




公共资源速递
6 个公共数据集:
* LEXam 法律推理基准数据集
* Llamg-Nemotron 推理数据集
* DeepTheorem 定理证明数据集
* Eye Detection 眼睛检测数据集
* OpenCodeReasoning 编程推理数据集
* GeneralThought-430K 大规模推理数据集
2 个公共模型:
* MiniMind2
* dots.llm1.inst
11 个公共教程:
深度估计 * 2
语音生成与理解 * 2
多模态理解与生成 * 7
访问官网立即使用:openbayes.com
公共数据集
1. LEXam 法律推理基准数据集
LEXam 数据集包含来自瑞士苏黎世大学法学院的 340 场不同课程、不同级别(本科与硕士)的真实法律考试,覆盖瑞士、欧洲及国际法,以及法学理论和法律历史领域。
* 直接使用:
2. Llamg-Nemotron 推理数据集
Llama-Nemotron 数据集包含数学数据约 2,206 万、代码数据约 1,010 万,其余为科学、指令跟随等领域数据,数据由 Llama-3.3-70B-Instruct、DeepSeek-R1、Qwen-2.5 等多模型协同生成,涵盖多样化推理风格与解题路径,满足大规模模型训练的多样性需求。
* 直接使用:
3. DeepTheorem 定理证明数据集
DeepTheorem 数据集包含 12.1 万个 IMO 级别的非形式化定理和证明,涵盖多个数学领域。每个定理-证明对均经过严格注释,旨在通过基于自然语言的非形式化定理证明来增强大型语言模型(LLM)的数学推理能力。
* 直接使用:
4. Eye Detection 眼睛检测数据集
Eye Detection 数据集是一个眼部检测数据集,包含近 2,000 张标注清晰的眼部区域图像,可用于训练 RCNN、YOLO 等目标检测模型,用于追踪和检测眼球区域,该数据集可用于构建白内障检测模型、眼动追踪模型等。
* 直接使用:
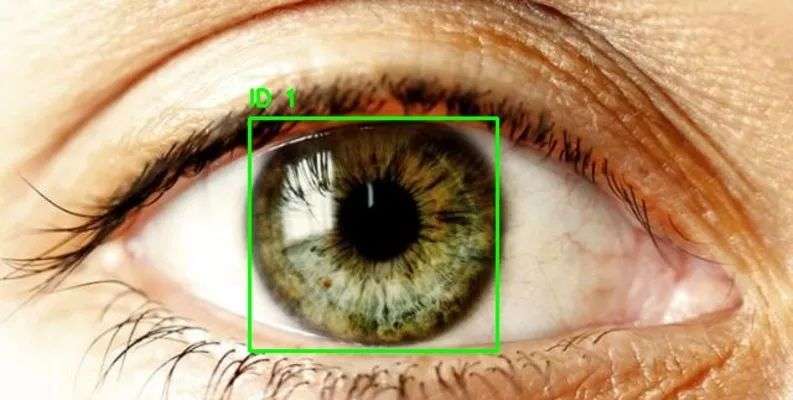
数据集示例
5. OpenCodeReasoning 编程推理数据集
OpenCodeReasoning 数据集包含了 735,255 个样本,覆盖 28,319 道独特的编程题目,是当前最大的推理型编程数据集之一。该数据集旨在为大语言模型(LLMs)提供高质量的编程推理训练数据,推动代码生成与逻辑推理能力的提升。
* 直接使用:
6. GeneralThought-430K 大规模推理数据集
GeneralThought-430K 数据集包含 43 万样本,覆盖数学、代码、物理、化学、自然科学、人文社科、工程技术等领域问题,包含来自多个推理模型的问题、参考答案、推理轨迹、最终答案及其他元数据,以供比较和评估。
* 直接使用:
公共模型
1. MiniMind2
* 发布机构:MiniMind 团队
MiniMind2 初衷是拉低 LLM 的学习门槛,让每个人都能从理解每一行代码开始, 从零开始亲手训练一个极小的语言模型。该项目所有核心算法代码均从 0 使用 PyTorch 原生重构,不依赖第三方库提供的抽象接口。这不仅是大语言模型的全阶段开源复现,也是一个入门 LLM 的教程。
* 直接使用:
2. dots.llm1.inst
* 发布机构:小红书 hi lab
dots.llm1.inst 基于 Mixture of Experts(MoE)架构,总参数量达到 1,420 亿,但在推理时仅激活 140 亿参数,这种设计既保证了模型的强大性能,又提升了推理效率。该模型在 11.2 万亿高质量 token 数据上进行了预训练,并采用了高效的 Interleaved 1F1B 流水并行和 Grouped GEMM 优化技术,显著提升了训练效率。
* 直接使用:
公共教程
深度估计 * 2
1. UniDepthV2:通用单目度量深度估计
UniDepthV2 能够跨域仅从单张图像重建度量三维场景。与现有的 MMDE 范式不同,UniDepthV2 在推理时直接从输入图像预测度量三维点,无需任何额外信息,力求实现通用且灵活的 MMDE 解决方案。
本教程采用资源为单卡 RTX 4090,打开下方链接体验单图重建三维场景。
* 在线运行:
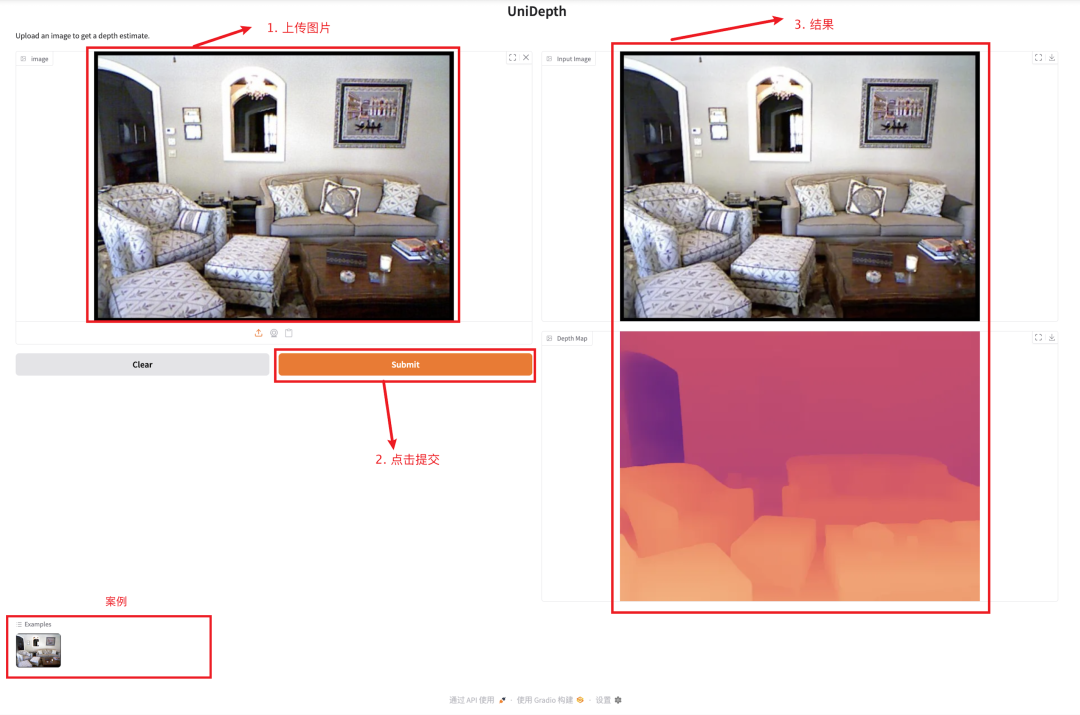
模型示例
2. Distill-Any-Depth:单目深度估计器
Distill-Any-Depth 通过蒸馏算法整合多个开源模型的优势,仅需少量无标签数据即可实现高精度深度估计,刷新了当前 SOTA(State-of-the-Art)性能。
该教程算力资源采用单卡 RTX 4090,打开下方链接上传图片即可实现高精度深度估计。
* 在线运行:
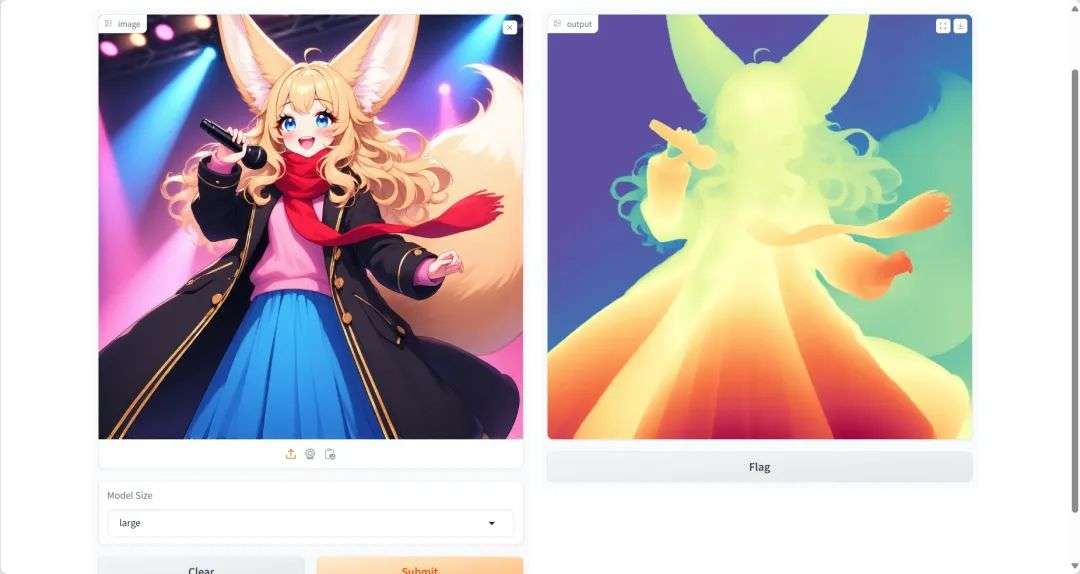
模型示例
语音生成与理解 * 2
1. Kimi-Audio:让 AI 听懂人类
Kimi-Audio-7B-Instruct 模型能够处理各种任务,如自动语音识别(ASR)、音频问答(AQA)、自动音频字幕(AAC)、语音情感识别(SER)、声音事件/场景分类(SEC/ASC)和端到端语音对话,在多项音频基准测试中达到 SOTA 水平。
该教程算力资源采用单卡 A6000,相关数据已配置完成,复制链接到网页,快速处理多音频任务。
* 在线运行: OpenBayes 控制台
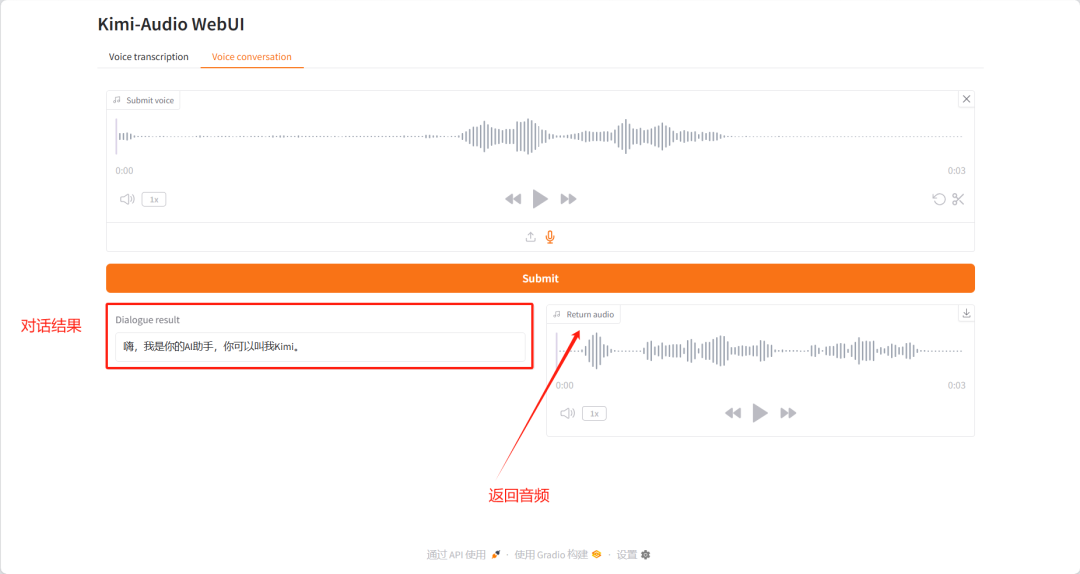
模型界面示例
2. ChatterboxTTS:语音合成 Demo
Chatterbox 是首个支持情感夸张控制的开源 TTS 模型,基于 0.5 亿参数的 LLaMA 架构,使用超过 50 万小时的精选音频数据进行训练,支持多语言和多音色生成,性能超越了 ElevenLabs 等闭源系统。
该教程算力资源采用单卡 RTX 4090,提示词仅支持英文。打开下方链接,快速生成个性化语音。
* 在线运行:
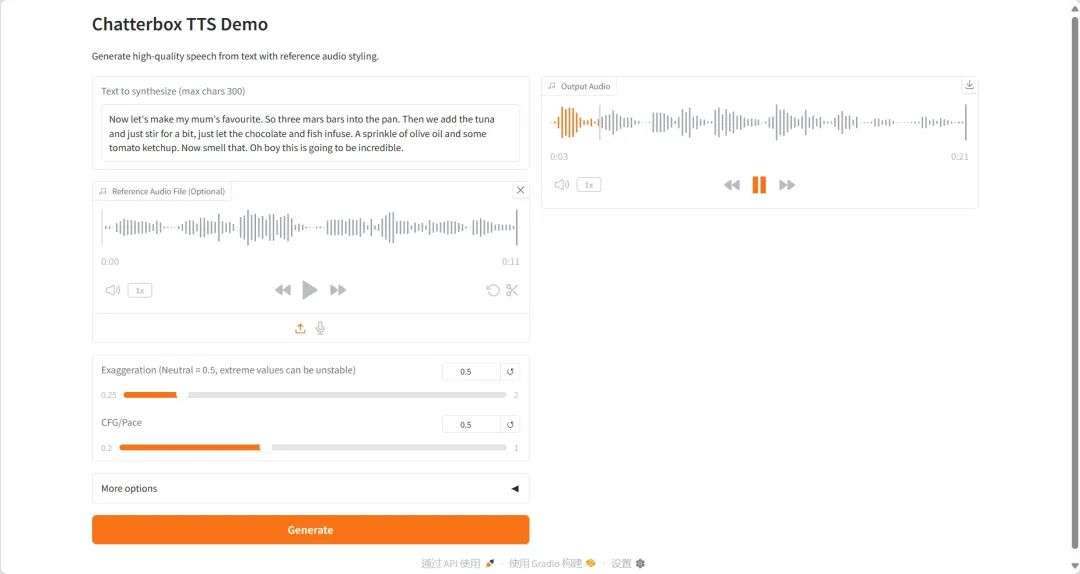
模型界面示例
多模态理解与生成 * 7
1. Flow-GRPO 流匹配模型
Flow-GRPO 开创性融合在线强化学习框架与流匹配理论,在 GenEval 2025 基准测试中取得突破性进展:SD 3.5 Medium 模型组合式生成准确率由基准值 63% 跃升至 95%,生成质量评估指标首次超越 GPT-4o。
本教程采用资源为单卡 RTX 4090,图像生成提示词仅支持英文。复制链接到网页,定制你的个性化图片。
* 在线运行:
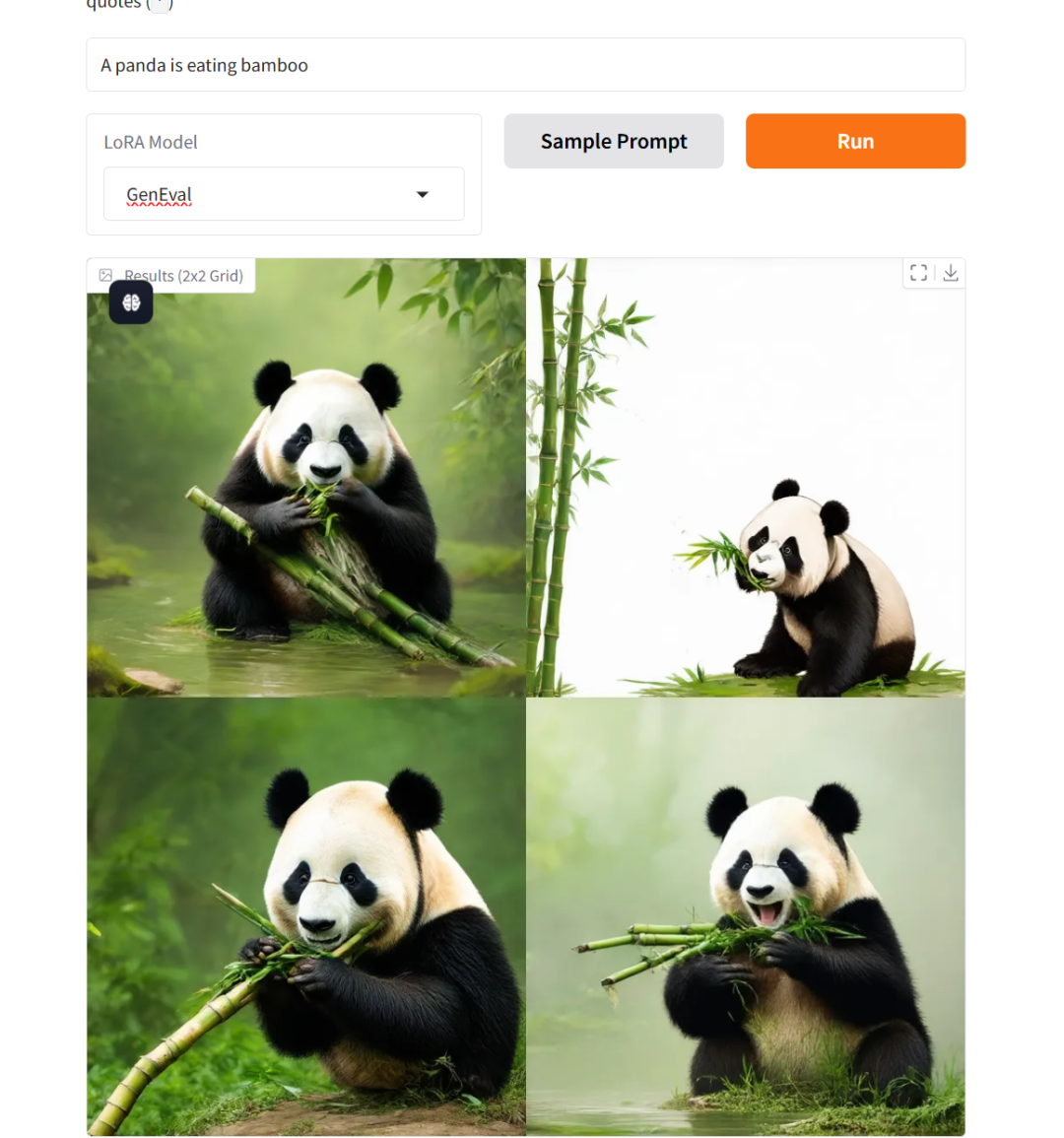
项目示例
2. Step1X-Edit:图像编辑神器
Step1X-Edit 旨在提供与 GPT-4o 和 Gemini2 Flash 等闭源模型相当的性能,模型采用多模态 LLM 来处理参考图像和用户的编辑指令,提取了潜在嵌入并将其与扩散图像解码器集成以获得目标图像。该模型总参数量为 19B(7B MLLM + 12B DiT),具备语义精准解析、身份一致性保持、高精度区域级控制三项关键能力;支持 11 类高频图像编辑任务类型,如文字替换、风格迁移、材质变换、人物修图等。
进入下方链接克隆模型,快速编辑图像。
* 在线运行:
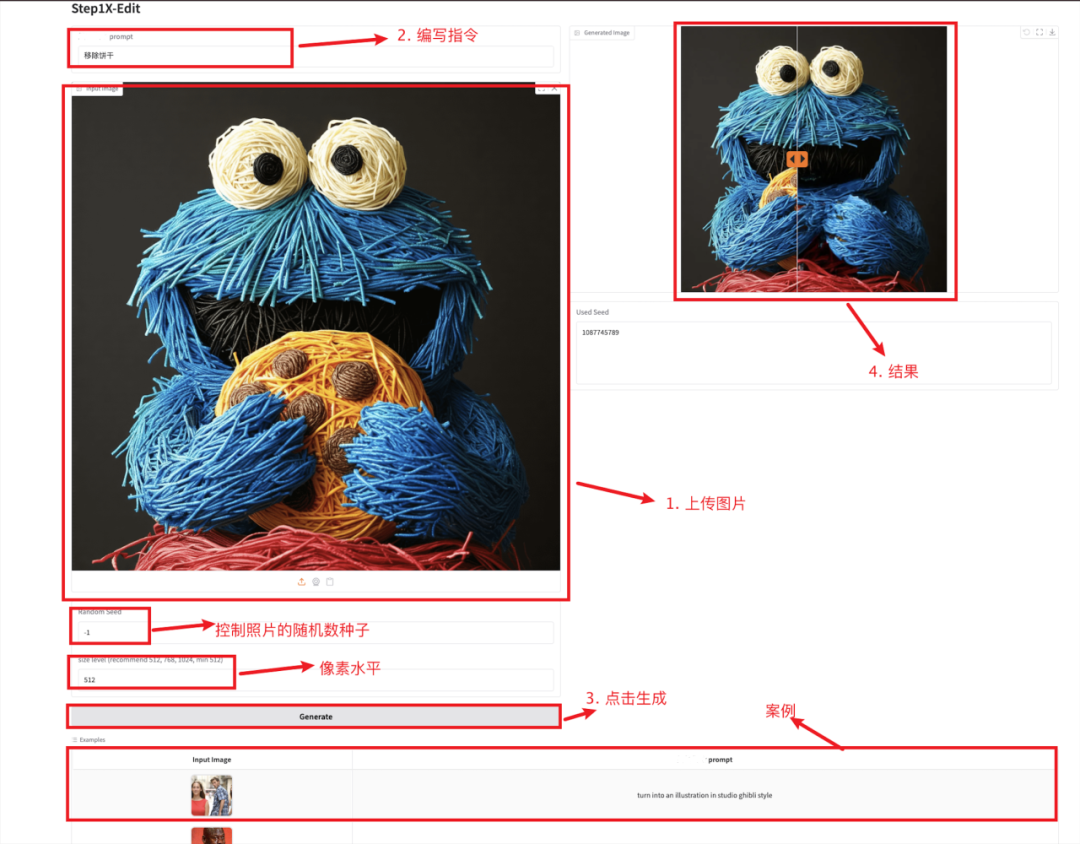
项目示例
3. 一键部署 VideoLLaMA3-7B
VideoLLaMA3 专注于图像与视频理解任务。通过以视觉为中心的架构设计与高质量数据工程,显著提升了视频理解的精度与效率。其轻量化版本(2B)兼顾端侧部署需求,而 7B 模型则为研究级应用提供顶级性能。7B 模型在通用视频理解、时间推理、长视频分析三大任务中均达 SOTA。
进入下方链接启动模型,一键识别图片和视频。
* 在线运行:
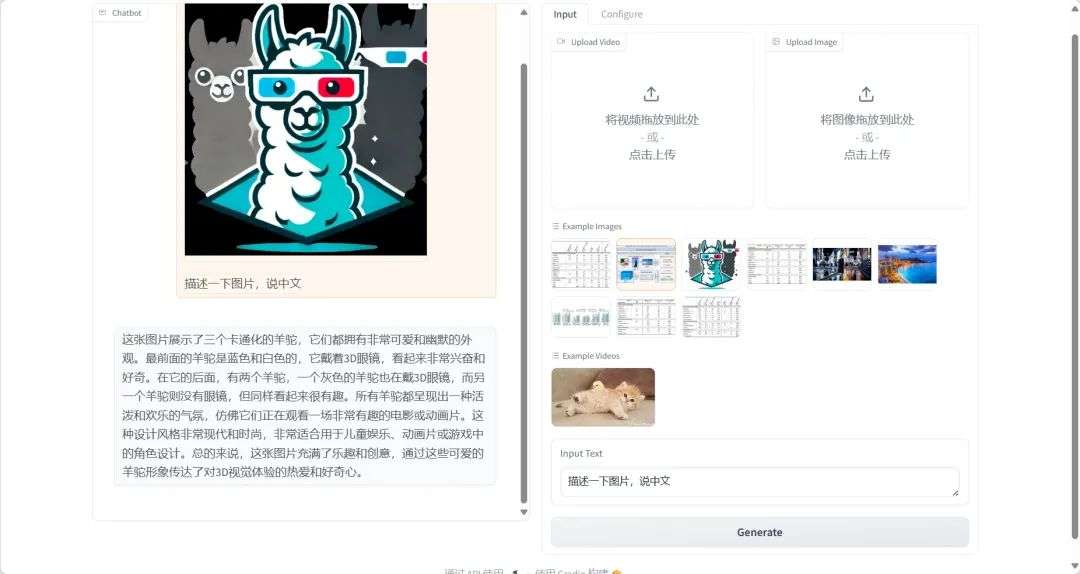
项目示例
4. Vchitect-2.0 视频扩散模型 Demo
Vchitect-2.0 采用了创新的并行 Transformer 架构设计,拥有 20 亿参数,能够根据文本提示生成流畅、高质量的视频内容。
一键克隆启动,开启你的创作之旅。
* 在线运行:
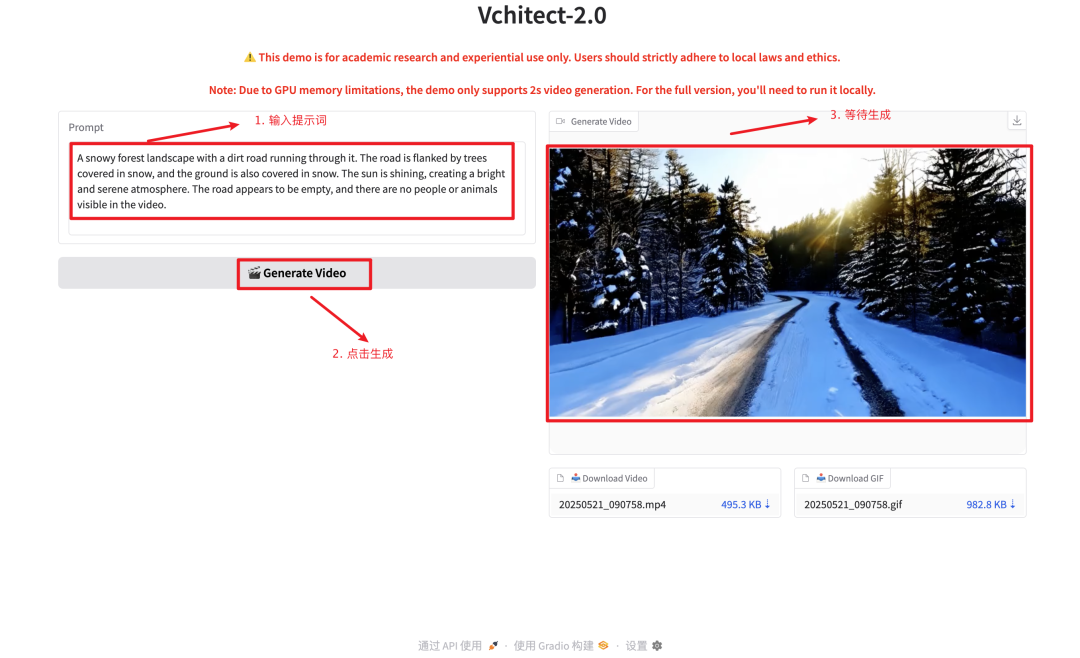
项目示例
5. Sa2VA:实现图像和视频的密集感知理解
Sa2VA 是第一个用于图像和视频密集感知理解的统一模型。与现有的多模态大型语言模型不同,这些模型通常仅限于特定的模态和任务,Sa2VA 支持广泛的图像和视频任务,包括指代分割和对话,只需最少的单次指令微调。
本教程采用资源为单卡 A6000,启动模型快速完成图像识别分割任务。
* 在线运行:
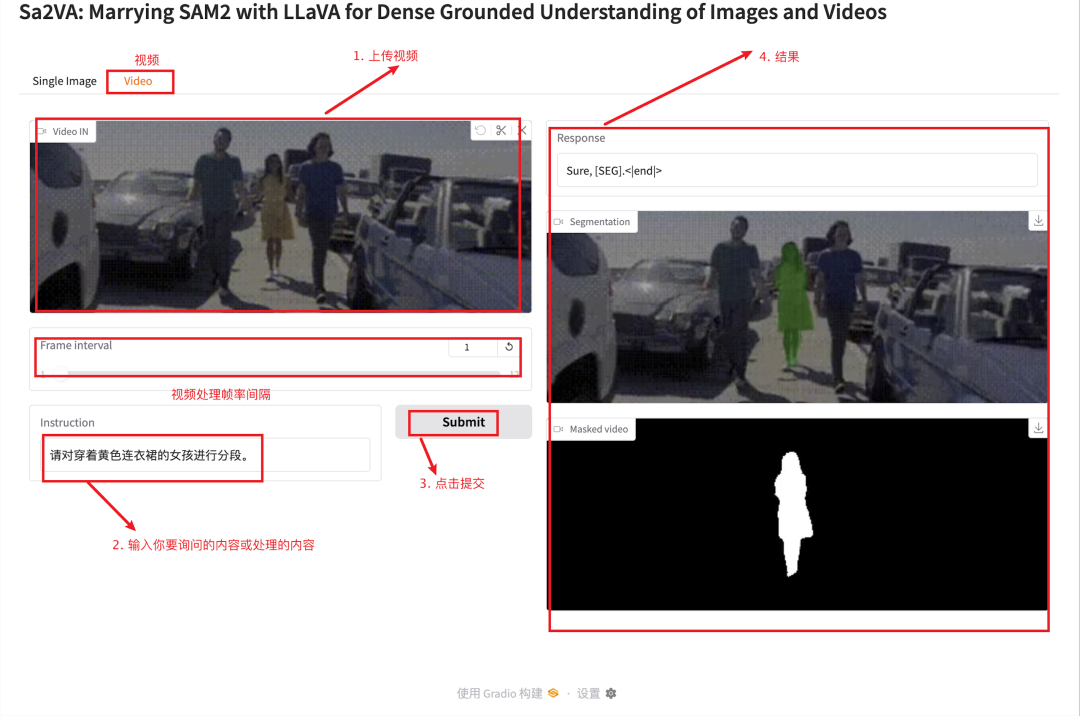
项目示例
6. DescribeAnything「描述一切」模型 Demo
Describe Anything Model(DAM)能够根据用户指定的区域(点、框、涂鸦或蒙版)生成详细的描述。对于视频内容,只需在任意帧上标注区域即可获得完整的描述。
本教程采用资源为单卡 RTX 4090,进入下方链接,快速进行目标识别。
* 在线运行:
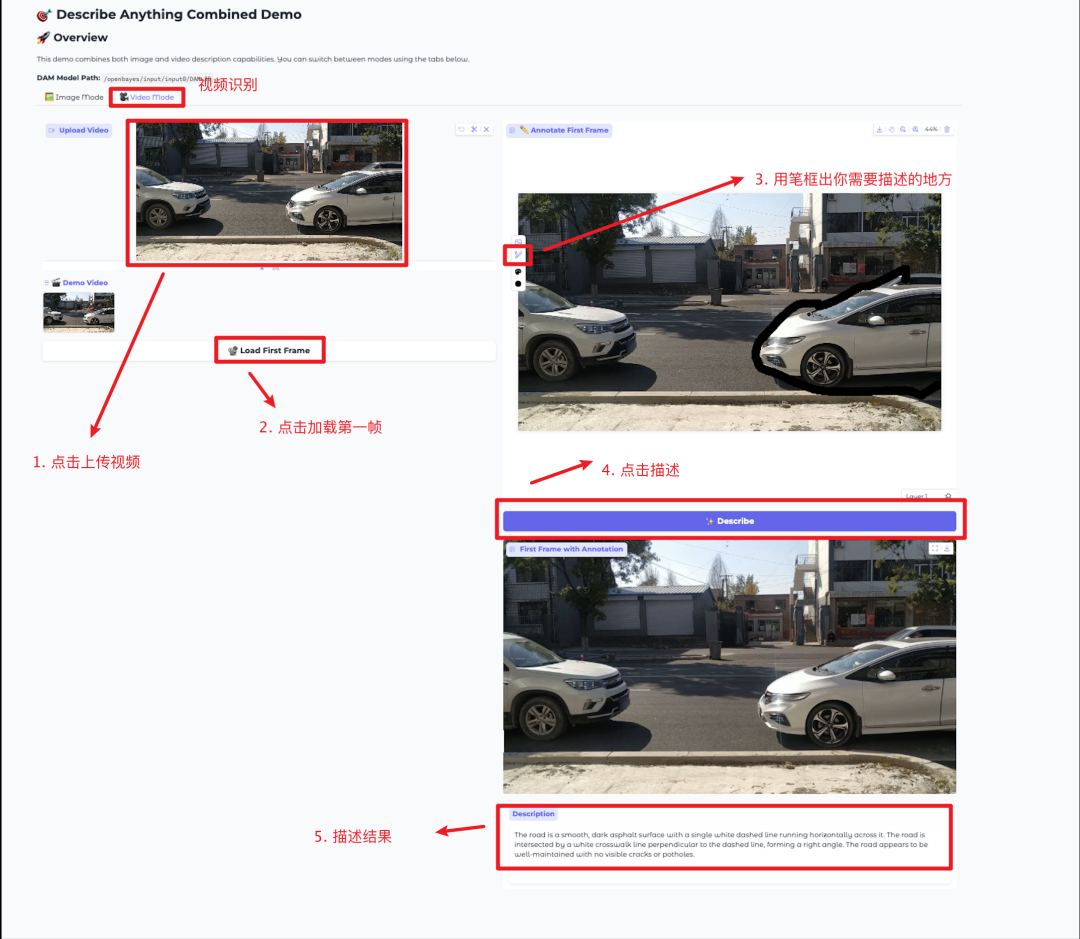
项目示例
7. OmniConsistency:GPT-4o级的人物风格迁移模型
OmniConsistency 显著提升了视觉连贯性和美学质量,实现了与商业最先进模型 GPT-4o 相当的性能。填补了开源模型与商业模型(如 GPT-4o)在风格一致性上的性能差距,为 AI 创作提供了低成本、高可控的解决方案,推动了图像生成技术的民主化。其兼容性和即插即用特性也降低了开发者与创作者的使用门槛。
该教程算力资源采用单卡 RTX A6000,进入下方链接,快速生成多风格图像。
* 在线运行:

















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









