



DeepSeek 作为国产开源大模型,一直因在线服务压力过大,导致很多时候问答交互麻烦服务器繁忙。本教程将手把手教你完成从环境配置到交互界面搭建的全流程,即使是零基础用户也能轻松掌握。
在本地部署的优势:
- 隐私性高:数据都在本地运行,无需上传到云端,避免数据泄露风险。
- 稳定性强:不受网络波动影响,模型运行更加稳定。
- 可定制性强:可以根据需求调整模型参数,满足个性化需求。
第一步 安装Ollama框架
去 Ollama官网

选择你对应的版本下载。下载完成后双击运行安装包,下一步下一步即可。
第二步 验证安装是否成功
在终端里面输入:
ollama -v输出类似于这样的(版本号可能不一样),就代表你安装成功了!
![]()
第三步 拉取LLM大模型
我们回到官网,去到模型这里。

你能看到很多LLM大模型,这里我们选择 deepseek - r1。
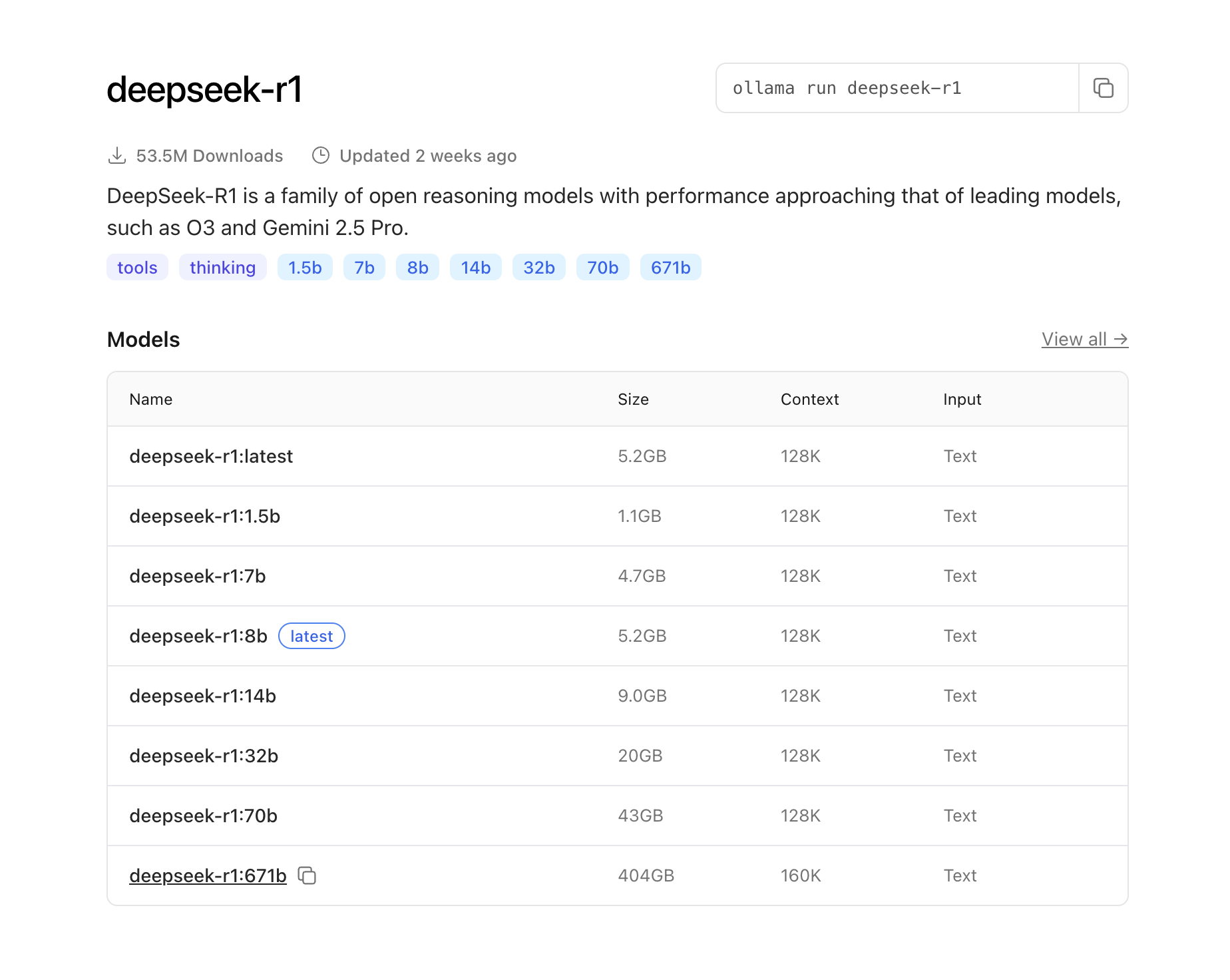
DeepSeek-R1 模型对比表
| 模型名称 | 参数量(估算) | 文件大小 | 上下文长度 | 推荐硬件配置 | 适合场景 | 是否适合本地运行 |
|---|---|---|---|---|---|---|
| deepseek-r1:1.5b | 1.5B | 1.1GB | 128K | CPU / 轻量设备 | 聊天机器人、轻任务、边缘应用 | ✅ 非常适合(轻量) |
| deepseek-r1:7b | 7B | 4.7GB | 128K | M1/M2/M3 / GPU ≥8GB | 通用问答、摘要、低负载编程任务 | ✅ 适合多数现代笔记本 |
| deepseek-r1:8b | ≈8B | 5.2GB | 128K | GPU 推荐 | 类似 7B,用于精度稍优版本 | ✅ 可替代 7B |
| deepseek-r1:14b | 14B | 9.0GB | 128K | GPU ≥12GB 显存 | 中大型问答、分析、初级代码生成 | ⚠️ 需中高端显卡 |
| deepseek-r1:32b | 32B | 20GB | 128K | GPU ≥24GB 显存 | 高性能生成任务、复杂指令跟随 | ⚠️ 仅推荐高端本地或远程部署 |
| deepseek-r1:70b | 70B | 43GB | 128K | 多GPU / A100/H100 | 接近 GPT-4 级别能力,科研、精细生成 | ❌ 不适合个人本地 |
| deepseek-r1:671b | 671B | 404GB | 160K | 超级计算集群 | LLM-as-agent、长文写作、规划与策略任务 | ❌ 只能云端部署,演示用 |
本地运行建议
| 设备类型 | 推荐版本 |
|---|---|
| 无 GPU,普通笔记本 | ✅ deepseek-r1:1.5b |
| MacBook M1/M2/M3 | ✅ deepseek-r1:7b or 8b |
| 中端显卡(如 3060/4060) | ✅ deepseek-r1:7b or 14b |
| 高端显卡(3090/4090) | ✅ deepseek-r1:32b |
| 没有限制,服务器/云平台 | ✅ deepseek-r1:70b 或 671b |
根据你本地电脑的配置选择合适的参数,例如我们选择 7b这个参数,运行代码如下:
ollama run deepseek-r1:7b

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









