




近期,谷歌发布了新一代大模型Gemini 3.0,被视为谷歌重回AI第一阵营的关键里程碑。司南OpenCompass在第一时间对Gemini 3.0进行了全方位的能力评测(评测版本号Gemini-3-Pro-Preview)。
评测结果显示,其在通用任务和专业学科任务上、单模态场景和多模态场景上均展现出断层式领先。这一结果不仅验证了技术架构的颠覆性升级,更预示着AI产业的竞争焦点,已从单一模型的性能比拼,全面转向以原生多模态、深度推理和生态整合为核心的综合实力较量。
司南OpenCompass对Gemini-3-Pro-Preview的通用文本能力、学科专业文本能力、通用多模态能力、学科专业多模态能力进行了评测,具体结果如下图所示。
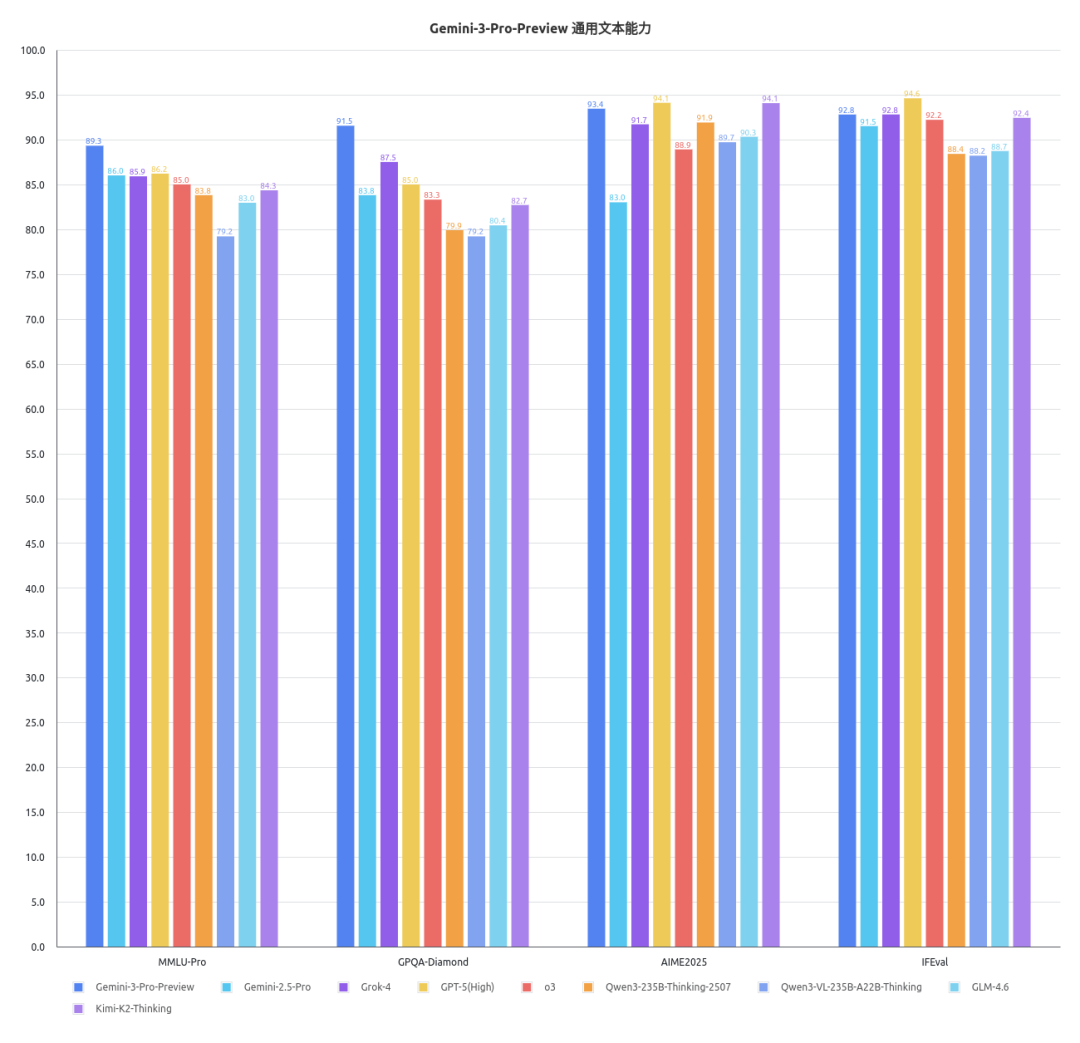
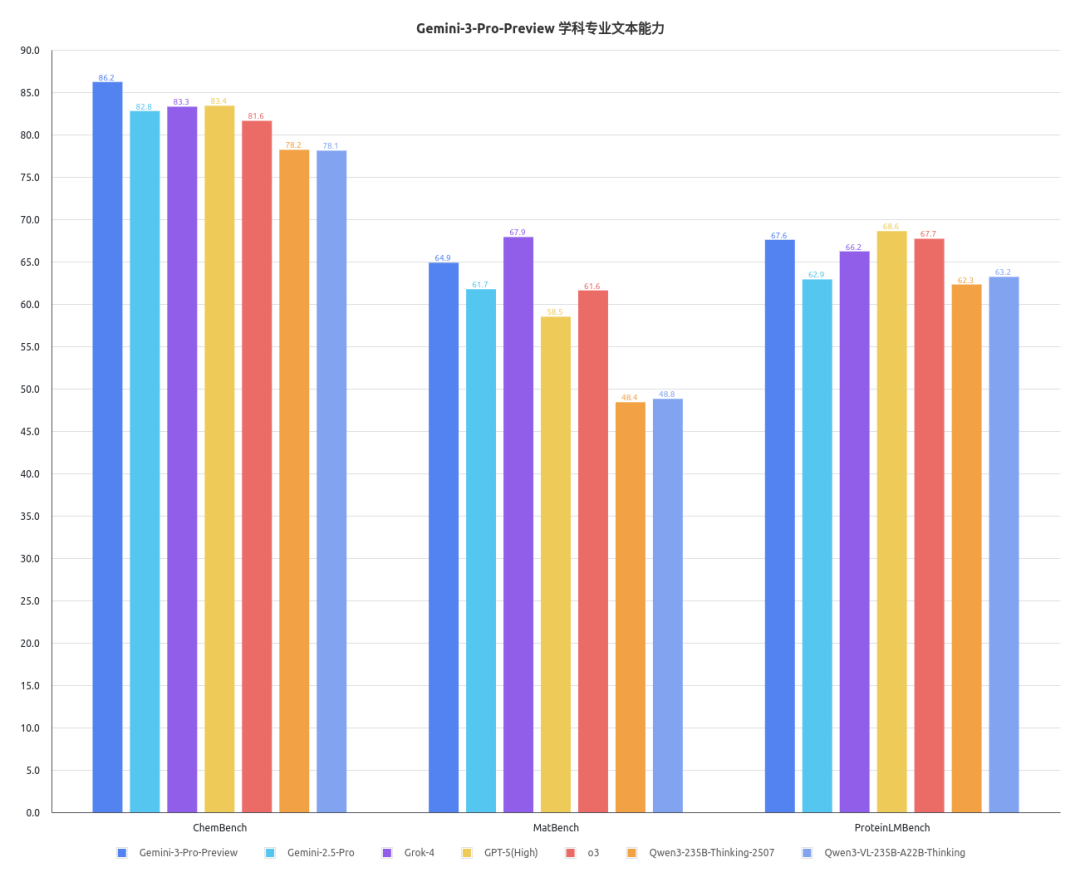
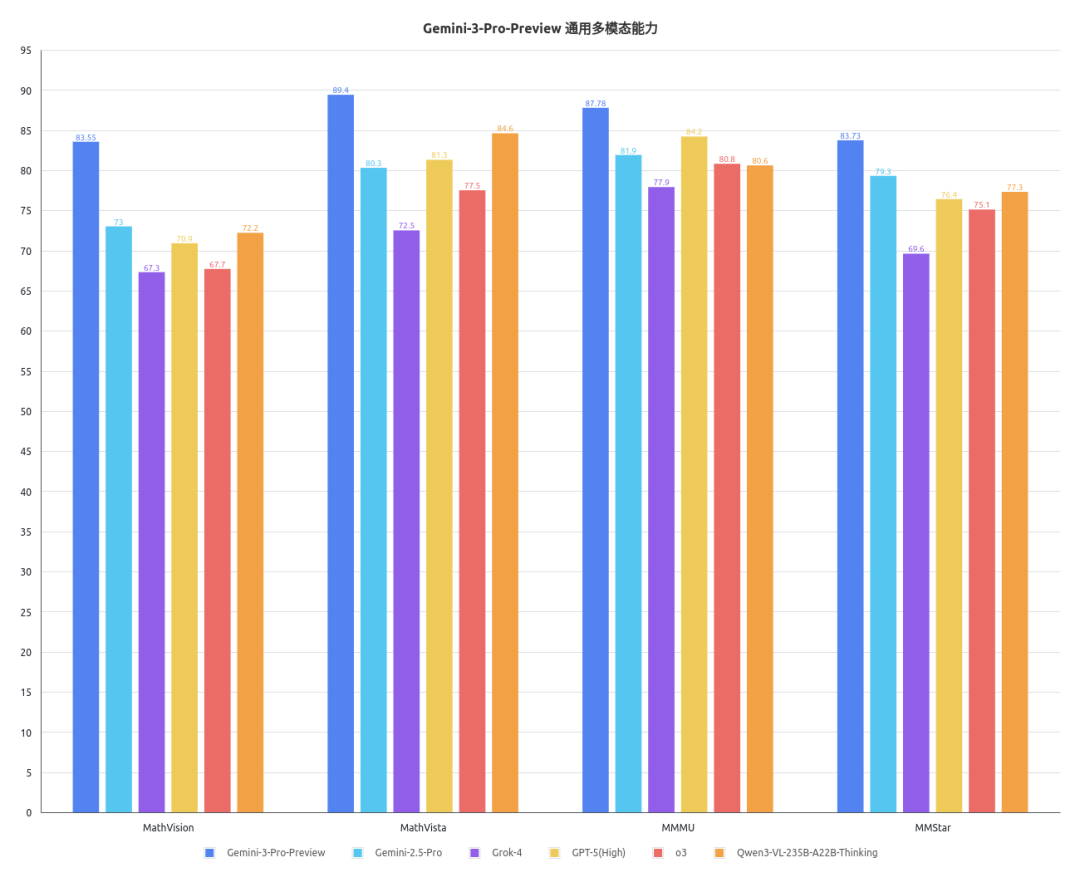
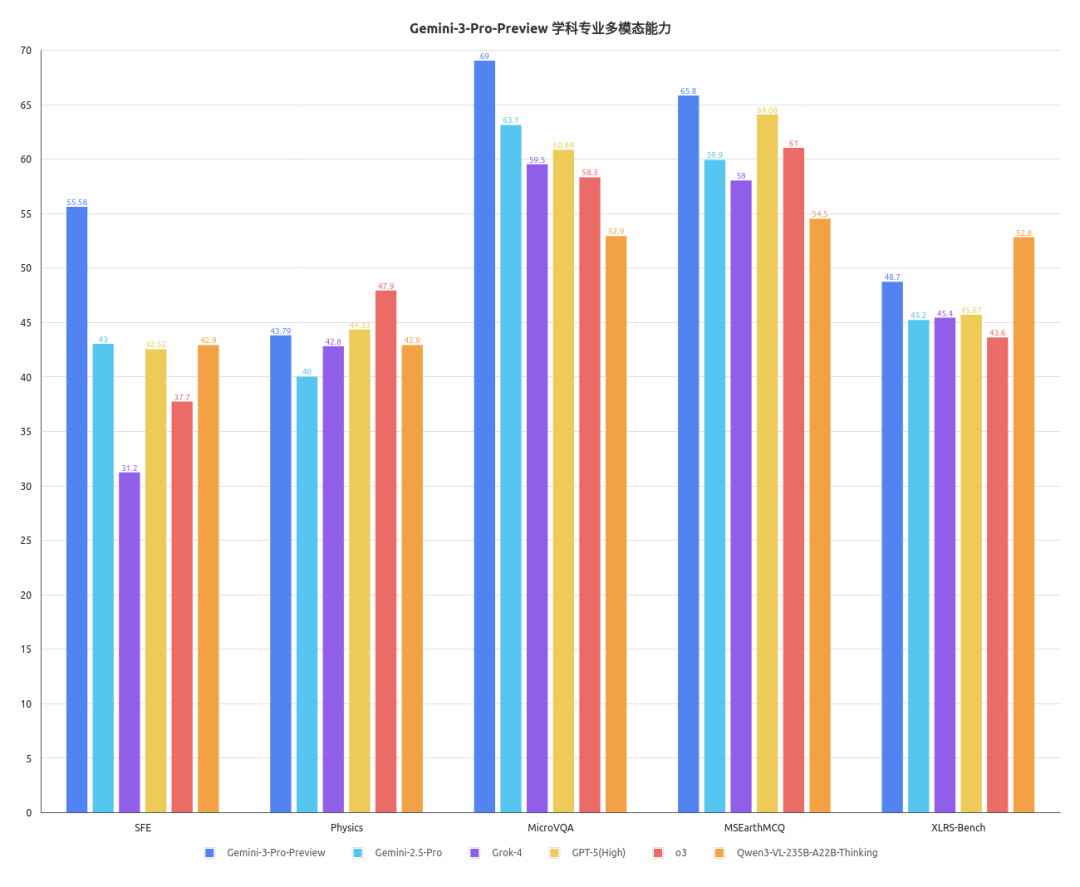
根据以上结果可以发现,相较于业内现有的顶尖商用模型及社区开源模型,Gemini-3-Pro-Preview在通专多维能力上展现出了全方位的领先。
通用基准方面,Gemini-3-Pro-Preview在MMLU-Pro、GPQA-Diamond、MathVision、MMStar等多个基准上的表现显著领先其他模型,展现出了超越现有标杆的通用认知与推理能力。
学科专业基准方面,此模型同样在ChemBench、SFE、MicroVQA等基准上取得了极高的分数,展现出了将强大通用能力精准灌注到学科专业垂直领域的卓越应用潜力和科研潜力。
综上所述,Gemini 3.0的全面领先态势揭示了一个关键趋势:大模型的竞争重心,正转向构建更深层、更可靠、更能无缝融入并赋能复杂真实任务的全方位技术体系。Gemini 3.0在多项基准上实现的突破也意味着大模型综合能力的一次拓展,预示着人工智能在参与未来科学探索、工程实践与创造性工作等方面,正逐步展现出更为实质性的应用潜力。
更多详细内容,请参考后续的官网榜单更新:https://rank.opencompass.org.cn/home
司南 Daily Benchmark 专区全新上新!
-
AI 评测论文“追更神器”
-
每日更新最新 AI 评测方向论文
-
每篇论文都支持 AI 智能解读
查看更多最新 AI 评测论文,欢迎访问:


















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









