



在人工智能领域,模型的性能不断突破极限,推动着技术的发展。最近,斯坦福大学李飞飞团队推出了一个突破性的AI模型——S1-32B。该模型结合了样本效率与前沿的推理能力,证明了即使在计算资源有限的情况下,也能实现高性能的推理模型。这一创新有望重塑我们对语言模型和AI推理的理解。
S1-32B:推理模型的新纪元
人工智能语言模型传统上依赖于海量数据和强大的计算资源。例如,OpenAI的GPT-4训练成本高达数百万美元,而像DeepSeek-R1这样的模型则依赖于数十万个样本进行微调。然而,S1-32B模型展示了,使用仅仅1000个高质量样本,也能取得令人惊叹的成果。
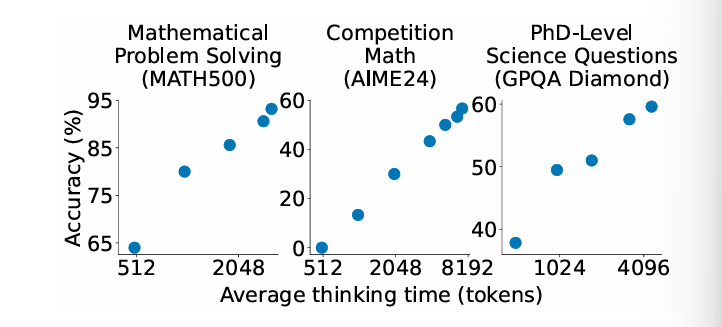
S1-32B通过采用一种名为测试时扩展(Test-time Scaling)的技术,在推理阶段对计算量进行增强,从而提升其推理能力。在多个数学和科学竞赛任务中,S1-32B在AIME24(美国数学邀请赛)、MATH500等竞赛中,超越了OpenAI的o1-preview模型,展现出了卓越的推理性能。
S1-32B的核心亮点:简洁、高效、开源
1. 小样本训练:仅用1000个高质量样本
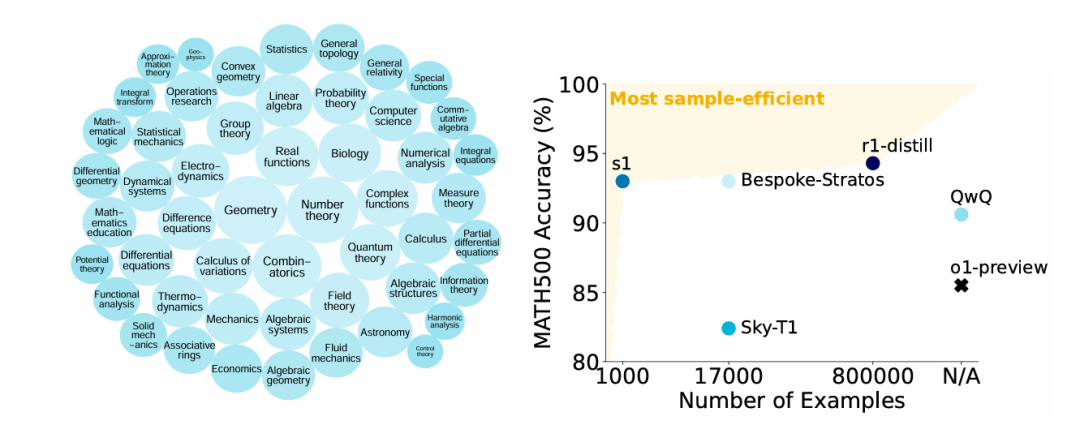
与传统的大型AI模型不同,S1-32B通过仅使用1000个精心挑选的高质量样本进行训练,展示了其在小样本下依然能够实现卓越性能的潜力。团队从59,000个候选问题中筛选出最具挑战性、代表性强且涵盖多个领域的问题,确保训练数据具有高度的多样性和难度。这些样本不仅涉及数学、物理、化学等学科,还注重问题的推理深度,避免了使用过于简单或冗余的样本。
这种精确筛选的数据集,帮助模型避免低效学习,并有效地提升了推理能力。相比于那些需要数百万条样本才能训练成功的传统大模型,S1-32B的1,000个样本训练数据更加节省资源,且更具针对性。
2. 创新的“预算强制”(Budget Forcing)技术
S1-32B的另一大创新是引入了预算强制技术,它为测试时推理提供了极大的灵活性与可控性。这种方法在推理过程中精确控制计算量,确保模型根据实际需要进行推理,避免浪费计算资源。
-
限制思考时长:如果模型的推理过程过长(超出了预设的令牌数),系统会通过插入“结束思考”标记来强制模型立即给出答案。这有效避免了模型在推理过程中陷入冗长的思维循环,从而提高了推理效率。
-
延长思考时间:当模型过早终止思考时,系统会插入“Wait”等提示词,强制模型继续思考并修正可能的错误。这种方式通过延长思考时间,使模型有更多机会进行深层次的推理,从而改善最终的答案。
通过这两种方式,S1-32B能够根据推理需求灵活调整计算量,确保最佳推理结果的生成,提升了模型的精度和推理能力。

3. 高效训练与低成本
S1-32B的训练过程使用了仅16张NVIDIA H100 GPU,训练时间仅为26分钟,并且整个过程的计算成本不到50美元。这相较于需要数百万美元成本的传统大型AI模型而言,极大地降低了训练开销。这一高效训练方法,结合了精确的数据选择和创新的推理优化策略,为AI模型的训练与推理开辟了新天地。
高效的推理能力:超越o1-preview,媲美DeepSeek-R1
尽管只用了1000个训练样本,但S1-32B在多个推理任务中的表现却令人惊艳:
-
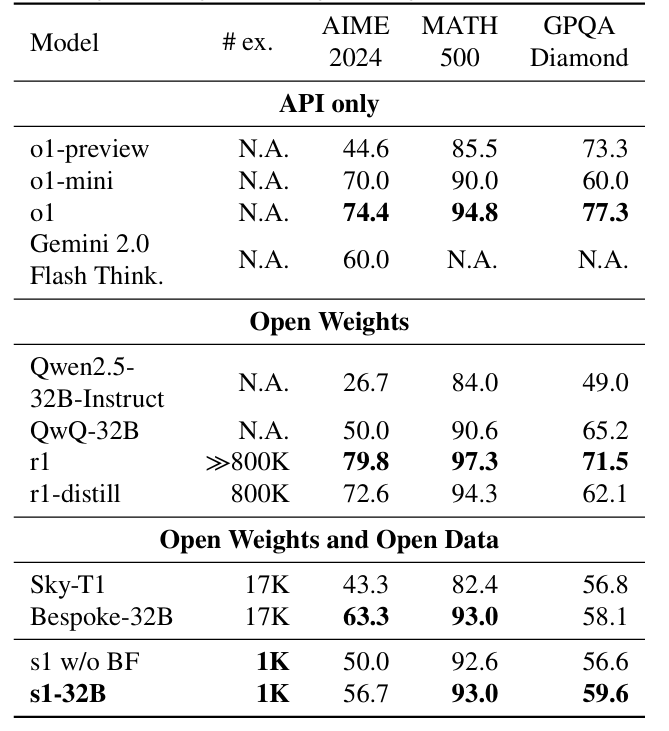
在AIME24(美国数学邀请赛)上,S1-32B的准确率比OpenAI的o1-preview高出了27%,这表明该模型在高难度数学问题中的推理能力得到了显著提升。
-
在MATH500和GPQA任务中,S1-32B的表现接近甚至超越了主流的开源模型,如Gemini 2.0,在多个领域展示了强大的跨学科推理能力。
-
S1-32B甚至在与DeepSeek-R1(使用了80万样本训练的模型)进行比较时,也展示出了相当强的竞争力,达到了后者约70%的性能,证明了其在有限数据下的高效学习能力。
通过采用预算强制技术,S1-32B不仅提升了推理能力,还避免了大规模数据训练的高成本。模型在测试时的扩展能力是其突出的特点,这种方法使得模型能够灵活调节推理深度,实现更强的推理表现。
模型下载
OpenCSG社区:https://opencsg.com/models/simplescaling/s1-32B


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









