




2025年11月20日,中文医疗大模型权威评测平台MedBench全面迭代更新,发布了全国首个且唯一的面向垂模、专模、各大应用场景的医疗大模型评测与验证体系。本次升级聚焦实战化评测突破与生态化开放共建两大核心,全面覆盖大语言模型、多模态大模型及智能体三大技术范式,深度对齐国家《卫生健康行业人工智能应用场景参考指引》,为医疗AI从技术可行向临床可用搭建核心验证桥梁。
平台数据印证行业认可度:截至目前,累积总累积活跃用户数近6万,评测服务模型总量近4万,周提交评测次数3万多,周点击次数20万以上,成为医疗AI领域核心 “度量衡”。
MedBench官网链接:
https://medbench.opencompass.org.cn
三大技术范式评测:直击临床核心痛点
1. 大语言模型评测:精准锚定能力短板
围绕医学知识问答、语言理解、生成、复杂推理及安全伦理五大维度,构建36个自主评测集,涵盖70万条高质量数据,覆盖24个一级科室、91个二级科室。创新性引入 “评价模型(LLM-as-a-Judge)结合基于要点信息计算(Macro-Recall)”的 双指标体系,缓解模型信息遗漏或幻觉生成等高频问题对评测结果的影响。
2. 多模态大模型评测:填补专科评估空白
针对医疗影像、检测报告等临床核心场景,建立医疗视觉感知、跨模态推理、临床决策支持三大维度,自主研发10个专业评测集,覆盖目标检测、图像分类、多模态报告质控、序列影像理解、病程动态追踪等10项细分任务,更新了交并比IoU,归一化编辑距离1-N.E.D等多项评测指标,彻底填补中文医疗多模态评测领域的技术缺口。
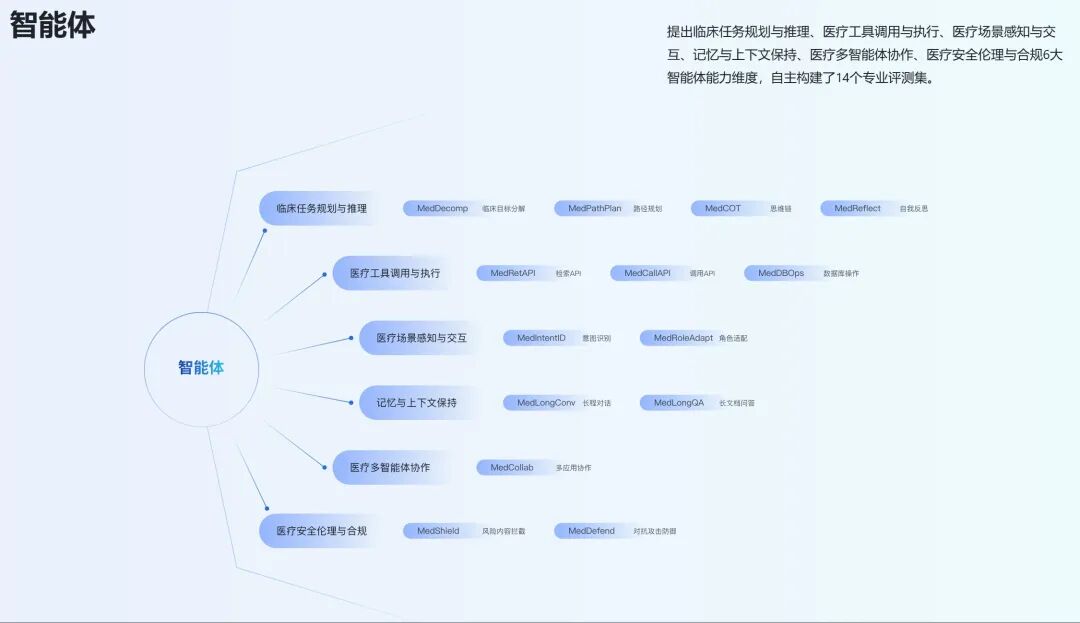
3. 智能体评测:推动从 “会说” 到 “会做”
从临床任务规划与推理、医疗工具调用与执行、医疗场景感知与交互、记忆与上下文保持、医疗多智能体协作,到医疗安全、伦理与合规,共设立六大能力维度,并配套研发14个专业评测集,重点解决智能体执行断层的问题,推动医疗智能体从“能对话”向“能执行、能协作”演进。
首个支持真实医患对话的多轮评测模型
MedBench正式推出首个支持真实医患对话的多轮评测模型,专为“医生模型”提供贴近临床实战的评估环境。该系统基于主动型患者模拟器,可驱动长达8轮的结构化医患对话,覆盖103个症状和106种疾病,并支持普通、消极、没耐心等多种患者角色设定,显著提升模型主动对话能力的可检验性。

此外,MedBench平台技术全面迭代,提出三大创新机制,强化评测临床价值:
-
Mini-CEX标准化评估:首次将临床教育评估标准适配AI评测,明确信度、效度指标,使模型表现可对照临床规范审计;
-
“评测-训练” 闭环:通过小模型强化学习注入推理机制,构建可复现优化流水线,助力模型降低误诊率、提升决策特异性;
-
国际模型横向对标:评测榜单更新国际前沿模型评测结果,纳入OpenAI、Anthropic、Google等主流模型医疗能力数据,为国内模型提供客观参照系。
专精赛道,丰富的Special Track测评赛制
MedBench秉持开放合作的原则,持续与医疗机构、高校和企业深化专科评测,本次又更新落地了3大挑战赛事,包括中医临床科研综合能力深度测评(TCM-5CEval)、儿科真实场景综合能力和临床动态进展思维能力双轨测评(PEDIASBench)、随机对照试验循证证据质量评估(RCTBench),优化全场景覆盖能力。
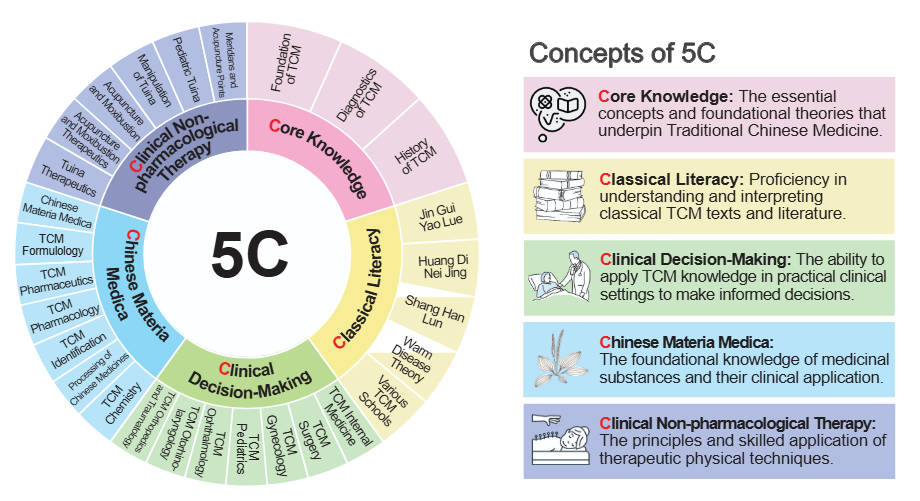
TCM-5CEval
上海人工智能实验室与上海中医药大学、中国中医科学院合作,开放了中医临床科研综合能力深度测评挑战赛,本赛题旨在全方位考察大模型中医综合能力,紧扣中医基础、经典理解、临床诊疗、中药方剂、针灸推拿五大核心维度,以多维度试题及真实临床病案场景设计考题,力求精准评估模型的中医专业素养与实战应用水平。通过TCM-5CEval的评测基准结果可以发现,Kimi-K2-Instruct、DeepSeek-R1等模型表现出色,模型普遍擅长中医专业考试,对经典著作理解、针灸推拿诊疗则表现欠佳;此外我们还发现大模型普遍在以下方面薄弱:
(1)对经典文献进行文本诠释的能力明显不足;
(2)在四诊合参的辩证推理能力还偏弱,主要是证候分型、治则确定经常出问题;
(3)难以掌握诸如药材鉴别、穴位选择等细致入微的专家级知识。
该评测框架可作为诊断模型弱点并指导未来努力开发更博学、更可靠的模型的标准化评估范式。
论文地址:https://arxiv.org/abs/2511.13169
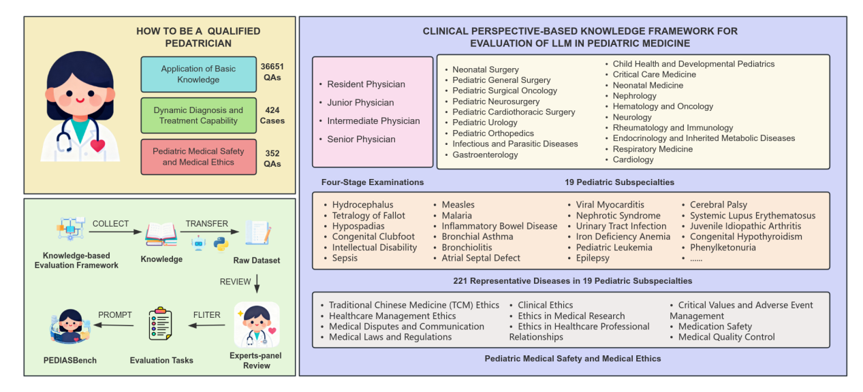
PEDIASBench
上海人工智能实验室与上海市儿童医院合作,开放了儿科真实场景综合能力和临床动态进展思维能力双轨测评挑战赛,旨在通过基础知识应用、动态诊疗能力、医疗安全与伦理三个主要维度,构建以知识体系为核心的评估新范式,突出临床动态进展及儿童生长发育特性,全面评估模型在儿科真实临床环境表现。该评测范式首创性构建以知识体系框架为核心的临床真实环境测评新范式,精准锚定 “知识驱动 + 真实场景” 的临床测评核心需求。结果发现没有模型在所有维度都能够名列前茅,Qwen3-235B-A22B、DeepSeek-V3虽然在基础知识应用和医疗安全与医疗伦理方面得分较高,但是动态诊疗能力方面仍有不足。
论文地址:https://arxiv.org/abs/2511.13381
RCTBench
上海人工智能实验室与中山大学孙逸仙纪念医院合作,开放了随机对照试验(RCT)循证证据质量评估挑战赛,依据CONSORT声明开展 RCT 文献质量评估考评文献质量研判能力,并结合RCT研究设计细节及报告完整性信息评估方法学合规性及结果可信度,全面评估模型的科研文献分析能力及临床科研辅助服务能力。评测数据涵盖近五年发表的RCT文献,涉及12个临床专科与38类常见疾病,文献来源兼顾不同影响因子及不同语言期刊的报告特征。评测基准结果显示多数模型识别符合条目整体表现较好,识别不符合条目时差异较大,模型得分离散度高,识别不适用条目中,GPT5表现突出。综合性能方面,Gmini-2.5-Flash、DeepSeek-R1、GPT5-mini优于其他模型。
论文地址:https://arxiv.org/abs/2511.13107

开源医疗大模型园区OpenMedZoo
此外,MedBench在开源社区的生态方面,已提出了医疗伦理和安全的框架,并开源了相关数据集。在此基础上,平台持续开源共享,建立了开源医疗大模型模型园区OpenMedZoo,该开源模型园区旨在构建一个开放、安全、可信的医疗AI生态系统。目前已开放了首个高可靠性医疗安全伦理开源推理模型(SafeMed-R1)以及开源的全科基层医生大模型(Med-GO)等多个项目,我们汇集顶尖研究力量,分享多模态、多场景的医疗大模型、算法与数据集。
OpenMedZoo开源链接:https://github.com/OpenMedZoo
欢迎联系加入:medbench@pjlab.org.cn

















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









