







DistFlow:Fully Distributed LLM RL训练框架
在大语言模型训练中,强化学习(RL)是提升模型推理能力与价值对齐的关键。本文解析DistFlow框架如何通过全分布式架构消除单节点瓶颈,实现近线性扩展至千级GPU,吞吐量较主流框架提升7倍,为大规模RL训练提供全新解决方案。
📄 论文标题:DistFlow: A Fully Distributed RL Framework for Scalable and Efficient LLM Post-Training
🌐 来源:arXiv:2507.13833v1 [cs.DC],链接:https://arxiv.org/abs/2507.13833
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
研究背景:大模型RL训练的 scalability 困境
大语言模型(LLM)的发展范式已形成"预训练-监督微调-强化学习"三阶段体系。其中,强化学习(RL)作为第三阶段核心技术,是GPT-4o、Gemini 2.5 Pro等先进模型实现复杂推理与人类价值对齐的关键。
当前主流RL框架(如verl、OpenRLHF)普遍采用混合控制器架构:单个中央控制器负责全局逻辑调度与数据传输,多控制器执行分布式计算。这种设计在大规模训练时暴露出致命缺陷——即使微小的负载不均衡也会引发严重瓶颈。当GPU数量扩展至数千级时,中央节点将因数据洪流陷入I/O拥堵,甚至导致系统崩溃。
就像城市交通系统中,若所有车辆必须经过一个中央枢纽,即使道路再宽也会因流量过载瘫痪。传统RL框架的单节点数据管理模式,正是制约大模型RL训练向更大规模扩展的"交通枢纽瓶颈"。
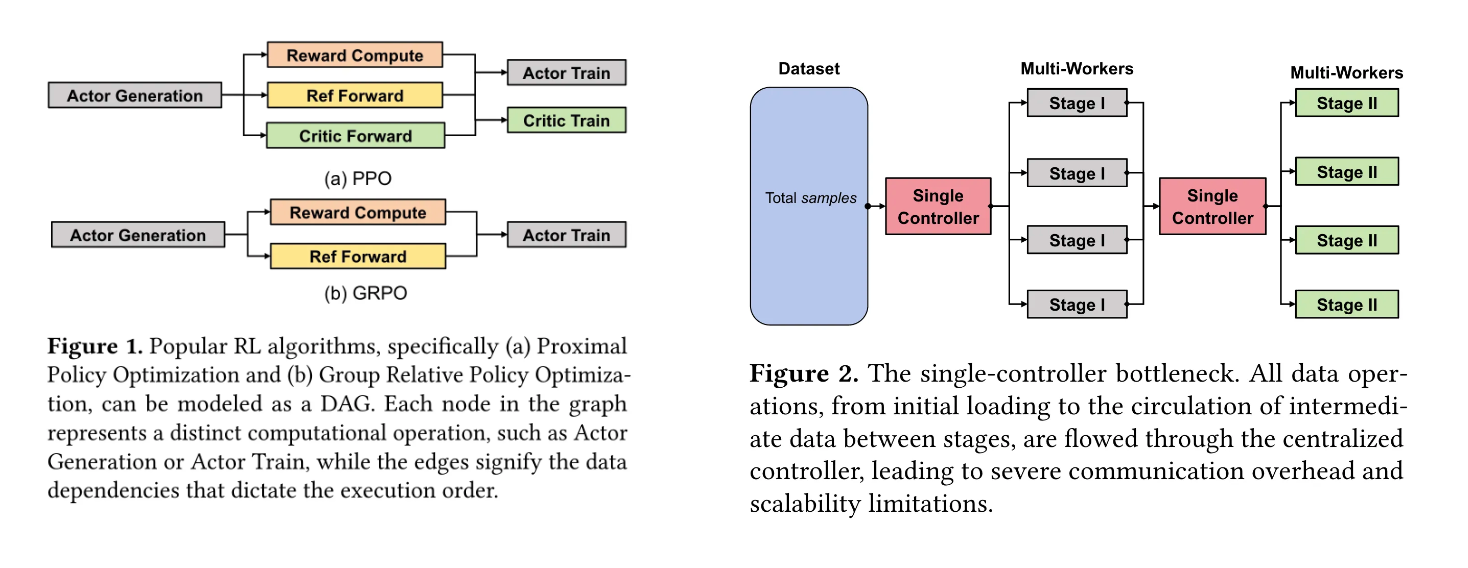
DistFlow核心创新:全分布式架构的突破
为解决这一困境,DistFlow提出全分布式RL框架,其核心创新可概括为"去中心化+灵活管道"两大支柱:
多控制器范式:消除单点依赖
DistFlow彻底摒弃中央控制器,将数据加载、计算调度、结果收集等任务均匀分配给所有worker节点。这种设计从根本上消除了单节点瓶颈,使系统可平滑扩展至数千GPU。
DAG驱动的模块化管道:算法与资源解耦
框架采用用户定义的有向无环图(DAG)描述RL工作流,将算法逻辑与物理资源管理完全解耦。研究者只需专注于DAG节点设计(如ACTOR生成、REWARD计算等),框架会自动将逻辑图映射到硬件资源。
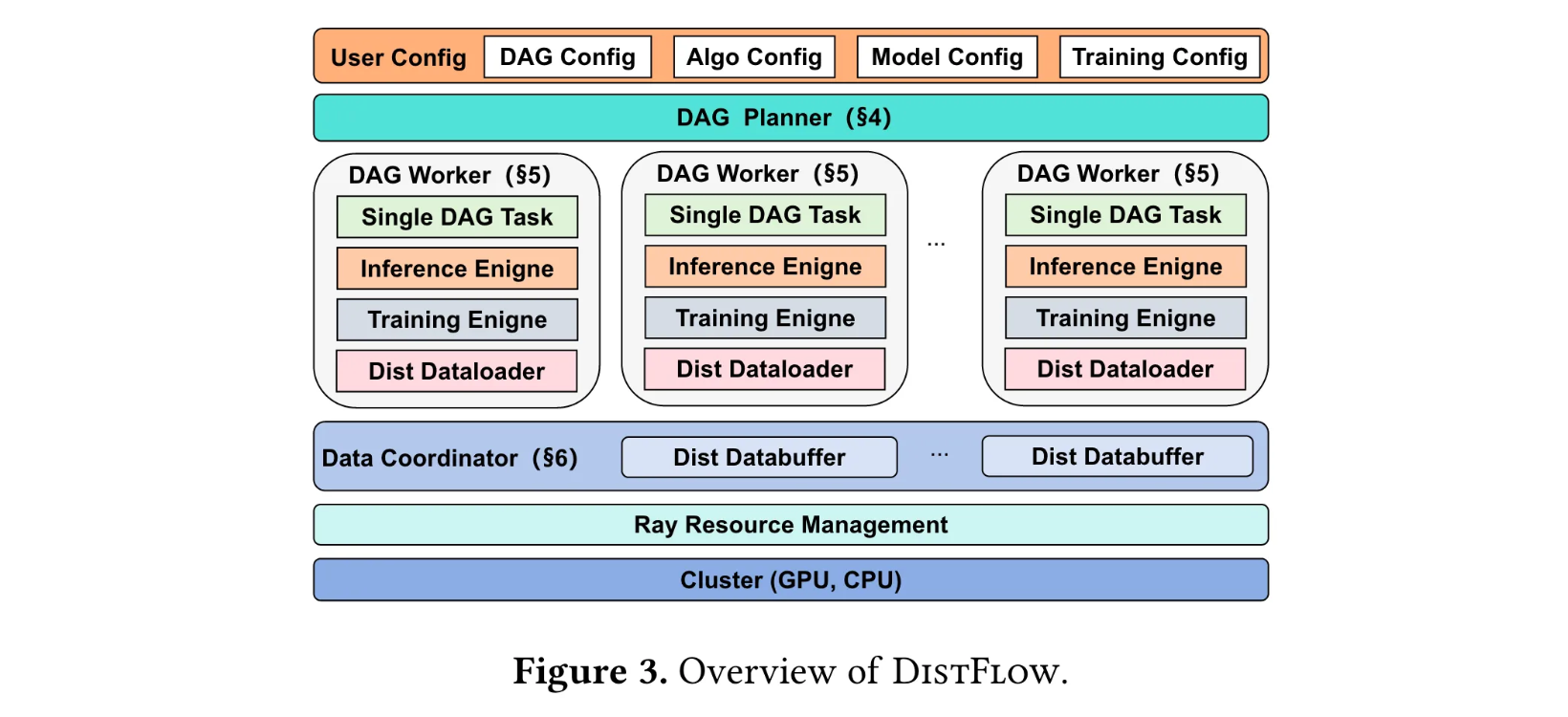
技术架构:DistFlow的三大核心组件
DistFlow架构由DAG Planner、DAG Workers和Data Coordinator构成,三者协同实现全分布式训练流程:
DAG Planner:工作流的"交通规划师"
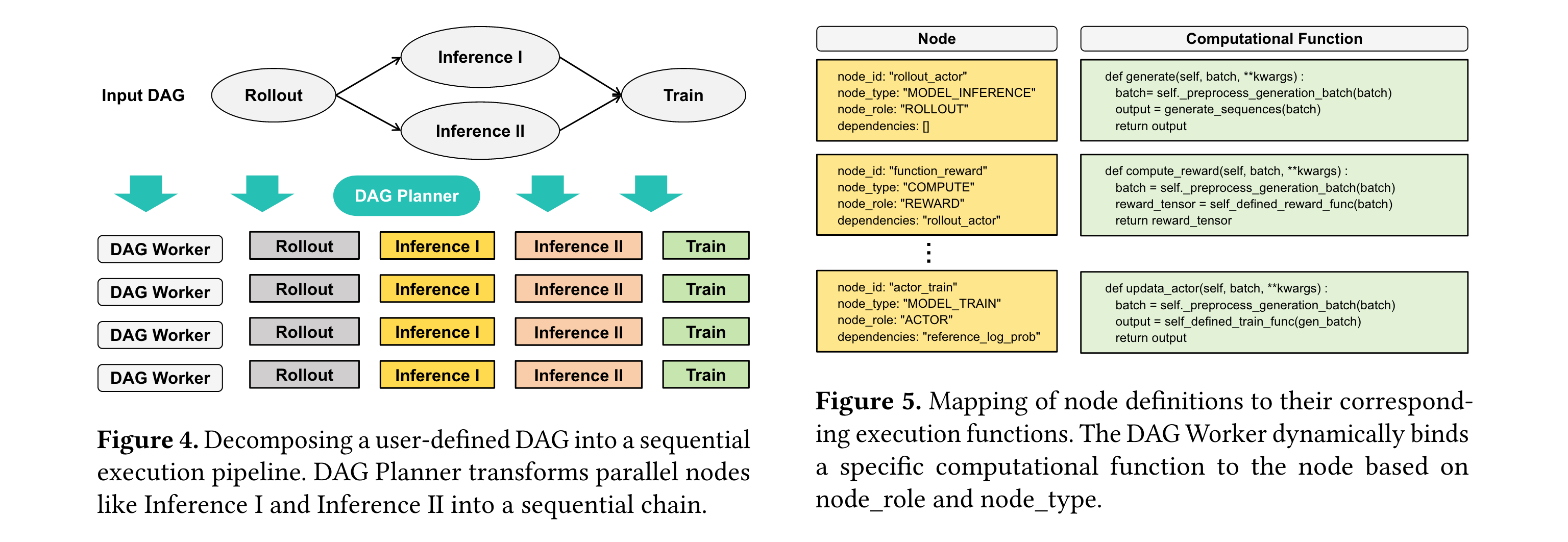
接收用户定义的DAG配置文件,将全局工作流分解为可执行的任务链。例如,若输入DAG包含并行的"Inference I"和"Inference II"节点,Planner会自动将其转换为序列化任务链,避免资源竞争。这一过程类似交通规划师将复杂路网转化为有序的单行系统,确保车流高效流动。
DAG Workers:计算执行的"智能单元"
每个Worker绑定单个GPU,是执行具体任务的基本单元。其工作流程分为初始化(加载模型、数据与引擎)和迭代执行(按任务链顺序处理数据)两阶段。通过动态函数映射机制,Worker能将DAG节点(如"ROLLOUT"角色+""MODEL_INFERENCE"类型)自动绑定到具体实现函数,实现模块化扩展。
Data Coordinator:分布式数据的"智能调度员"
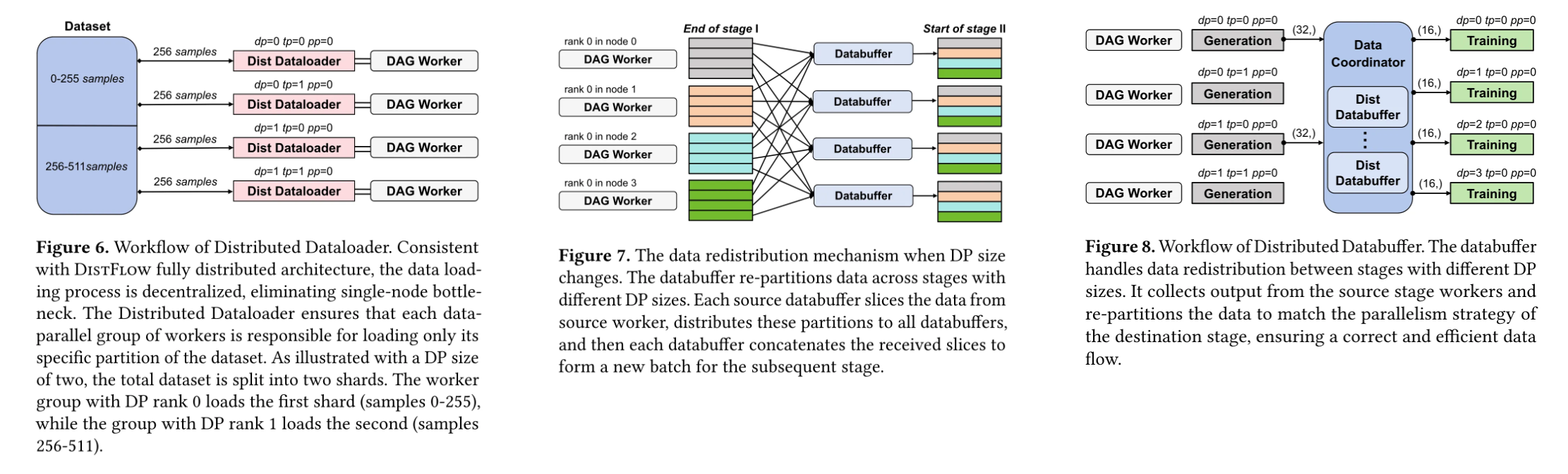
由Distributed Dataloader和Distributed Databuffer组成,解决两大核心问题:
- 分布式数据加载:按数据并行(DP)策略分片加载数据集。例如512个样本在DP=2时,会被分为0-255和256-511两个分片,由不同DP组并行加载,避免单节点负载过重。
- 跨阶段数据重分配:当相邻阶段DP策略变化时(如从DP=2转为DP=4),通过all-to-all通信模式重新分片数据。这如同快递分拣系统,根据目的地动态调整包裹路由,确保每个环节的处理量与运力匹配。
实验验证:性能与扩展性的全面超越
研究团队在包含128个节点(每节点8张NVIDIA Hopper GPU)的集群上,通过四组关键实验验证了DistFlow的优势:
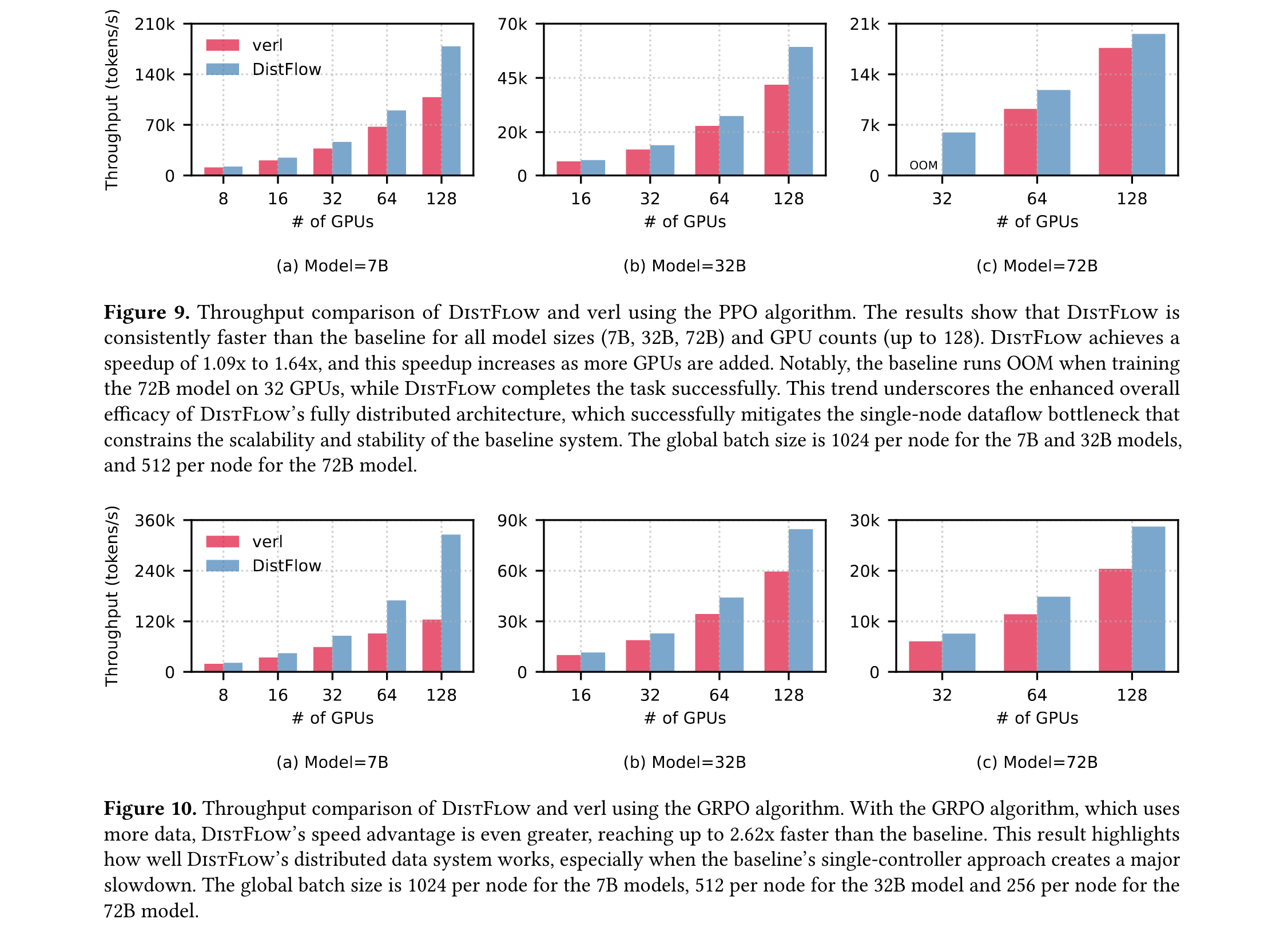
端到端吞吐量提升
- 在PPO算法测试中,7B-72B模型在8-128 GPU规模下,吞吐量较verl提升1.09-1.64倍
- 在数据量更大的GRPO算法中,优势扩大至2.62倍,72B模型在32 GPU时,verl因OOM错误失效而DistFlow正常运行
近线性扩展性
在VLMs测试中,DistFlow从32 GPU扩展至1024 GPU时保持近线性扩展。32B模型在512 GPU时仍能保持64 GPU性能的80.5%,如同将生产线从10条扩展到100条时,每条线的效率仅下降不到20%。
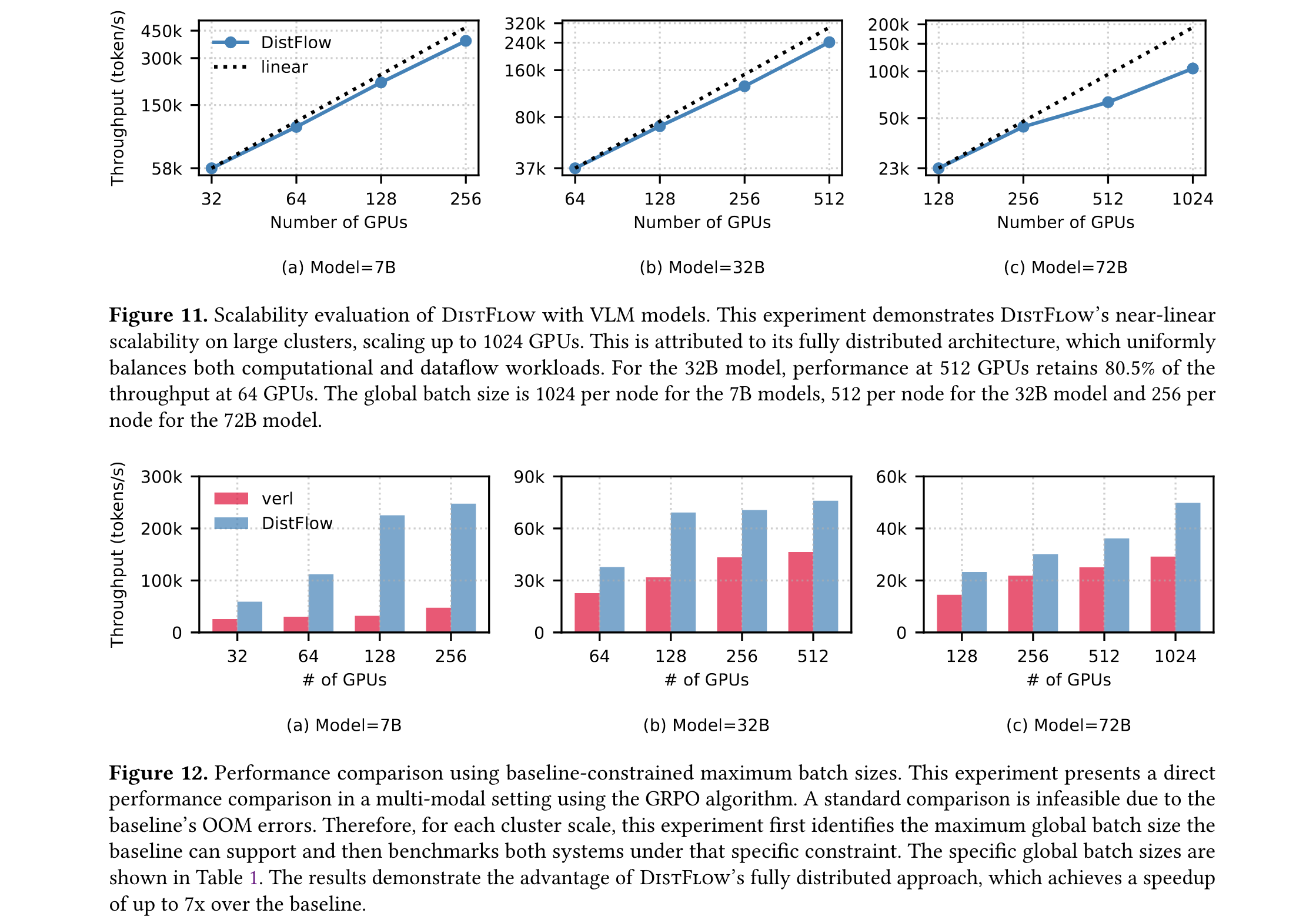
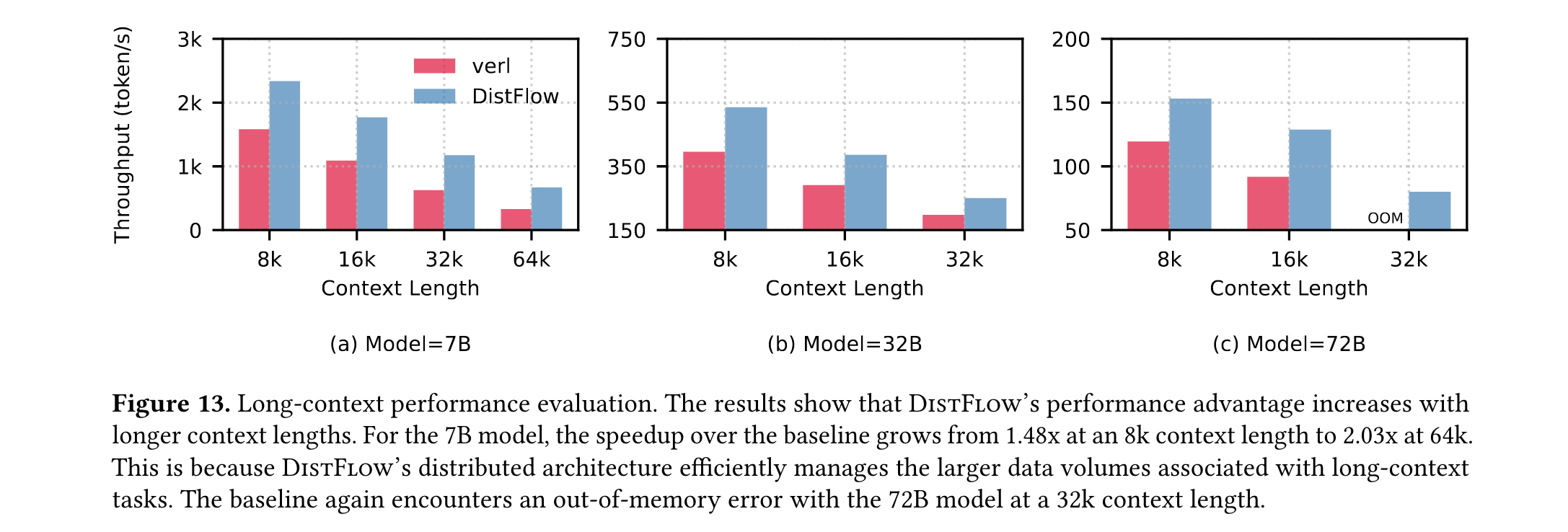
极端场景优势
- 长上下文任务:当上下文长度从8K增至64K时,7B模型的吞吐量优势从1.48倍扩大至2.03倍
- 多模态任务:在基线框架支持的最大batch size限制下,DistFlow实现最高7倍加速,验证了其在数据密集场景的优越性
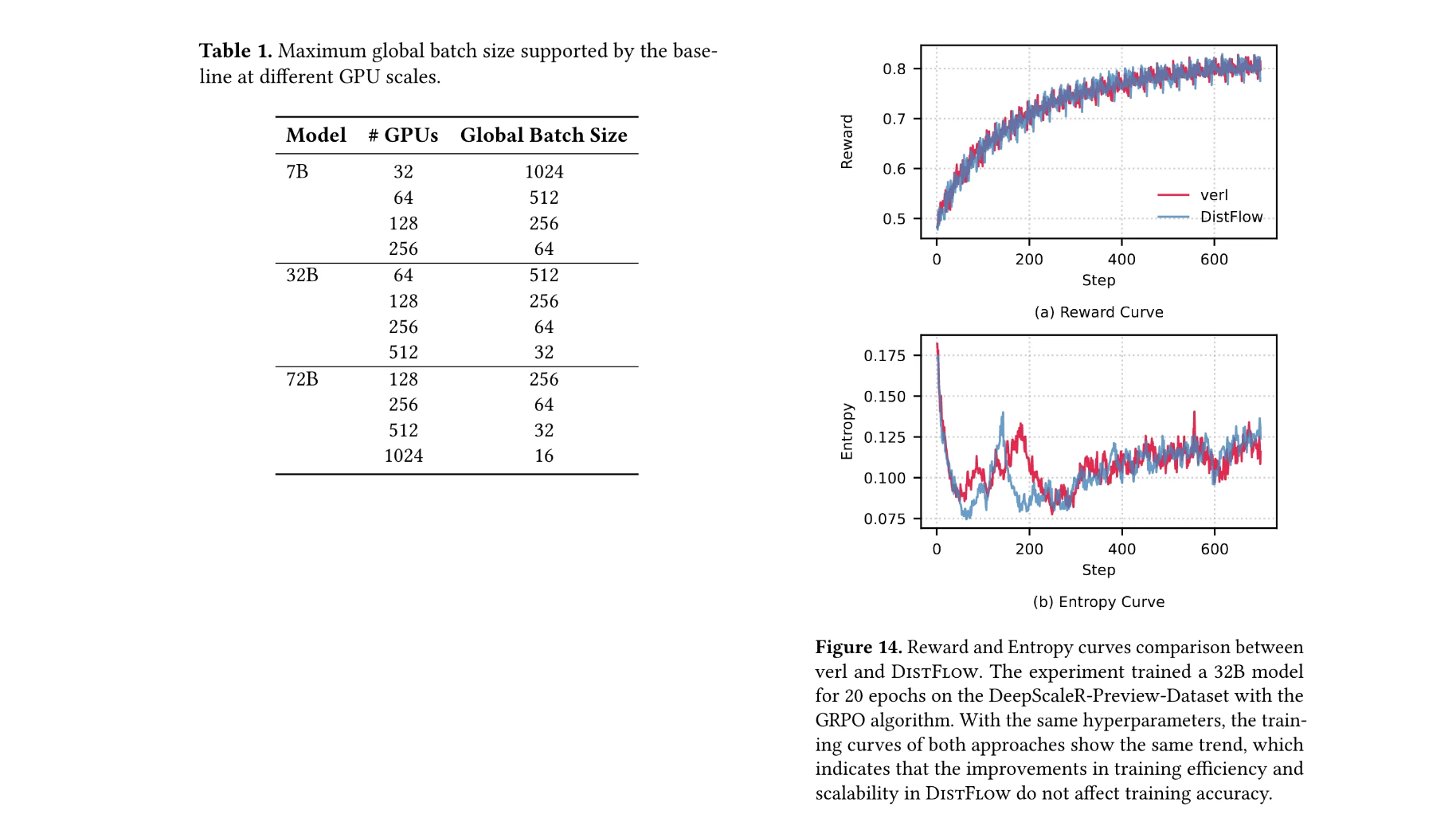
收敛性保证
在32B模型20轮训练中,DistFlow与verl的奖励曲线和熵曲线完全重合,证明性能提升未以牺牲模型精度为代价。
未来展望
DistFlow的突破为大模型RL训练带来三重变革:
- 打破规模天花板:全分布式架构使RL训练从"数百GPU级"迈向"数千GPU级",为更大规模模型训练铺平道路
- 降低算法实验成本:DAG定义的灵活管道使研究者能快速迭代新算法,无需修改底层框架代码
- 推动RL能力边界:通过高效利用计算资源,加速复杂推理、多模态对齐等前沿方向的研究
未来,计划整合Megatron-LM作为训练后端,进一步优化超大规模模型的扩展性能。


















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









