



在AI领域,训练大规模模型常常需要庞大的计算资源和巨额的成本。然而,近期,加州大学伯克利分校的研究团队通过开发一款1.5B参数的DeepScaleR模型,并通过强化学习(RL)微调,成功超越了OpenAI的o1-preview。在AIME 2024等数学竞赛中,DeepScaleR展现了惊人的推理能力。这一突破引发了学术界对小型模型潜力的新一轮热议。
突破性成就:1.5B小模型挑战大模型
传统上,AI领域普遍认为,只有大规模的预训练模型才能在数学推理和复杂任务中取得优异表现。然而,伯克利团队的研究颠覆了这一观念。通过精巧的训练方法和高质量的数学数据集,他们在1.5B参数的小模型上成功应用了强化学习,提升了推理能力,并超越了OpenAI的o1-preview。
这一成就验证了“小而强”这一理念:在特定领域内,小型模型通过创新的训练策略也能释放出强大的潜力。
DeepScaleR的创新训练方法:循序渐进,逐步突破
DeepScaleR的成功不仅在于其小模型的高效性,更在于其独特的训练方法。这种方法突破了传统大规模预训练模型的限制,采用了渐进式强化学习策略,逐步引导模型提高推理能力。
1. 迭代式上下文扩展:从短到长,逐步加深推理深度
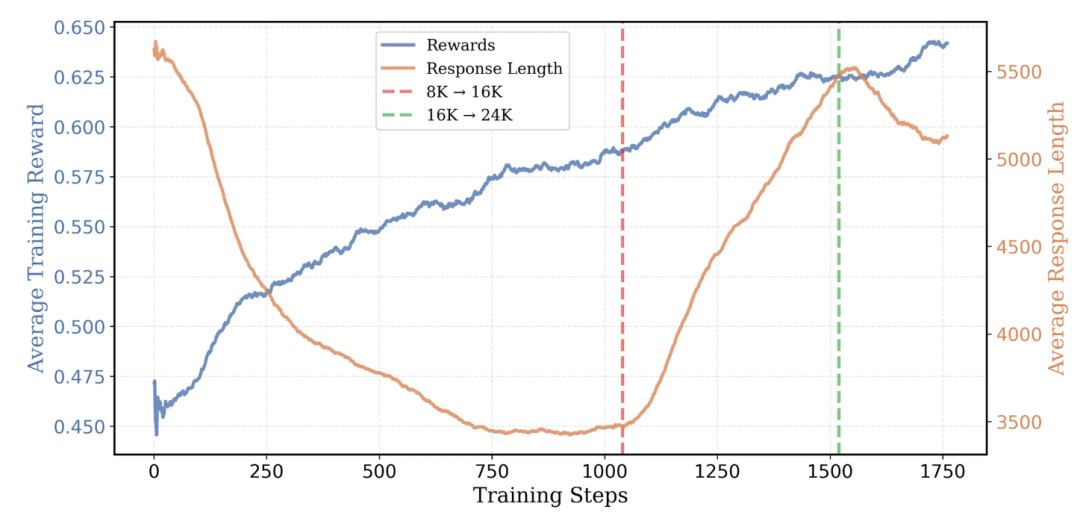
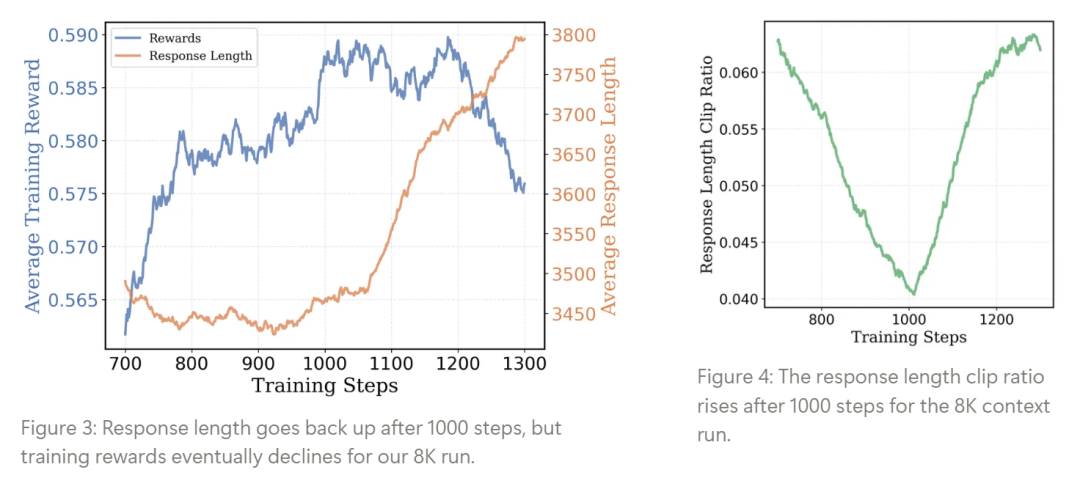
DeepScaleR的训练策略基于迭代式上下文扩展。与直接训练大上下文长度的传统方法不同,研究团队选择了从较短的上下文开始,逐步扩大模型的推理空间。模型的初始阶段处理的是8K字符长度的题目(类似于高中生的作业),随着模型推理能力的提升,逐渐扩展到16K字符(挑战性更高的题目),最终提升到24K字符,这种逐步扩展的策略能够有效避免过早增加复杂性对模型训练的负面影响。
这种方法的核心理念在于:让模型首先掌握较短的、较简单的推理过程,再通过扩展上下文长度来挑战更复杂的数学问题。这一策略帮助模型逐步构建了自己的推理路径,避免了“信息过载”,让模型能够高效地消化和理解复杂的数学问题。
2. 强化学习奖励机制:纯粹的正确性驱动
DeepScaleR采用了非常简洁而有效的强化学习奖励机制——1分奖励正确答案,0分奖励错误答案。这一方式避免了奖励滥用的问题,确保了模型只会在给出正确答案时获得奖励。与传统强化学习中可能使用的“过程奖励”不同,DeepScaleR使用了结果奖励模型(ORM),即只关心最终结果的正确性而非中间步骤。这种方法在数学推理任务中尤其有效,因为数学推理的目标是最终给出正确的答案,而中间过程的正确性往往不能直接映射为最终结果。
这种纯粹的二进制奖惩机制实际上更加符合数学的严谨性:没有中间地带,只有正确与错误,这种奖励方式使得模型能够专注于解决问题的核心,避免了过多的“冗余”推理。
3. 小模型大突破:高效利用计算资源
尽管DeepScaleR只有1.5B的参数,但它的训练效率远超预期。整个训练过程只消耗了3,800 A100 GPU小时,这意味着模型的训练成本仅为约4,500美元。这与传统的大规模预训练模型相比,显得非常经济高效。例如,在使用大量参数和上下文的传统大模型训练时,训练成本通常会达到数百万美元,甚至更多。DeepScaleR的成功表明,小模型同样可以通过创新的训练方法获得强大的推理能力,而不需要庞大的计算资源。
这种训练的高效性得益于两大因素:一是强化学习的高效利用,二是迭代式上下文扩展,这使得训练过程更加专注于模型的推理能力,而非大量计算。
卓越性能:超越o1-preview,挑战数学竞赛
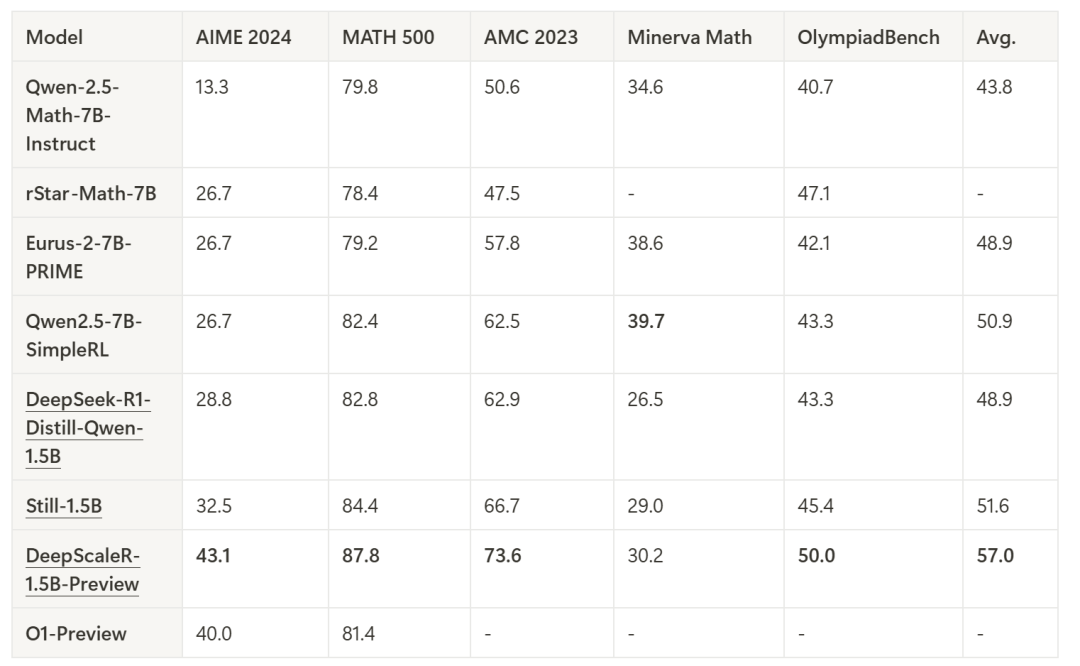
为了评估DeepScaleR的性能,研究团队将其与多个主流模型进行了对比,包括基础的DeepSeek-R1-Distilled-Qwen-1.5B和来自学术界的rSTAR-Math-7B、Eurus-2-7B-PRIME、以及Qwen2.5-7B-SimpleRL等模型。
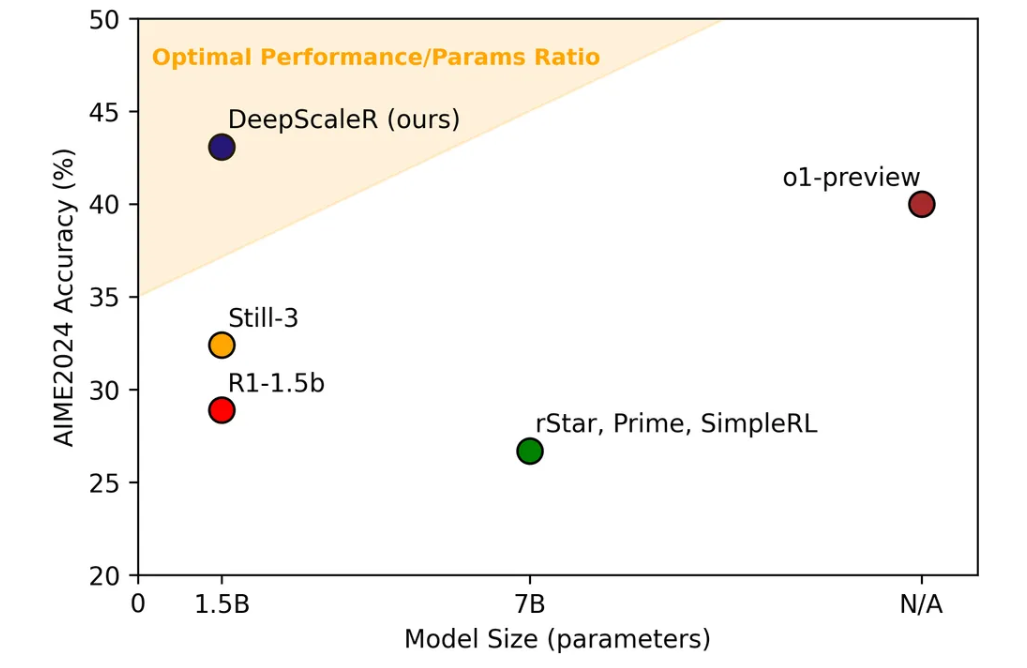
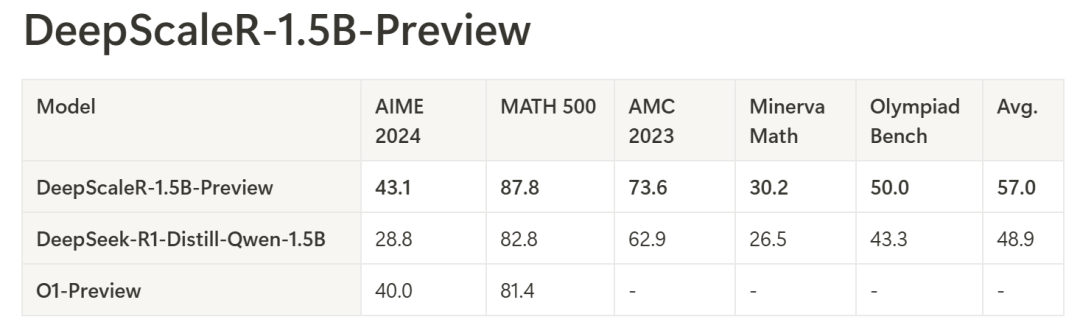
通过对比可以看出,DeepScaleR-1.5B-Preview在AIME 2024、MATH 500和AMC 2023等多个数学竞赛测试中,表现出色。尤其是在AIME 2024测试中,DeepScaleR的Pass@1准确率达到了43.1%,比基础模型提升了14.4%,这一成绩超越了OpenAI的o1-preview,展示了其出色的推理能力。
在所有的测试中,DeepScaleR的平均性能也表现极为出色,达到了57.0%,远超其他基准模型,尤其是在MATH 500和AMC 2023测试中,DeepScaleR均取得了87.8%和73.6%的卓越成绩。
模型下载
OpenCSG社区:https://opencsg.com/models/agentica-org/DeepScaleR-1.5B-Preview

















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









