




司南评测集社区 CompassHub 作为司南评测体系的重要组成部分,旨在打造创新性的基准测试资源导航社区,提供丰富、及时、专业的评测集信息,帮助研究人员和行业人士快速搜索和使用评测集。
2025 年 6 月,司南评测集社区新收录 30+ 个评测基准,聚焦多模态理解、智能体、代码等多个前沿领域。以下为本月部分新增评测基准的详细介绍。
司南评测集社区链接:
https://hub.opencompass.org.cn/home
多模态理解
MVPBench
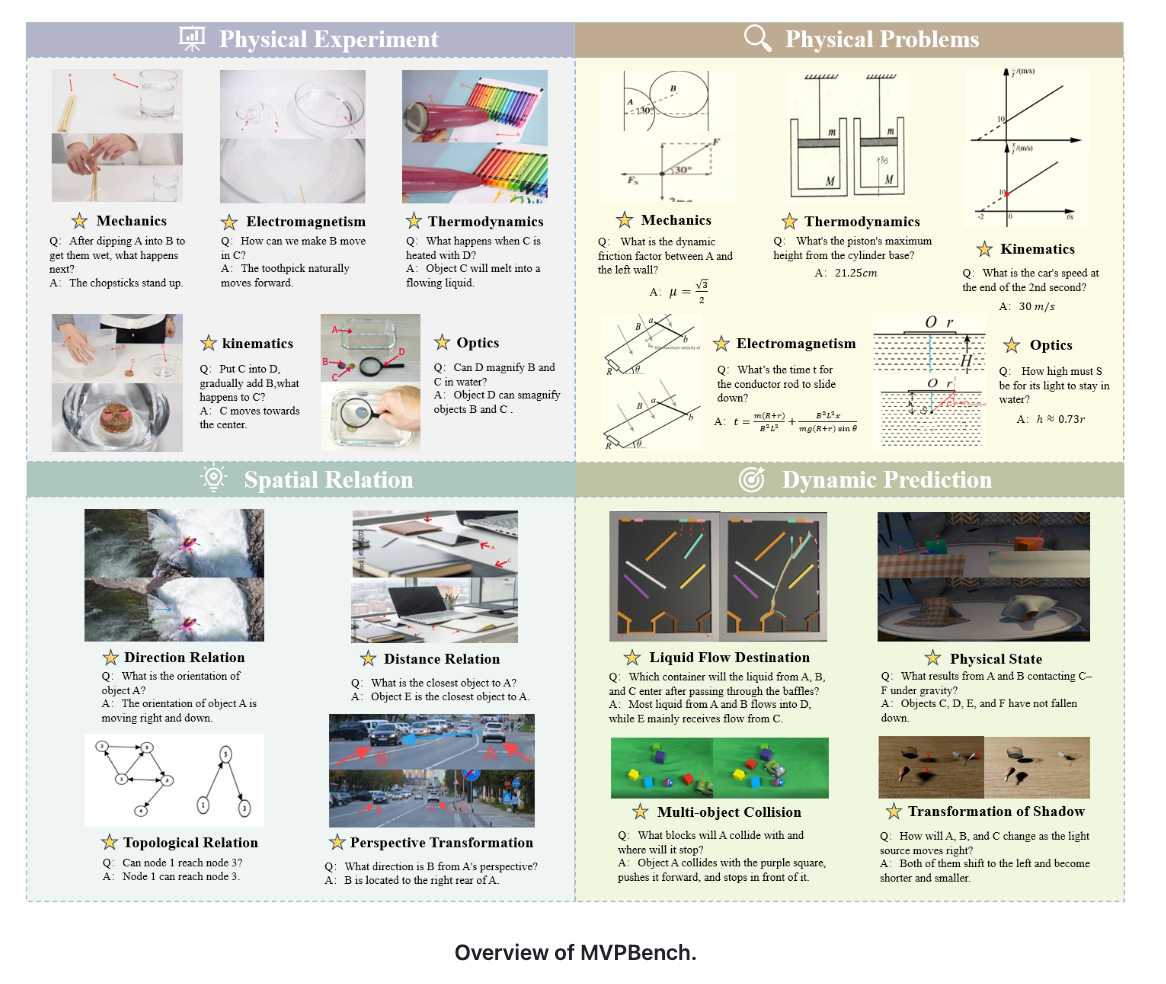
发布单位:
Central South University
发布时间:
2025-06-02
评测集简介:
MVPBench 专注于视觉物理推理中的视觉链式思维(CoT)能力评估。它特别关注模型能否像人类一样,依据图片一步步进行逻辑推理,而不是依赖文字提示直接得出结论。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MVPBench
MORSE-500
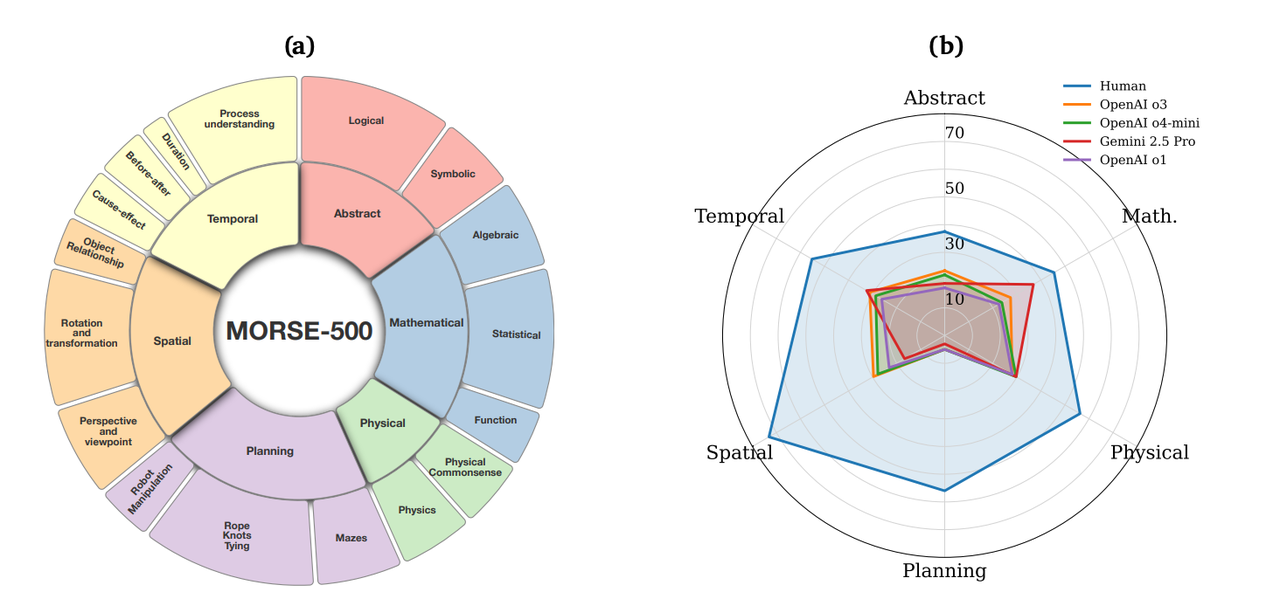
发布单位:
University of Maryland
发布时间:
2025-06-05
评测集简介:
MORSE-500 是一个用来测试多模态看视频后是否能“理解逻辑关系”的数据集,包含六种推理类别(抽象、数学、物理、规划、空间和时间)的 500 个程序生成视频,用于测试多模态推理能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MORSE-500
VideoMathQA
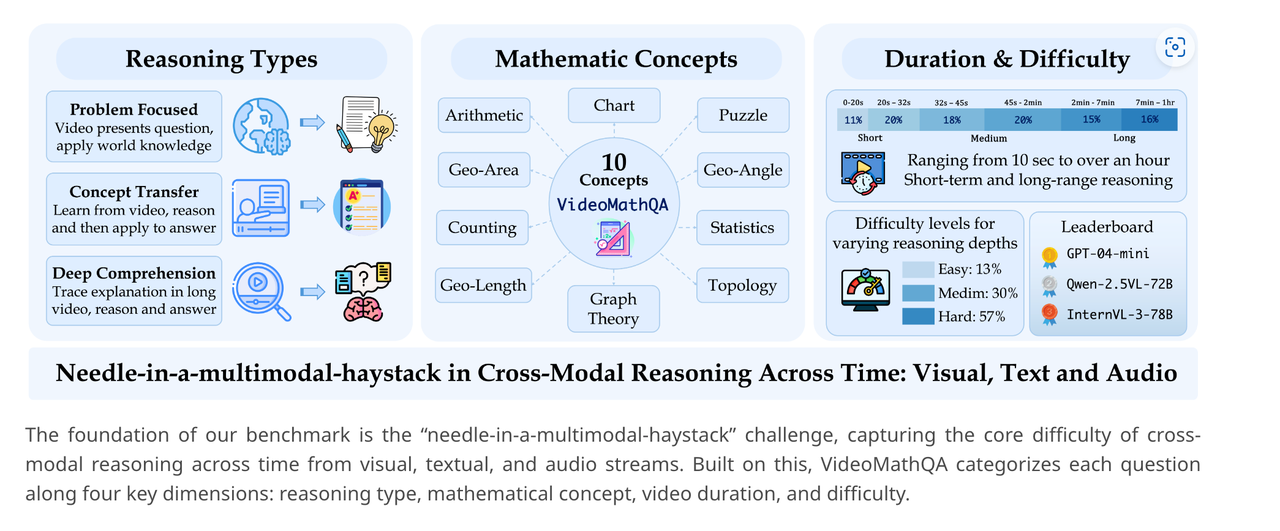
发布单位:
MBZUAI,University of California Merced,Google Research,etc
发布时间:
2025-06-05
评测集简介:
VideoMathQA 是一个用于评估多模态模型在视频场景下数学推理能力的评测集。该数据集要求模型同时理解视频中的视觉、音频和文本信息,处理长度从 10 秒到 1 小时不等的内容,包括几何、统计、算术和图表等 10 个领域。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/VideoMathQA
CausalVQA
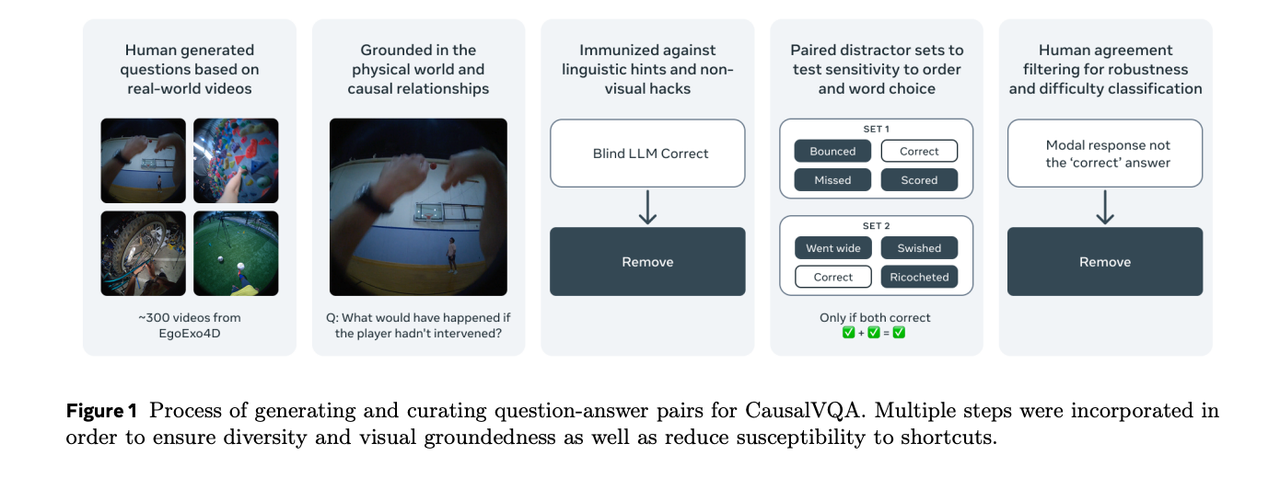
发布单位:
FAIR at Meta
发布时间:
2025-06-11
评测集简介:
CausalVQA 是一个用于评估多模态模型因果推理能力的视频问答数据集。它涵盖反事实、假设、预判、规划和描述五类问题,考察模型对事件结果与行为后果的理解与预测能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/CausalVQA
IntPhys2

发布单位:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









