



OpenCSG赋能顶尖高校打造高性能轻量化大模型

面对大语言模型(LLM)训练中普遍存在的“数据鸿沟”与资源壁垒,中国人民大学高瓴人工智能学院(RUC-GSAI)致力于在有限的学术资源下,开发一款性能卓越且可复现的开源基础模型。通过将其复杂的数据工程管线与 OpenCSG 的 Fineweb-edu-chinese-V2.1 高质量中文预训练数据集深度整合,RUC-GSAI 团队成功训练出 YuLan-Mini 模型。该模型以 2.42B 的参数规模,仅使用 1.08T tokens 的数据量,便在多个关键基准(尤其在数学和代码领域)上达到了与使用超过十万亿(10T+)tokens 训练的工业界模型相媲美的顶尖性能。此案例有力地证明了,高质量、大规模的开放数据集是提升模型“数据效率”和推动前沿AI研究的关键基石,而OpenCSG正为此提供了不可或缺的动力。
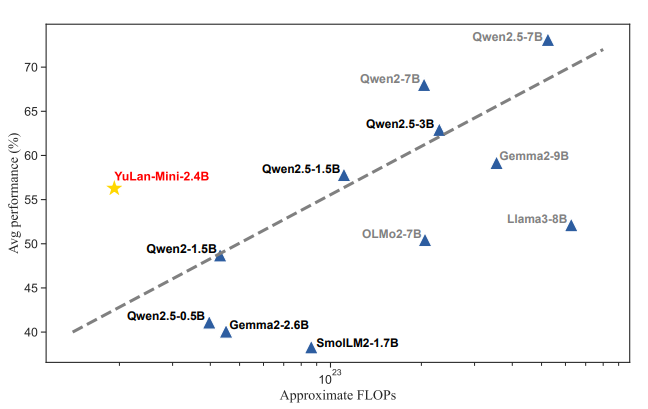
YuLan-Mini 与其他基础模型的性能比较,该比较基于在八个基准测试(GSM8K, MATH-500, HumanEval, MBPP, MMLU, ARC-Challenge, HellaSwag, 和 CEval)上的平均得分
客户背景
中国人民大学高瓴人工智能学院 (RUC-GSAI) 是中国在人工智能领域的顶尖学术机构之一,致力于推动AI技术的基础理论研究与创新应用。其团队由赵鑫教授和文继荣教授领导,汇聚了众多在自然语言处理和AI领域的优秀研究者。作为一个学术机构,RUC-GSAI团队不仅追求技术上的卓越,更肩负着推动AI技术开放、透明和可复现的使命,旨在为开源社区贡献兼具高性能与高效率的基础模型。
项目目标:在高校级算力限制下(56张A800 GPU),开发参数规模2.4B的高效语言模型,要求:
- 性能对标商用3B级模型(如LLaMA-3.2B、Qwen1.5B)
- 训练数据完全开源合规,支持学术复现
- 解决小模型训练不稳定性与长上下文支持难题
面临的挑战
在启动 YuLan-Mini 项目之初,RUC-GSAI团队面临着学术界在LLM研发中普遍存在的严峻挑战:
- 高质量中文数据稀缺:尽管互联网上存在海量中文数据,但普遍质量低下、噪音繁多。而工业界巨头所使用的经过精细清洗的TB级高质量语料库通常是专有资产,学术界难以获取,这直接限制了模型能力的天花板。
- 数据效率要求极致:与拥有海量计算资源的科技公司不同,学术实验室的算力预算有限。他们无法通过“堆数据”的方式来提升模型性能,必须寻求数据效率最大化的路径,即用更少、更优质的数据训练出更强的模型。
- 模型训练的“黑箱”问题:工业界发布的模型虽多,但其核心的训练数据构成和详细的训练过程往往不被公开。这使得学术研究难以进行深入的归因分析和技术复现,阻碍了科学的进步。
团队的核心挑战是:
如何在有限的资源下,通过构建一套极致数据高效的管线,训练出能够与工业界模型相抗衡的、完全开放的中文基础模型?
解决方案
1. 高质量中文教育数据引擎
为了应对上述挑战,RUC-GSAI团队的数据策略核心是“质量优先”。在构建其总计约1.08T tokens的预训练语料库时,他们选择将 OpenCSG 发布的 Fineweb-edu-chinese-V2.1 数据集 作为其高质量中文语料的核心组成部分。
Fineweb-edu-chinese-V2.1 是一个专为LLM预训练设计的、规模达 420B tokens 的高质量中文数据集。其关键特性完美地契合了YuLan-Mini项目的需求:
- 高质量与高纯度:该数据集借鉴了业界领先的FineWeb过滤框架,通过基于模型的打分器(Qwen2.5-14b-instruct)对海量原始网页数据进行“教育价值”评估,移除了广告、导航、低质内容等噪音,保留了结构清晰、信息丰富的文本;MinHash算法实现文档级去重,冗余率<0.3%;补充93.8B数学语料与108B通用中文文本,覆盖多学科知识。
- 大规模与多样性:数据集整合了多个大型中文语料源,并通过严格的去重和清洗流程,确保了其内容的广度和多样性,为模型提供了坚实的通识知识基础。
- 开放与可及性:作为OpenCSG社区的开源项目,该数据集完全公开,为学术研究提供了透明、可复现的数据基石,打破了高质量中文语料的获取壁垒。
2. 创新训练架构
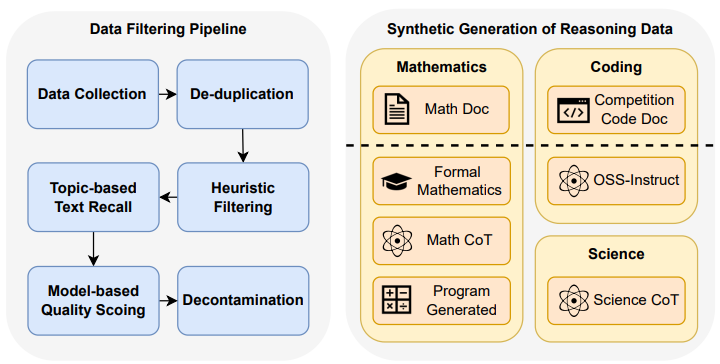
- 高效工程实现
- 训练框架:DeepSpeed ZeRO-2 + FlashAttention-2 + bfloat16
- 硬件利用率:MFU达51.57%,较基线提升30%
- 开源协作:完整公开数据配方与28K上下文checkpoint
实施过程
RUC-GSAI团队将 Fineweb-edu-chinese-V2.1 深度整合进其复杂而精细的数据管线中:
- 作为中文基础语料:在YuLan-Mini的1.08T训练数据中,108B的中文数据是关键组成部分。Fineweb-edu-chinese 提供了这部分语料的高质量基础,确保模型在中文理解和生成能力上有一个高起点。
- 与其他数据协同:团队将来自OpenCSG的数据与英文网页数据(如FineWeb-Edu)、代码数据(如the-stack-v2)、数学数据以及团队自行合成的大量推理数据(如形式化数学、长思维链等)进行动态混合。
- 融入课程学习:在长达27个阶段的课程学习中,Fineweb-edu-chinese 语料的比例被精心设计和调度,与数学、代码等专业领域数据协同作用,共同塑造了模型全面而强大的能力。
成果展示
通过采用以OpenCSG数据集为核心的高效数据策略,YuLan-Mini项目取得了突破性成果:
- 极致的数据效率:YuLan-Mini仅用 1.08T tokens 就达到了业界领先的性能水平,而同等规模的竞品模型(如Qwen2.5系列)据报道使用了高达 18T tokens 的数据。这证明了其数据效率是行业顶尖水平的 10倍以上。
- 卓越的模型性能:在多个权威基准测试中,YuLan-Mini(2.42B)的表现全面超越了众多参数量更大、训练数据更多的模型。尤其在 数学推理(MATH-500)和代码生成(HumanEval)等高难度任务上,YuLan-Mini展现了同量级模型中的最强性能。
- 推动开放科学的典范:YuLan-Mini项目不仅发布了高性能的模型检查点,更重要的是,它 完全公开了其训练数据构成和技术细节,为全球AI研究社区提供了一个可复现、可借鉴的高效训练范本,有力地推动了AI领域的开放与协作。
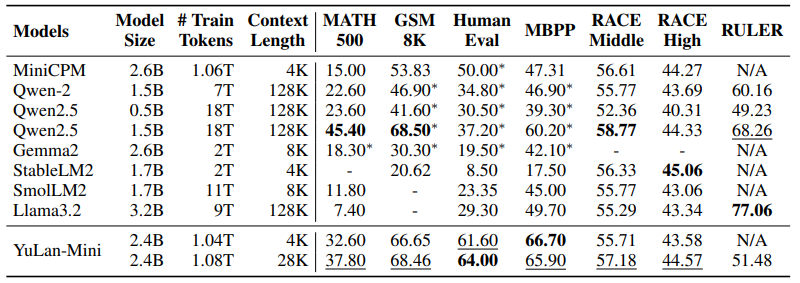
性能对比:
在数学、代码和长上下文基准测试上的性能表现。带星号(*)标记的结果引用自其官方论文或报告。最好和次好的结果分别用粗体和下划线表示:
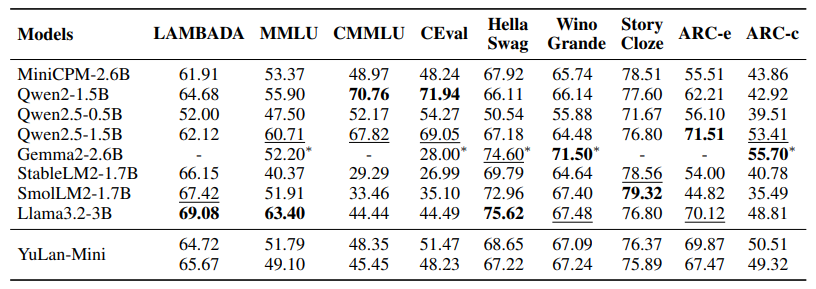
在常识推理基准测试上的表现。带星号(*)标记的结果引用自其官方论文或报告。
YuLan-Mini的成功只是一个开始。RUC-GSAI团队计划在此基础上,继续开发指令微调版本,并探索更先进的模型架构和训练方法。随着AI研究的不断深入,对更大规模、更多样化、更高质量的开放数据的需求将与日俱增。
OpenCSG通过 高质量垂直数据集 + 尖端训练技术栈,助力高校突破轻量化模型性能瓶颈,验证了开源数据驱动模型高效训练的可行性,为教育、边缘计算等场景提供新一代基础模型解决方案。
数据下载
OpenCSG:
https://opencsg.com/datasets/AIWizards/Fineweb-Edu-Chinese-V2.1
hf:
https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









