



引言:
在这篇博客中,我将分享一个利用机器学习技术来预测COVID-19的回归任务。
本篇博客是对李宏毅机器学习的学习笔记。
欢迎大家加群一起讨论,群号:972252910。群二维码在本篇博客最底下。
源码地址:
pytorch_learning/HW1 Regression at main · Ol1ver0413/pytorch_learning (github.com)
环境介绍:
cuda:12.1
python:3.9.2
torch:2.1.0+cu121
TorchVision version: 0.16.0+cu121
模型执行框架:
- 导入库函数和包
- 将 covid_train.csv 的数据集按比例分为训练集和验证集
- 定义自己的Dataset+神经网络模型+训练过程函数
- 提取训练集和验证集中的特征和标签并单独放置在变量中
- 开始训练并保存最好一次的模型
- 验证测试集并导出预测结果
部分代码段解释:
1. 固定随机种子+分割数据集+定义测试函数
# 固定随机种子,确保作业可以重现,随机数生产期产生的随机数是一致的
def same_seed(seed):
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# 将数据集分割为验证集和训练集
def train_valid_split(data_set, valid_ratio, seed):
valid_set_size = int(valid_ratio * len(data_set))
# 验证集的大小为 valid_ration*整个的数据集大小
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))
# 在data_set数据集中按照8:2的比例分割,并且由于确定了generator固定保证了分割过程的可重复性
return np.array(train_set), np.array(valid_set)
# 对测试集进行预测
def predict(test_loader, model, device):
model.eval()
# 开启验证模式,不会dropout以及会计算移动的batch normalization
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
# pred会脱离计算图,并且从gpu移动到cpu上
preds = torch.cat(preds, dim=0).numpy()
# 将preds沿着第0维拼接起来,并转化为numpy数组
return preds2. 定义训练过程
# 定义训练过程
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean')
# 定义MSE作为损失函数,并返回均方误差平均值
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.7)
# 定义了SGD优化器,用来更新参数;momentum=0.7为动量,将考虑之前梯度的 70% 加上当前梯度的 30%
if not os.path.isdir('./models'):
os.mkdir('./models')
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
# early_stop_count 初始化为 0,用于记录模型性能未改善的连续轮数
for epoch in range(n_epochs):
model.train()
loss_record = []
train_pbar = tqdm(train_loader, position=0, leave=True)
# tqdm is a package to visualize your training progress.
# tqdm(iterator)用来封装迭代器,是可以在循环的时候显示长进度条
# train_loader本身为一个dataloader对象,而dataloader本身为一个批量加载数据的迭代器
# position=0代表进度条在终端顶端,leave=true代表进度条满了之后不消失
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
# 设置进度条的的描述信息和和后置信息
mean_train_loss = sum(loss_record)/len(loss_record)
model.eval()
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path'])
# 如果当前的loss小于所保存的最小loss,则保存模型
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
# 如果模型性能未改善的连续轮数大于规定值,停止训练
print('\nModel is not improving, so we halt the training session.')
return3. 初始化自己的数据集
# 定义你自己的数据集
same_seed(config['seed'])
train_data, test_data = pd.read_csv('./covid_train.csv').values, pd.read_csv('./covid_test.csv').values
# 读取文件数据,将其转化为DataFrame对象,再转化为numpy数组
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])
# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
# 定义dataset
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \
COVID19Dataset(x_valid, y_valid), \
COVID19Dataset(x_test)
# 定义dataloader
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
# shuffle代表会打乱数据,每个batch的数据会随机加载;pin_memory代表加速传到gpu
# 可以看到输出train和valid数据集都有89列,是因为最后一列是标签,而train是不包含标签的
4. 开始训练
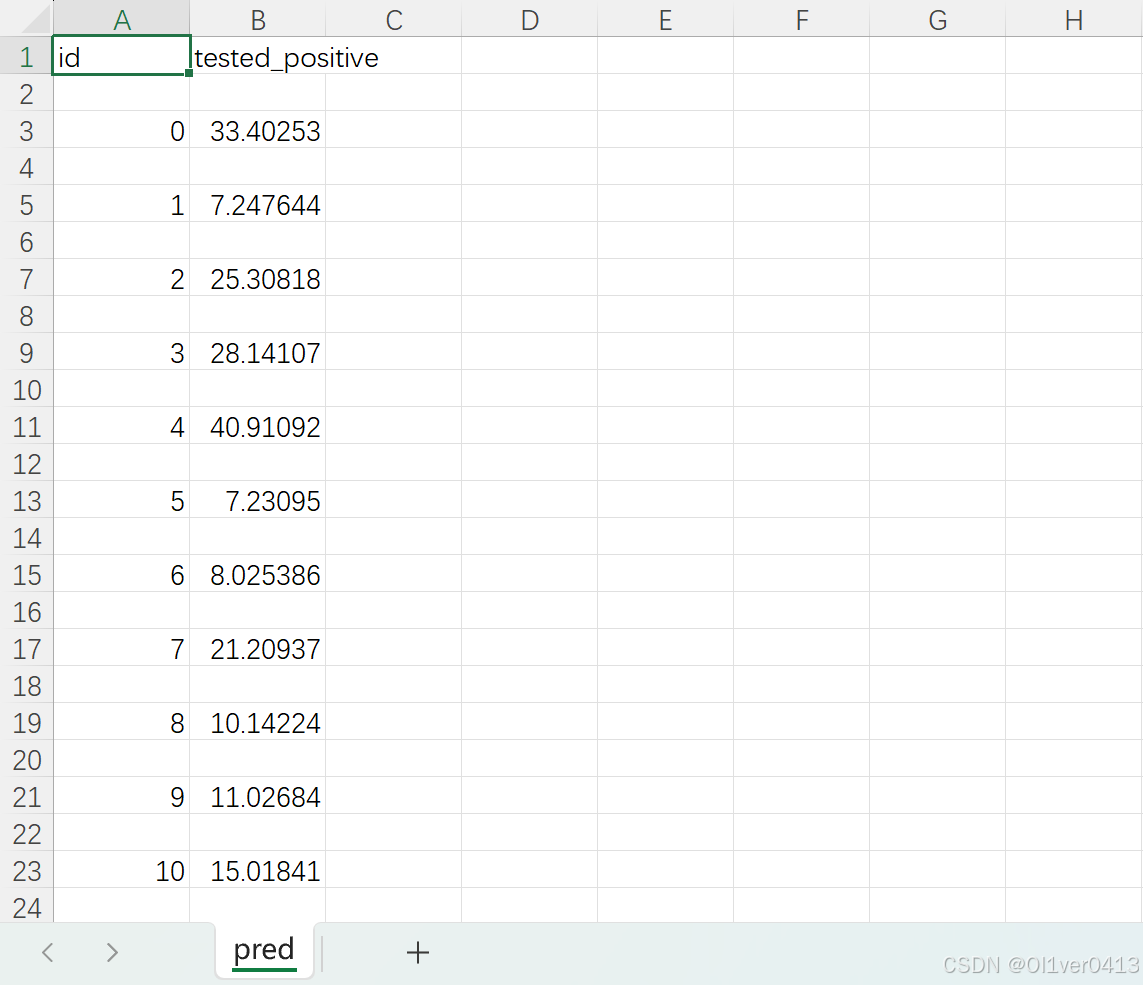
5. 结果展示
结语:
通过这次回归任务的深入研究和实践,我们不仅对COVID-19疫情的预测有了更清晰的认识,也对回归分析这一强大的统计工具有了更深刻的理解。
本人也是在学习AI的道路上,欢迎大家提出问题和分享答案。


















 65
65

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









