感谢大佬们的开源!
- 让本小白也可以完成这个小项目,先开始看见网上挺多付费的,自己也准备放弃了,用钱买
- 突然柳暗花明,看见了大佬们的开源项目,自己拿过来改改,就完成了!



















 7584
7584










 到【灌水乐园】发言
到【灌水乐园】发言









