




在ubuntu24.04系统下,逐步不断增加了不同的库,突然有一天发现在python当中已经无法导入pytorch。报错如下
import torch
Traceback (most recent call last):
File “”, line 1, in
File “/home/xx/.local/lib/python3.12/site-packages/torch/init.py”, l ine 405, in
from torch._C import * # noqa: F403
^^^^^^^^^^^^^^^^^^^^^^
ImportError: libnccl.so.2: cannot open shared object file: No such file or directory
询问kimi如何解决问题,答复如下:


nvidia的官网能找到相关信息https://developer.nvidia.com/nccl/nccl-legacy-downloads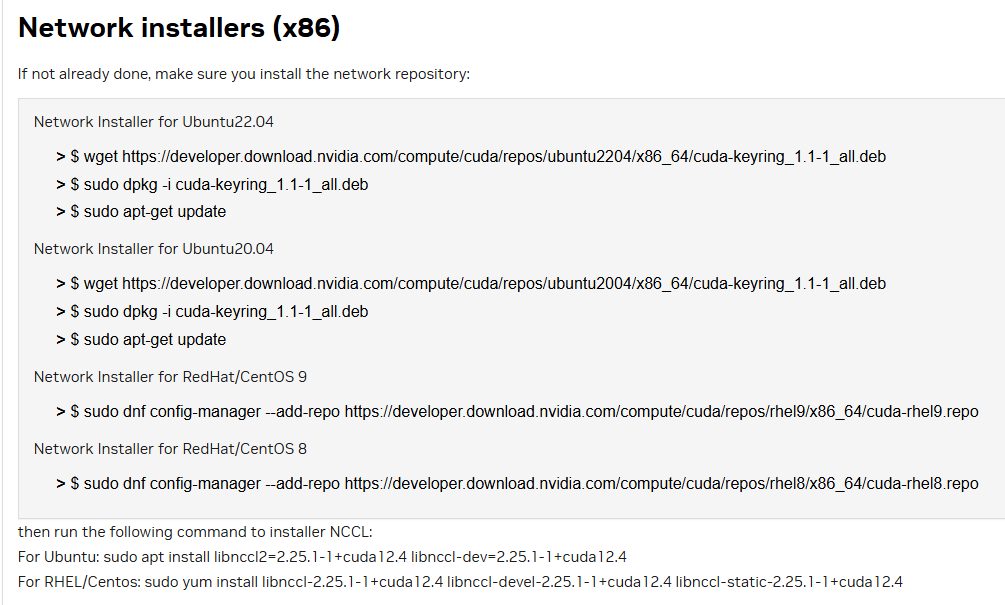
下载ubuntu2404的deb文件,然后重新安装就可以解决了(nccl指定版本的安装无需进行)
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt install libnccl2 libnccl-dev
尝试过卸载pytorch,然后重新安装pytorch无效。
再看AI的指引,已经指出了比较合适的思路。
参考
https://blog.youkuaiyun.com/weixin_54219288/article/details/141183399
https://blog.youkuaiyun.com/ww596520206/article/details/141051895

















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









