




在《管理世界》2025年第6期发表的《在模型误设的统一框架下理解双重差分方法的最新发展》指出,安格里斯特经验主义范式下,双重差分法(DID)的 TWFE 回归三类推广(二元交错、非二元处理、协变量添加)存在模型误设,致负权重问题,无法估计异质性处理效应凸组合。本文构建统一框架,揭示误设根源,提出稳健估计方法,为中国经济研究中 DID 规范应用提供理论与实操指南。
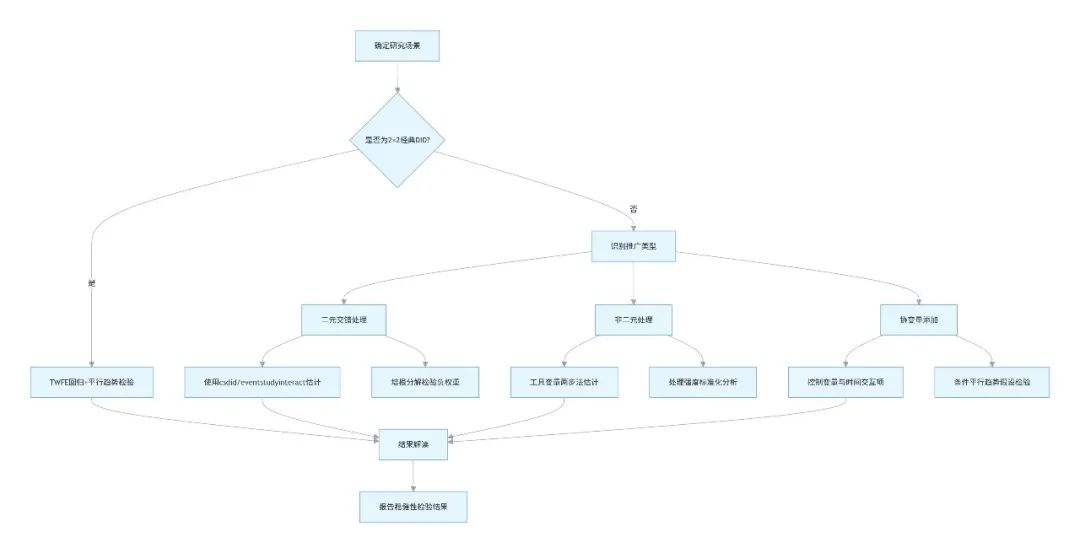
一、数据预处理与模型选择
1、样本筛选
手工核查处理时间(如政策文件 / 年报文本),排除金融行业、数据缺失样本;
对连续变量进行 1%~99% 缩尾处理,避免异常值影响。
2、模型类型判断
经典 2×2 DID:处理组与控制组、处理前后两期明确(如政策试点 vs 非试点);
广义 DID:满足以下任一条件:
处理时点交错(如分阶段政策推广)—— 推广 1;
处理强度非二元(如政策力度差异)—— 推广 2;
需控制其他政策或协变量—— 推广 3。
二、基础回归与误设诊断
1、经典 DID 回归
reghdfe Y i.treat#i.post, a(id year) cluster(id) // 双向固定效应
若满足平行趋势假设,系数\(\beta\)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









