



随着人工智能与科学研究的深度融合,AI 驱动的科学发现正进入加速发展期。在这一背景下,如何科学、客观地衡量模型在真实科研场景中的能力,已成为推动 AI for Science 可持续发展的关键。
近日,司南(OpenCompass)官网正式上线科学智能评测版块,依托书生科学发现平台,构建面向多学科、多模态的科学智能评测,专注衡量大模型、智能体在核心科研能力上的真实水平,为科学智能提供可量化、可对比、可迭代的能力坐标。

今年 7 月,由上海人工智能实验室打造的创新开放评测体系司南完成全面升级,评测范围从通用大模型扩展至 AI 计算系统、具身智能、安全可信与垂类行业应用五大方向。随着科学智能评测版块的正式上线,司南现已形成 “六位一体”的全景评估体系,打通从底层算力到上层智能、从通用能力到科研创新的全链路关键能力,为行业提供一站式、全景化的 AI 能力刻度。
科学智能评测司南官网链接:
https://opencompass.org.cn/Intern-Discovery-Eval
全流程闭环化的科学智能评测范式
科学智能评测聚焦多学科真实科研场景,构建覆盖科学发现全流程的闭环化评测机制,确保评测结果科学可信、可持续演进。
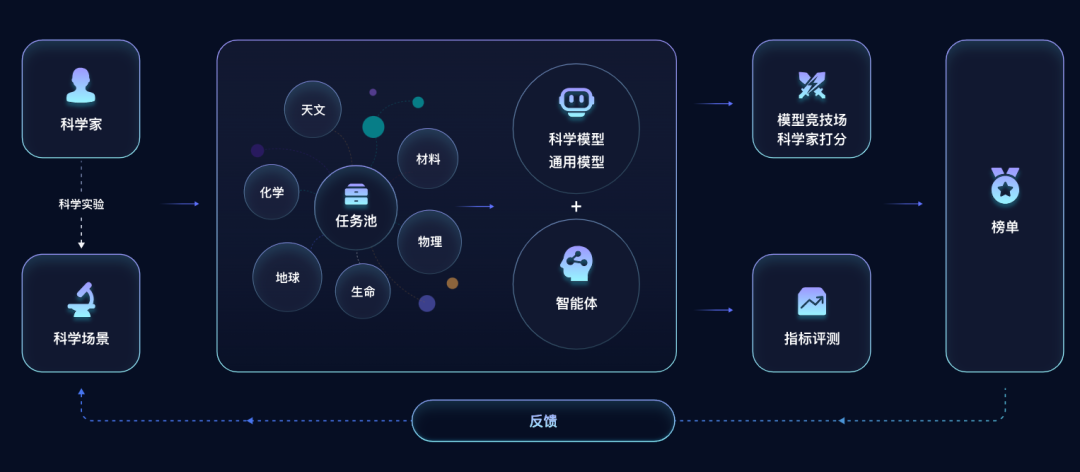
-
科学家深度参与:由领域科学家提供实验设定与任务源头,从评测设计阶段即对齐真实科研场景;
-
多学科任务池:任务池覆盖天文、化学、物理、地球、材料、生命等多个学科,系统评估模型在不同科研领域中的能力表现;
-
真实科研流程执行:大模型与智能体在真实科研任务中完成推理、决策与协作,完整呈现科学发现过程;
-
指标评测 + 专家评审:通过客观指标量化模型在科研任务中的表现,并结合科学家打分,形成公开、可比的科学能力榜单;
-
闭环反馈机制:评测结果持续回流至任务池与科研场景,推动任务设计优化与模型能力的迭代升级。
这一全流程、多学科、闭环化的评测范式,使科学智能能力真正实现可量化、可对比、可迭代,为 AI 驱动的科学发现提供科学、可信、可持续的评测支撑。
科学智能评测榜单:揭示模型真实科研能力
科学智能评测版块同步发布大语言模型科学能力榜单与多模态模型科学能力榜单,系统呈现模型在科研场景中的实际表现。
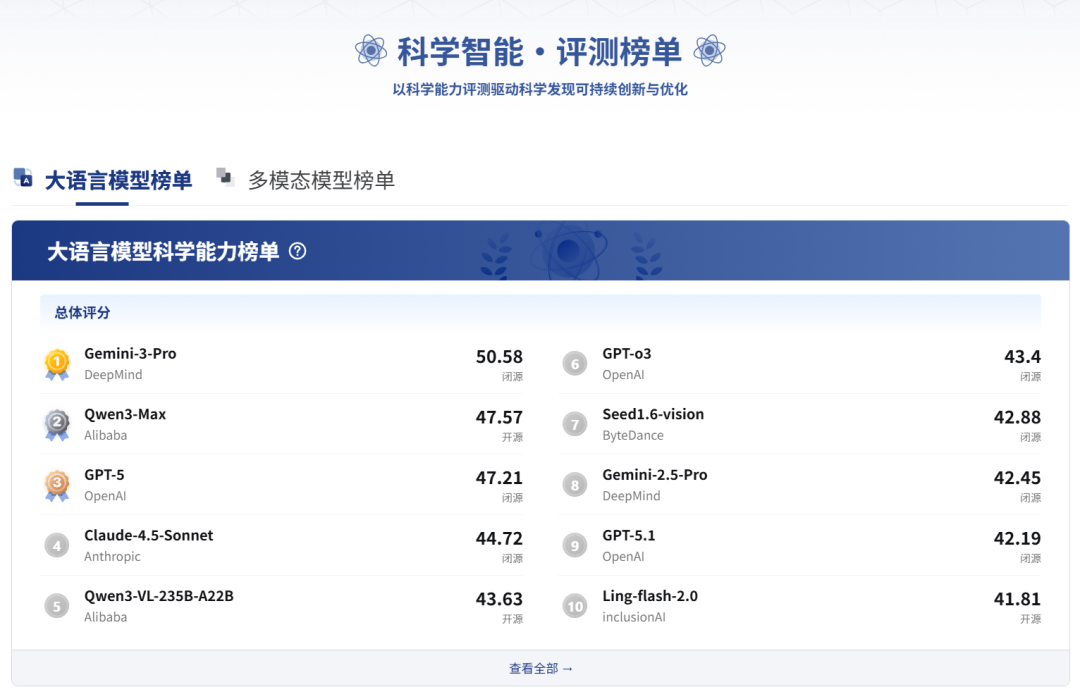
大语言模型科学能力榜单旨在系统评估主流通用大语言模型在科学研究场景中的核心能力表现。
榜单聚焦模型在文本驱动的科学认知、推理与生成任务中的综合能力,覆盖从基础科学知识理解到高阶研究假设构建的完整链路,反映模型作为“通用科学智能体”的实际潜力。
从以下四个关键科学能力维度对模型进行评测:
-
科学知识理解:评估模型对学科特定概念、事实与结构性知识的掌握程度,例如分子属性判断、专业概念辨析等。
-
科学代码生成:考察模型将科学问题描述转化为可执行程序、算法流程或数据处理代码的能力。
-
科学符号推理:聚焦模型对数学公式、物理定律、符号系统及结构化表达的推演与逻辑运算能力。
-
科学假设生成:衡量模型在开放式科学问题中提出合理研究假设、解释路径与潜在研究方向的能力。
榜单中的总分为上述四个维度得分的平均分数,用于刻画模型在文本层面开展科学分析、推理与创新任务时的整体表现。
完整大语言模型科学能力榜单见:
https://opencompass.org.cn/Intern-Discovery-Eval/llm/scientific-capability
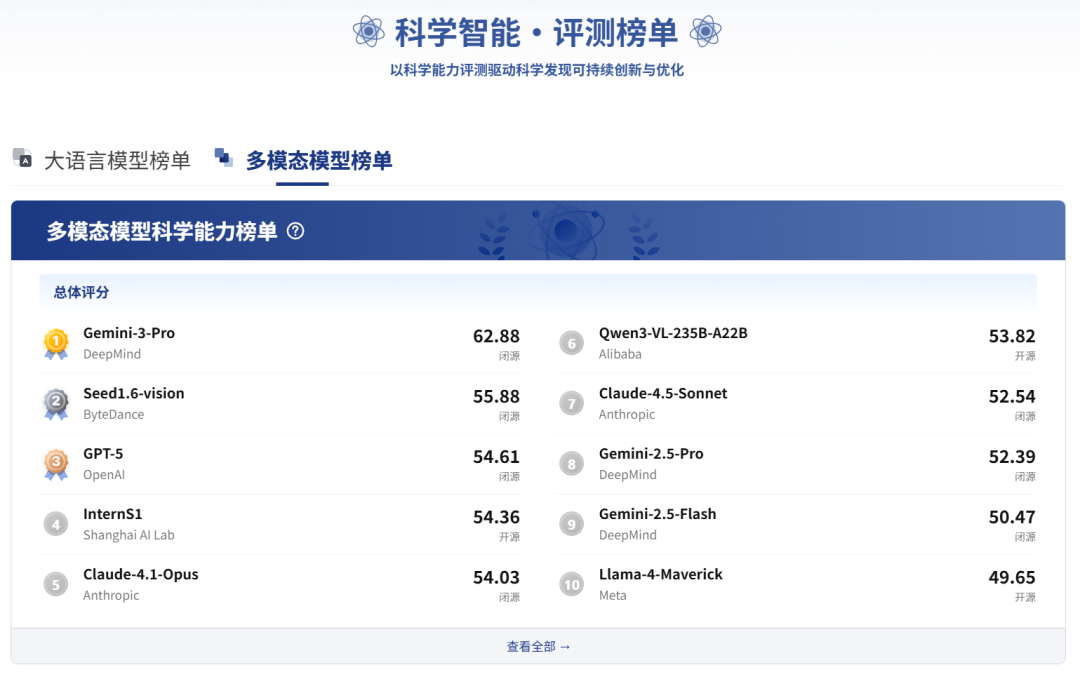
多模态模型科学能力榜单面向视觉—语言大模型,重点评估模型在真实科研场景中对科学图像、图表与文本信息的联合理解与推理能力。榜单强调多模态输入条件下的科学感知与认知过程,反映模型在复杂科研资料中的实际应用价值。
围绕以下三个多模态科学能力维度展开评测:
-
科学多模态感知:关注模型在图文输入中对关键科学实体的定位与识别能力,例如医学影像、实验装置或图中标注要素。
-
科学多模态理解:评估模型对原始科学多模态数据的整体语义理解与严谨解释能力。
-
科学多模态推理:考察模型在图像与文本联合条件下进行逻辑推理、因果分析与跨模态信息整合的能力,包含基于图像证据的多步推理过程。
榜单中的总分为三项多模态科学能力得分的平均分数,用于衡量模型在多模态协同科研任务中的整体科学智能水平。
完整多模态模型科学能力榜单见:
https://opencompass.org.cn/Intern-Discovery-Eval/mllm/scientific-capability
除此之外,科学智能评测版块还开源了首个面向科学通用智能的开源评测工具链 SciEvalKit。SciEvalKit 建立在专家级科学基准的基础之上,这些基准均源自真实世界的领域特定数据集,确保了任务反映真实的科学挑战,旨在跨越广泛的科学学科和任务能力来评估 AI 模型。技术报告将于近期发布,敬请期待。
SciEvalKit GitHub 链接:
https://github.com/InternScience/SciEvalKit
更多科学智能评测内容,欢迎访问司南官网。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









