




视频模型已经在高保真视频生成领域取得了突破性进展。先前工作如 Stable Video Diffusion和 Imagen Video 已展示出视频模型能够根据输入指令生成物理上逼真且时间一致的视频。近期研究进一步表明,先进的视频模型不仅能生成,还能执行包括视觉感知、理解甚至推理在内的多种视觉任务。这表明视频模型正从纯生成模型演化为通用视觉智能模型。
类似于语言模型从“文本生成”演变到“基于文本的推理”,视频模型的发展引出一个关键问题:“视频模型能否通过生成视频来进行推理?”
近日,上海人工智能实验室联合团队发布了最新研究成果 Reasoning via Video,针对这一问题展开了探索。
核心贡献:
-
首次对“通过视频进行推理”范式进行了系统性探索。 在该范式下,通过生成下一帧而非预测下一 token 来实现推理。相较于基于文本的方法,这一范式天然捕捉时间连续性与空间因果关系,为解决空间推理任务提供了更具表达力和更具扩展性的载体。
-
提出 VR-Bench,一个基于迷宫求解任务,系统评估视频模型推理能力的综合基准,覆盖多种空间结构、难度等级与纹理风格。
-
大规模实验表明,基于视频的推理在复杂任务上优于基于文本的推理(如 VLM),尤其在迷宫类型、视觉风格及难度变化等分布偏移下表现更强。经过微调的视频模型展现出更高性能、更低路径冗余以及更强的结构一致性。
-
揭示了视频模型的测试时扩展效应:随着推理预算增大,模型性能持续提升。与 LLM 类似,多样化采样能够解锁多路径探索,在多个指标与难度等级上带来高达 20% 的性能增益。

论文链接:
https://arxiv.org/abs/2511.15065
该工作目前已在司南 Daily Benchmark 专区上线。
https://hub.opencompass.org.cn/daily-benchmark-detail/2511%2015065
-
AI 评测论文“追更神器”
-
每日更新最新 AI 评测方向论文
-
每篇论文都支持 AI 智能解读
查看更多最新 AI 评测论文,欢迎访问:
https://hub.opencompass.org.cn/daily-benchmark-list
VR-Bench 介绍
VR-Bench 建立在迷宫求解任务之上,迷宫求解任务具备开放式解空间与轨迹监督,天然适合评估视觉推理。每个任务都要求模型执行空间规划、动态跟踪与多步推理,是评估模型随时间的推理质量的理想载体。
VR-Bench 包含 7,920 个程序生成的迷宫视频,每个视频对应一个“轨迹推理任务”,要求模型推断最优路径。
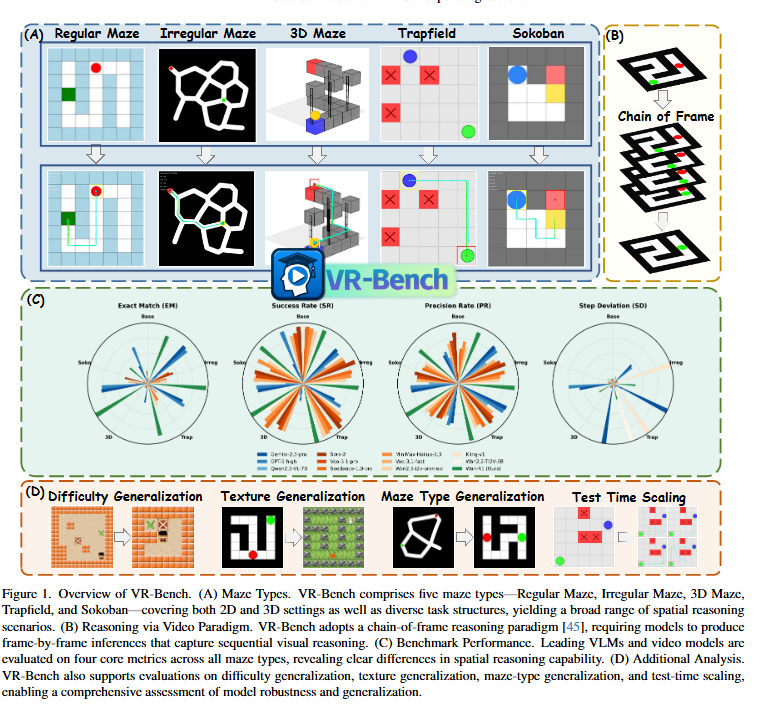
上图为 VR-Bench 总览图。
(A) 迷宫类型。 VR-Bench 包含五类迷宫任务:规则迷宫、不规则迷宫、3D 迷宫、陷阱场以及推箱子迷宫 ,覆盖 2D 与 3D 两种设定,并具备多样的任务结构,构成广泛的空间推理场景。
(B) 基于视频的推理范式。 VR-Bench 采用 chain-of-frame(逐帧链式)推理范式,要求模型进行逐帧推理,以捕获连续的视觉推理过程。
(C) 基准表现。 研究团队在所有迷宫类型上,对主流 VLM 与视频模型在四项核心指标上进行评测,揭示不同模型在空间推理能力上的显著差异。
(D) 额外分析。 VR-Bench 还支持对难度泛化、纹理泛化、迷宫类型泛化以及测试时扩展(test-time scaling)等维度的评估,从而实现对模型鲁棒性与泛化能力的全面测试。
系统实验
为全面评估视频模型的推理能力,研究团队在 VR-Bench 上进行了系统实验,评测了多种最新的商用与开源视频生成模型。同时,为了突出视频模型相对于传统多模态方法的优势,研究团队也纳入了具有代表性的视觉语言模型(VLM)进行对比。
此外,研究团队在 VR-Bench 上对开源视频模型 Wan2.2-TI2V-5B 进行了微调,以研究其在推理任务上的泛化能力。
主要观察
-
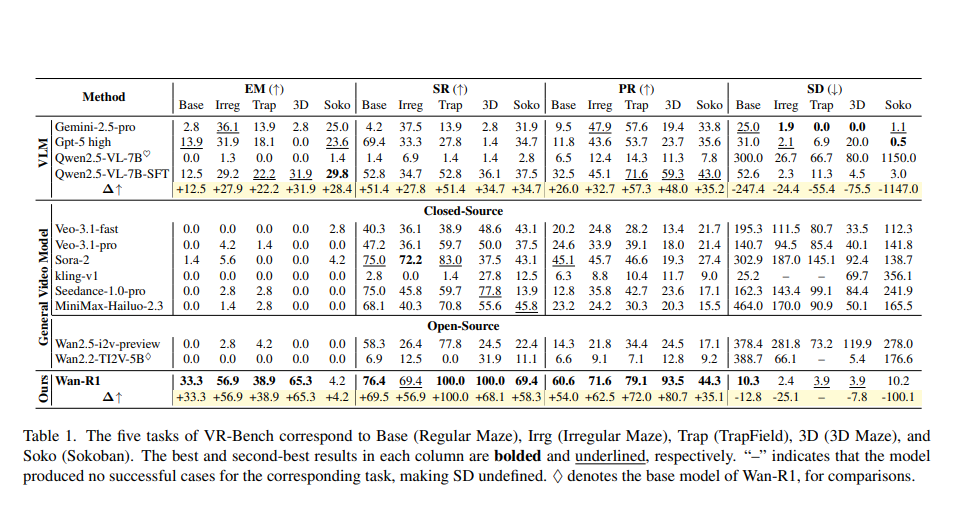
Wan-R1 在 VR-Bench 上优于先前模型
如表 1 所示,Wan-R1 在几乎所有任务和评估指标上均取得了领先表现,显示出高准确性和高效的 rollout 能力。值得注意的是,Wan-R1 在 Trap 和 3D 迷宫任务中达到了 100.0 的 SR,展现了在复杂环境下的稳健成功能力。相比基础模型 Wan2.2-TI2V-5B,Wan-R1 在 3D 任务上 EM 提升 +65.3,在 Soko 任务上 SD 减少 100.1。这些成果凸显了微调策略在提升正确性与轨迹质量方面的有效性,适用于多样化的推理场景。
-
仅完成任务并不保证高效推理 一些模型虽然能够完成任务,但其 rollout 过程仍然低效
例如,Sora-2 和 MiniMax-Hailuo-2.3 在 Base 任务上的 SR 分别为 75.0 和 68.1,但对应 SD 值分别高达 302.9 和 464.0,显示出显著的路径冗余。更为极端的是,开源 VLM Qwen2.5-VL-7B 的 SR 仅为 1.4,但 SD 却高达 300.0,表明生成过程不稳定或异常。相比之下,Wan-R1 在 SR 上可匹配甚至优于这些模型,同时将 SD 降至 10.3,显示其能够持续生成正确且高效的路径。
-
通过视频进行推理优于文本推理
在相同训练数据和设置下,研究团队对视觉语言模型(Qwen2.5-VL-7B)和视频模型(Wan2.2-TI2V-5B)均进行了微调。如表 1 所示,视频模型(Wan-R1)在所有指标和任务上获得显著增益,尤其在 Trap 和 3D 等高难度场景下表现突出。而 Qwen2.5-VL-7B-SFT 的提升仅为中等水平。这突显了通过视频进行推理在学习时间推理和高效路径规划方面,相较于静态 VLM 的优势。
-
测试时扩展(Test-Time Scaling, TTS)对视频模型的影响
测试时扩展(TTS),以自一致性(self-consistency)为代表,在基于文本的推理任务中已显示出强大效果。其核心理念是:复杂推理问题通常存在多条有效解路径,通过多样化采样可以增加收敛到正确答案的概率。
实验结果表明 TTS 显著增强了视频模型在 VTR 任务中的推理能力。通过从不同噪声条件初始化生成,模型能够探索迷宫开放搜索空间中的多条解路径。这种多路径探索有效释放了额外的推理能力,使视频模型生成的轨迹更准确、更可靠,并且比标准单样本推理更接近目标解。
总结与未来展望
在本工作中,研究团队迈出了评估视频模型能否通过视频生成进行推理的重要一步。同时提出了 VR-Bench,一个以迷宫求解任务为基础的综合基准,用于评估视频模型的空间推理能力。
实验结果表明,经过微调的视频模型在空间推理方面表现出强大的能力,并且在各项指标上持续超越领先的视觉语言模型(VLMs)。此外分析还揭示了类似于语言模型中自一致性(self-consistency)的测试时扩展效应(test-time scaling effect),凸显了基于视频的推理具有良好的可扩展潜力。
尽管 VR-Bench 提供了一个专注且严谨的空间推理测试平台,但目前其任务主要集中在迷宫类型。未来的 VR-Bench 将探索更广泛、更具挑战性的推理场景。

















 1988
1988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









