



安装软件的一些选择
在原始环境下折腾下OpenStereo,常理应该安装conda/miniconda/anaconda/venv,然后利用这些软件进行虚拟环境的创建,这样可以更好的解决各种安装包的版本问题。由于目前是个人折腾,直接选择一个新方式玩玩,不装conda,用pip强行安装对应的包,遇到问题再尝试解决。
新的改变
1)先安装pip. apt install pip
2)安装git. apt install git
3)下载OpenStereo,正常应该是普通github就行。由于国内众所周知的原因,不妨用下某些镜像,git clone https://kkgithub.com/XiandaGuo/OpenStereo.git
因为某位大佬说已经有折腾好的版本,所以直接用他的就算了。
此处大佬一顿操作猛如虎,没法全部记下了,唯有以后慢慢折腾。
记一下几个命令吧:a)创建目录和子目录:mkdir kitti/2015 -p
b)解压zip文件:unzip data_scene_flow.zip
c)产生ssh密码(和本文无关):ssh-keygen
d)查看文件目录结构:tree
4)根据requirements.txt利用pip3逐个安装对应的库,没安装好一个就运行一下这个看哪里报错python3 tools/eval.py --cfg_file cfgs/igev/igev_sceneflow_amp.yaml --eval_data_cfg_file cfgs/sceneflow_eval.yaml --pretrained_model …/OpenStereo_checkpoint/IGEV_Sceneflow_Amp.pt
。这里需要注意:
a)用pip直接安装会报错,需要根据报错创建虚拟环境或者强行关闭该错误(选强行关闭)。
b)ubuntu设置的镜像和pip的镜像不是同一个,所以需要额外指定镜像源或者配置一个pip.conf放在/etc里面(选配置pip.conf)。
b1)pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
b2)etc/pip.conf里面的内容
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn
c)安装pytorch,之前就应该做这一步,最好看看官网,选了这个版本,目前可用。

pip3 install torch torchvision torchaudio
后续需要的库在requirement.txt里面都有
d)pip3 install easydict
e)pip3 install tensorboard
f)pip3 install matplotlib
g)pip3 install torchsummary
h)pip3 install torchview
i)pip3 install graphviz
j)pip3 install h5py
k)pip3 install timm
l)pip3 install scipy
5)回到有README.md文件的目录,修改里面的OpenStereo.sh并运行./OpenStereo.sh
#! /usr/bin/env bash
MODEL=OpenStereo
mkdir -p ${MODEL}_datasets
#=========================== Datasets
lnif() {
ln -sfT “$1” "KaTeX parse error: Expected 'EOF', got '}' at position 4: 2" }̲ lnif ../../dat…{MODEL}_datasets/Middlebury
lnif …/…/datasets/kitti/2015 ./KaTeX parse error: Expected 'EOF', got '#' at position 26: …tasets/KITTI15 #̲===============…{MODEL}_checkpoint
mkdir -p ${HOME}/.cache/torch/hub/checkpoints
lnif $HOME/ProjectStereo/checkpoint/OpenStereo/mobilenetv2_100_ra-b33bc2c4.pth ${HOME}/.cache/torch/hub/checkpoints/mobilenetv2_100_ra-b33bc2c4.pth
6)运行python3 tools/eval.py --cfg_file cfgs/lightstereo/lightstereo_s_kitti.yaml --eval_data_cfg_file cfgs/kitti15_eval.yaml --pretrained_model …/OpenStereo_checkpoint/LightStereo-S-KITTI.ckpt
此处需要注意的是checkpoint文件mobilenetv2_100_ra-b33bc2c4.pth需要放置好,创建链接的路径要对。
7)此处开始碰到关于timm版本的问题(当前1.0.11,用pip list可以看到)a)首先是某个版本之后会出现优先网上下载pth,由于没有科学上网没法下载,需要在stereo/modeling/models/lightstereo/路径下的backbone.py里面增加pretrained_cfg_overlay=dict(file=‘/filetopath/mobilenetv2_100_ra-b33bc2c4.pth’)
b)常规操作是安装作者推荐的0.4.12或者某些其他0.5.4之类的,简单来讲就是库的接口不同了,低版本的时候有act1操作。网上找了一轮,包括查看huggingface的文档也没看出什么,索性强行改掉得了。
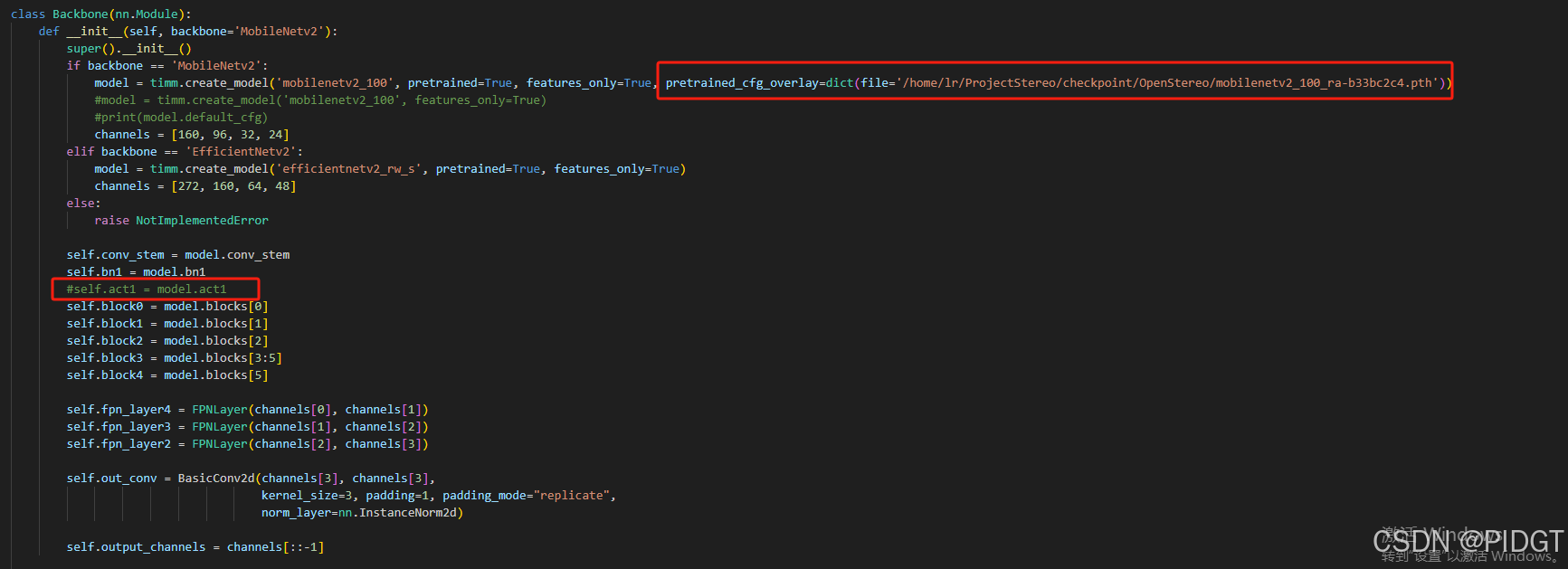
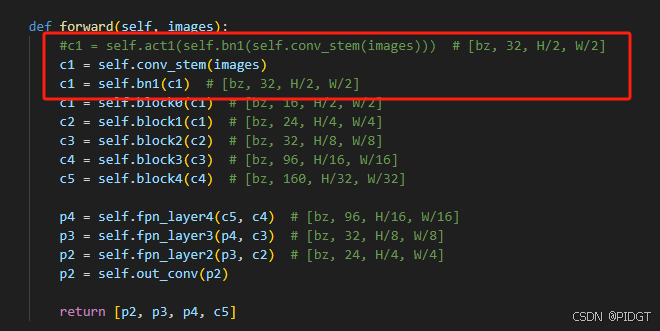
这样改完就能运行了,但还是会有warning unexpected keys的问题,没用到bn2和conv_head等,只能以后看到问题再改了。
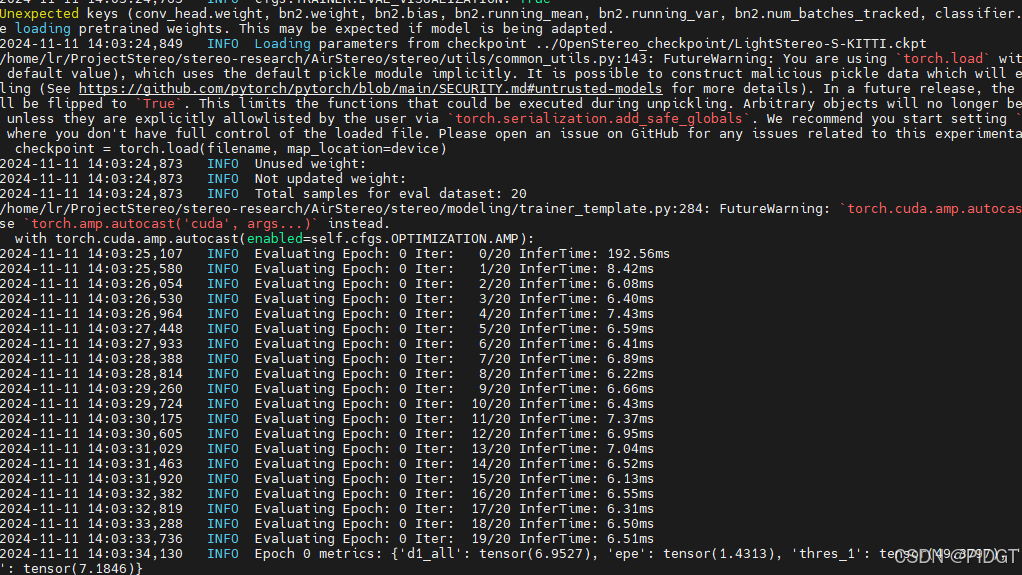
output文件夹里面会有
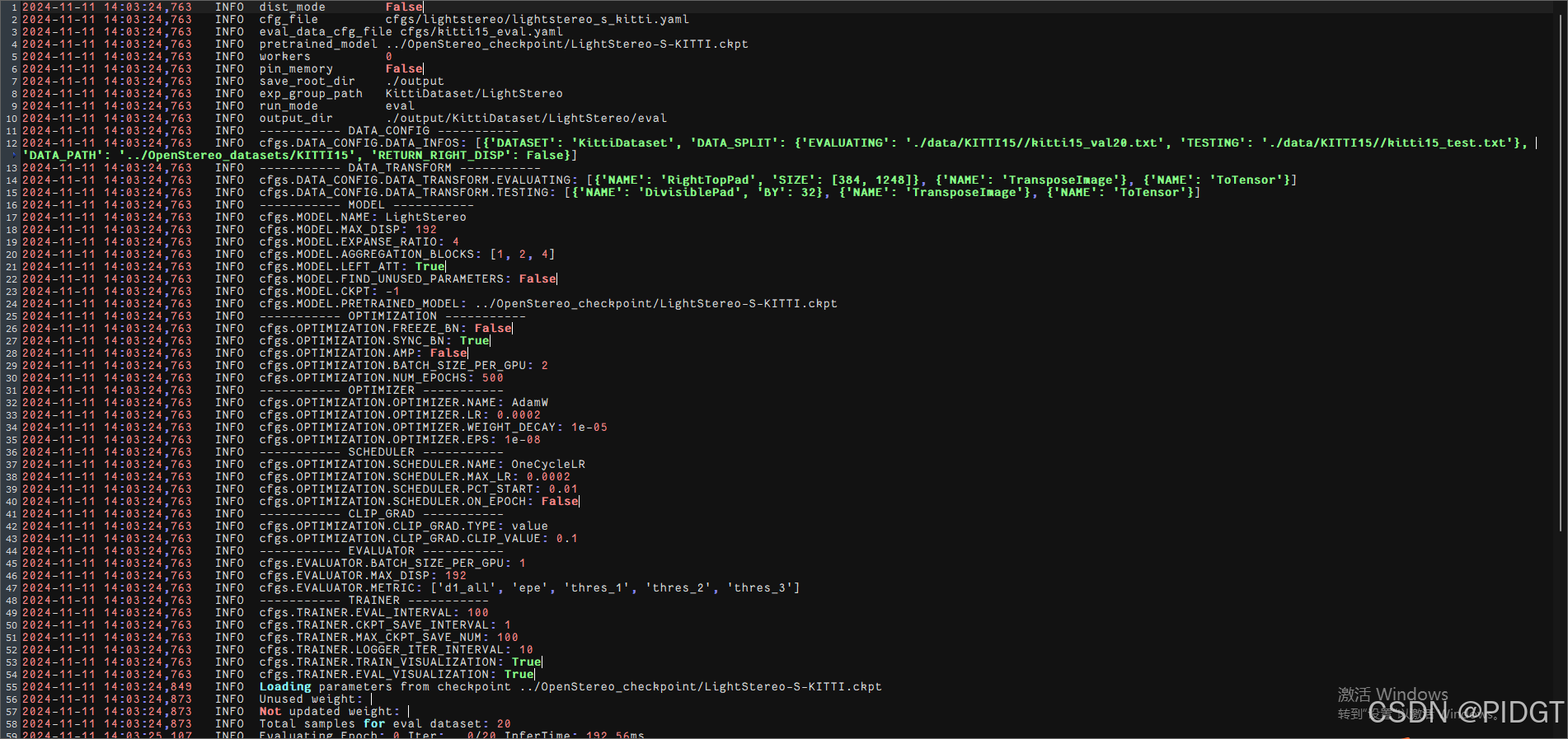
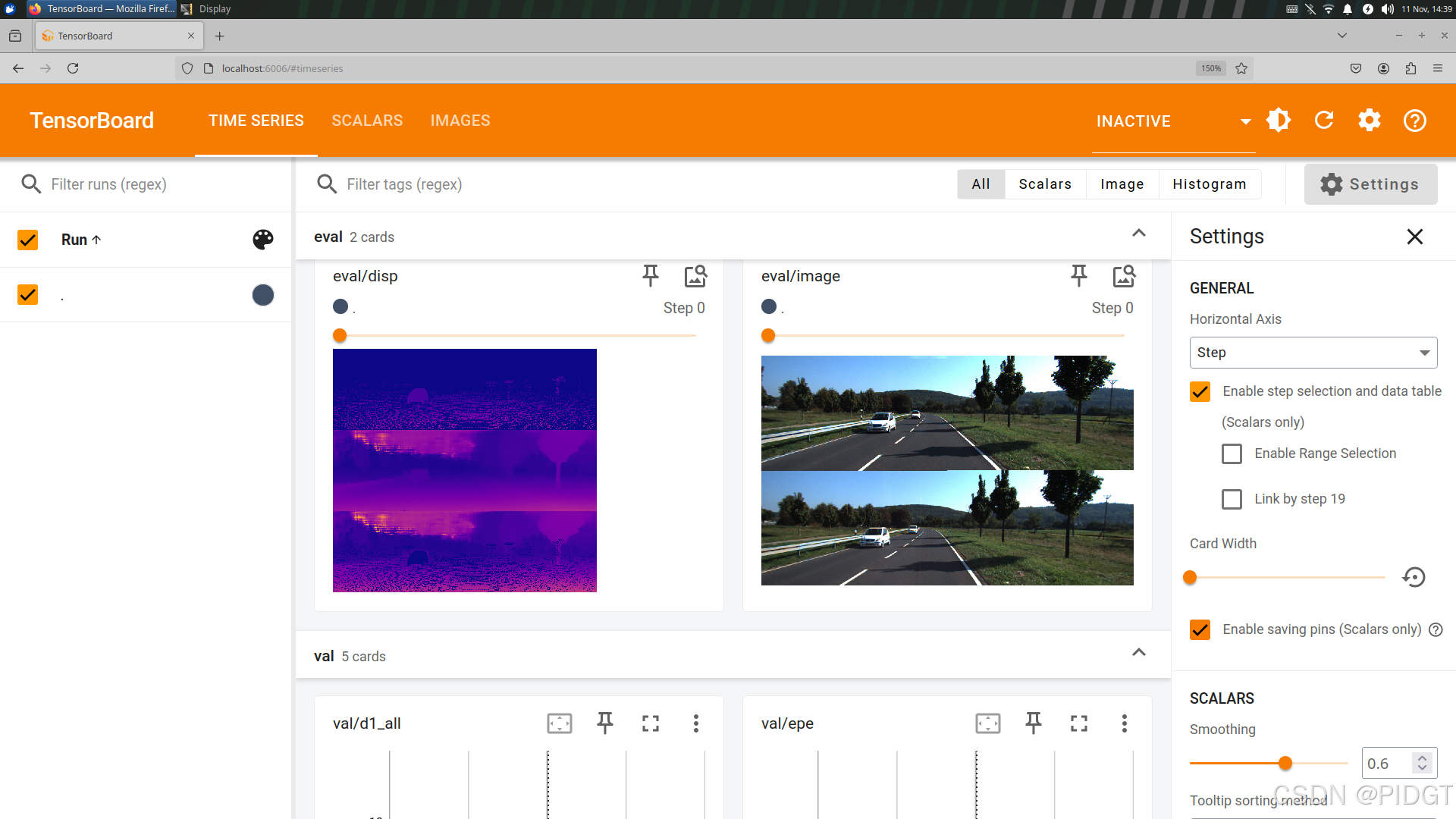
8)使用tensorboard查看,先运行命令
tensorboard --logdir=./output/KittiDataset/LightStereo/eval/eval_tensorboard/ --samples_per_plugin=images=1000
它会提示http://localhost:6006/,登录浏览器可以看到
9)补充一下查看pth的方式,随便弄了一个test_pth.py文件来看看
import torch
pth_file = ‘mobilenetv2_100_ra-b33bc2c4-bak.pth’ # 替换为你的 PTH 文件路径
model = torch.load(pth_file)
#print(model)
file = open(“output.txt”,“w”)
print(type(model),file=file)
print(len(model),file=file)
print(‘\n’,file=file)
for k in model.keys():
print(k,file=file)
print(‘\n’,file=file)
#print(model[‘conv_head.weight’],file=file)
file.close()
写在最后
特别鸣谢给予帮助的大佬,包括当前的各类大模型如kimi,但目前大模型暂时还不能一步到位给出我想要的答案,或许哪一天就可以了呢,可以拭目以待,那个时刻本文也就失去了存在的价值。
还有就是各种镜像源确实方便,多谢各位种树的前人。但是一些关键的节点还是有第一首资料或者可能会更好那么一点点,懂的都懂。
此处并不是为了说明这样折腾有多么厉害,只是记一下某种折腾的可能。此处只是入门,真正的折腾还没开始,还要继续。


















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









