




 本文详细介绍了反向传播算法,通过链式法则解释了如何计算神经网络的权重梯度。首先,阐述了链式法则在两种情况下的应用,接着通过实例详细解释了反向传播的过程,包括前向传播计算∂ωi∂zi和反向传播计算∂z∂l,最后总结了反向传播算法的重要性和工作原理。
本文详细介绍了反向传播算法,通过链式法则解释了如何计算神经网络的权重梯度。首先,阐述了链式法则在两种情况下的应用,接着通过实例详细解释了反向传播的过程,包括前向传播计算∂ωi∂zi和反向传播计算∂z∂l,最后总结了反向传播算法的重要性和工作原理。
Chain Rule(链式法则)
Case 1
如果有:
y=g(x) z=h(y)y = g(x)\ \ \ \ \ \ z = h(y)y=g(x) z=h(y)
那么“变量影响链”就有:
Δx→ΔyΔz\Delta x\rightarrow \Delta y \Delta zΔx→ΔyΔz
因此就有:
dzdx=dzdydydx\frac{d z}{d x} = \frac{d z}{d y}\frac{d y}{d x}dxdz=dydzdxdy
Case 2
如果有:
y=g(s) y=h(s) z=k(x,y)y = g(s)\ \ \ \ \ \ y = h(s)\ \ \ \ \ \ z=k(x,y)y=g(s) y=h(s) z=k(x,y)
那么“变量影响链”就有:

因此就有:
dzds=∂z∂xdxds+∂z∂ydyds\frac{d z}{d s} = \frac{\partial z}{\partial x}\frac{d x}{ds} + \frac{\partial z}{\partial y}\frac{d y}{ds} dsdz=∂x∂zdsdx+∂y∂zdsdy
Backpropagation(反向传播算法)——实例讲解
定义
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)——维基百科
说明
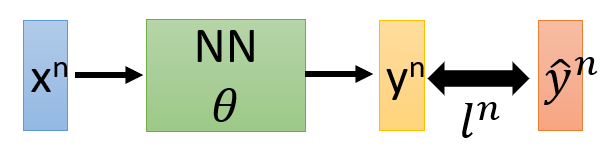
假设现在有N个样本数据,那么实际上损失函数可以表示为:
L(θ)=∑n=1Nln(θ)L(\theta) = \sum_{n=1}^Nl^n(\theta)L(θ)=n=1∑Nln(θ)
其中θ\thetaθ为需要学习的参数。
那么现在ω\omegaω对LLL进行偏微分,实际上是对每个样本数据的损失函数l(θ)l(\theta)l(θ)进行偏微分后再求和:
∂L(θ)∂ω=∑n=1N∂ln(θ)∂ω\frac{\partial L(\theta)}{\partial \omega} = \sum_{n=1}^N\frac{\partial l^n(\theta)}{\partial \omega}∂ω∂L(θ)=n=1∑N∂ω∂ln(θ)

用代数表示为:
z1=ω11x1+ω12x2+b1 a1=σ(z1)z_1 = \omega_{11}x_1 + \omega_{12}x_2 + b_1 \ \ \ \ \ \ \ \ \ \ \ a_1 = \sigma(z_1)z1=ω11x1+ω12x2+b1 a1=σ(z1)
z2=ω21x1+ω22x2+b2 a2=σ(z2)z_2 = \omega_{21}x_1 + \omega_{22}x_2 + b_2 \ \ \ \ \ \ \ \ \ \ \ a_2 = \sigma(z_2)z2=ω21x1+ω22x2+b2 a2=σ(z2)
z3=ω31a1+ω32a2+b3 a3=σ(z3)z_3 = \omega_{31}a_1 + \omega_{32}a_2 + b_3 \ \ \ \ \ \ \ \ \ \ \ a_3 = \sigma(z_3)z3=ω31a1+ω32a2+b3 a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









