




 本文深入探讨SLAM中的最小二乘优化,包括BA(Bundle Adjustment)的本质,线性和非线性最小二乘问题,以及SLAM常用的迭代优化算法,如高斯-牛顿法、 levenberg-marquardt 算法等。通过矩阵分解和分块消元方法求解非线性最小二乘问题,并讨论了鲁棒核函数在处理异常值时的重要性。
本文深入探讨SLAM中的最小二乘优化,包括BA(Bundle Adjustment)的本质,线性和非线性最小二乘问题,以及SLAM常用的迭代优化算法,如高斯-牛顿法、 levenberg-marquardt 算法等。通过矩阵分解和分块消元方法求解非线性最小二乘问题,并讨论了鲁棒核函数在处理异常值时的重要性。
文章目录
BA最小二乘的本质
BA优化的是最小二乘问题,那么为什么可以使用最小二乘来估计呢?小二乘问题与概率之间的关系:
使用最大后验概率(MAP)来得到状态量,其中z是观测值,x是状态:
x ^ = arg max x p ( x ∣ z ) (1) \hat { \mathbf { x } } = \arg \max _ { \mathbf { x } } p ( \mathbf { x } |\mathbf { z } )\tag{1} x^=argxmaxp(x∣z)(1)
使用贝叶斯展开:
x ^ = arg max x p ( x ∣ z ) = arg max x p ( z ∣ x ) p ( x ) p ( z ) = arg max x p ( z ∣ x ) p ( x ) \begin{aligned} \hat { \mathbf { x } } &= \arg \max _ { \mathbf { x } } p ( \mathbf { x } | \mathbf { z }) = \arg \max _ { \mathbf { x } } \frac { p ( \mathbf { z } | \mathbf { x } ) p ( \mathbf { x } ) } { p ( \mathbf { z } ) }\\ &= \arg \max _ { \mathbf { x } } p ( \mathbf { z } | \mathbf { x } ) p ( \mathbf { x } ) \end{aligned} x^=argxmaxp(x∣z)=argxmaxp(z)p(z∣x)p(x)=argxmaxp(z∣x)p(x)
其中第一项化为:
p ( z ∣ x ) = ∏ k = 0 K p ( z k ∣ x k ) (2) p ( \mathbf { z } | \mathbf { x } ) = \prod _ { k = 0 } ^ { K } p \left( \mathbf { z } _ { k } | \mathbf { x } _ { k } \right) \tag{2} p(z∣x)=k=0∏Kp(zk∣xk)(2)
第二项化为:
p ( x ) = p ( x 0 ∣ x ˇ 0 ) ∏ k = 1 K p ( x k ∣ x k − 1 ) (3) p ( \mathbf { x } ) = p \left( \mathbf { x } _ { 0 } | \check { \mathbf { x } } _ { 0 } \right) \prod _ { k = 1 } ^ { K } p \left( \mathbf { x } _ { k } | \mathbf { x } _ { k - 1 } \right)\tag{3} p(x)=p(x0∣xˇ0)k=1∏Kp(xk∣xk−1)(3)
第二项可以假设一个运动模型,忽略。
可以转化为最大似然估计(MLE):
x ^ = arg max x ∑ k = 0 K log p ( z k ∣ x k ) (4) \hat { \mathbf { x } } = \arg \max _ { \mathbf { x } }\sum _ { k = 0 } ^ { K } \log p \left( \mathbf { z } _ { k } | \mathbf { x } _ { k } \right)\tag{4} x^=argxmaxk=0∑Klogp(zk∣xk)(4)
其中使用高斯模型来假设:
log p ( z k ∣ x k ) = − 1 2 ( z k − z ( x k ) ) T Σ k − 1 ( z k − z ( x k ) ) − 1 2 log ( ( 2 π ) M det Σ k ) (5) \log p \left( \mathbf { z } _ { k } | \mathbf { x } _ { k } \right) = - \frac { 1 } { 2 } \left( \mathbf { z } _ { k } - z(\mathbf { x } _ { k }) \right) ^ { T } \mathbf { \Sigma } _ { k } ^ { - 1 } \left( \mathbf { z } _ { k } - z(\mathbf { x } _ { k }) \right) - \frac { 1 } { 2 } \log \left( ( 2 \pi ) ^ { M } \operatorname { det } \mathbf { \Sigma } _ { k } \right) \tag{5} logp(zk∣xk)=−21(zk−z(xk))TΣk−1(zk−z(xk))−21log((2π)MdetΣk)(5)
最后一项与状态无关,因此MLE可以化为:
x ^ = arg min x ∑ k = 0 K ∥ r ( z k , x k ) ∥ Σ k 2 (6) \hat { \mathbf { x } } = \arg \min _ { \mathbf { x } }\sum _ { k = 0 } ^ { K }\|r(\mathbf{z}_k, \mathbf{x}_k)\|^2_{\Sigma_k} \tag{6} x^=argxmink=0∑K∥r(zk,xk)∥Σk2(6)
其中残差项为马氏距离:
∥ r ∥ Σ 2 = r T Σ − 1 r (7) \|r\|^2_{\Sigma}=r^T\Sigma^{-1}r \tag{7} ∥r∥Σ2=rTΣ−1r(7)
这样就转化为了非线性最小二乘问题。
最小二乘服从卡方分布
z = ( x − m ) T Σ − 1 ( x − m ) ∼ χ n 2 (8) z = ( \mathbf { x } - \mathbf { m } ) ^ { T } \mathbf { \Sigma } ^ { - 1 } ( \mathbf { x } - \mathbf { m } ) \sim \chi _ { n } ^ { 2 }\tag{8} z=(x−m)TΣ−1(x−m)∼χn2(8)
这相当于一种加权的最小二乘。
最小二乘问题(Least-squares Minimization)
对于线性方程组,解的判别条件如下:
A x = 0 A{\bf x}={\bf 0} Ax=0 总有解,至少有零解
A m × n x = 0 A_{m\times n}{\bf x}={\bf 0} Am×nx=0
当 r ( A ) = n r(A)=n r(A)=n,只有零解
当 r ( A ) < n r(A)<n r(A)<n,有无穷多解A m × n x = b A_{m×n}{\bf x}={\bf b} Am×nx=b
当 r ( A ) ≠ r ( A ∣ b ) r(A)≠r(A|b) r(A)=r(A∣b),无解
当 r ( A ) = r ( A ∣ b ) = n r(A)=r(A|b)=n r(A)=r(A∣b)=n,有唯一解
当 r ( A ) = r ( A ∣ b ) = r < n r(A)=r(A|b)=r<n r(A)=r(A∣b)=r<n,有无穷多解
针对上面第三个方程,根据未知数和方程数量的关系可以分为以下几种情况:
如果 m < n m<n m<n,未知数大于方程数。那么解不唯一,存在一个解矢量空间。
如果 m = n m=n m=n,那么只要 A A A可逆(非奇异,也就是满秩)就有唯一解,解为 x = A − 1 b x=A^{−1}b x=A−1b。
如果 m > n m>n m>n,方程数大于未知数。方程一般没有解,除非 b \bf b b属于 A A A的列向量组成的子空间。

这里介绍针对 A x = b Ax=b Ax=b使用直接方法进行求解,即不使用迭代的方式。
超定方程
考虑 m > n m>n m>n, r ( A ) = n r(A)=n r(A)=n,这时无解,但可以找到一个最小二乘解,解最小二乘的解法有奇异值分解、正规方程和QR分解,可以参考许可师兄的博客。
正规方程的几何解释:
我们要寻找的是使得 ∥ A x − b ∥ \|A {\bf x}-{\bf b} \| ∥Ax−b∥最小的矢量 x {\bf x} x的值,把 A A A写成列空间的形式 A = ( a 1 , a 2 , . . . , a n ) A=(a_1,a_2,...,a_n) A=(a1,a2,...,an),当 x {\bf x} x取不同的值时, A x A{\bf x} Ax看作是列空间 A A A生成的子空间,但是在存在一个最接近向量 b {\bf b} b的子空间,我们要找到这个子空间。
针对这个子空间的理解:
假设 A A A是 m × n m\times n m×n维( m > n m>n m>n )的矩阵,那么就可以理解为在m维的空间上有以这n个(或者更少,据相关性决定)向量为基底组成的子空间中,找到一个向量与m维空间中的一个向量b最接近,由于是子空间中,若b不在这个子空间中那么是找不到解析解的,只有最接近的最小二乘解,也就是图中垂直的情况。
如图,平面为 R a n k ( A ) Rank(A) Rank(A)的子空间,当向量 A x − b A{\bf x}-{\bf b} Ax−b垂直如图的列空间时最小,其它情况都是斜边比它大。
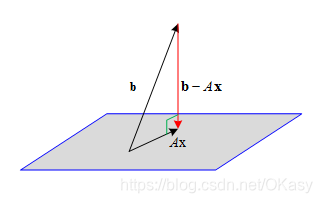
因此让向量 A x − b A{\bf x}-{\bf b} Ax−b垂直与 A A A的列空间,得到:
A T ( A x − b ) = 0 (9) A^T(A{\bf x}-{\bf b})={\bf 0} \tag{9} AT(Ax−b)=0(9)
整理得到:
A T A x = A T b x = ( A T A ) − 1 A T b (10) A^TA{\bf x}=A^T{\bf b} \\ {\bf x}=(A^TA)^{-1}A^T{\bf b} \tag{10} ATAx=ATbx=(ATA)−1ATb(10)
为什么有解,因为 A T b A^Tb ATb在 A T A A^TA ATA的列空间中。
加权的最小二乘问题:
( A T C A ) x = A T C b (11) \left( \mathrm { A } ^ { \mathrm { T } } \mathrm { CA } \right) \mathbf { x } = \mathrm { A } ^ { \mathrm { T } } \mathrm { Cb } \tag{11} (ATCA)x=ATCb(11)
适定方程
考虑 A ∈ R n × n A\in R^{n\times n} A∈Rn×n, r ( A ) = n r(A)=n r(A)=n的情况,这种情况下通常可以使用公式(12)求解,但是当矩阵维数很大时,或者要求实时性时就变得不实用了。
x = A − 1 b (12) {\bf x=A^{-1}b} \tag{12} x=A−1b(12)
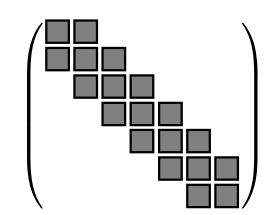
针对稀疏模式,我们可以利用一些系数矩阵结构来更快的进行求解。通常包括带状(如下图)、分块对角和稀疏矩阵。
通常方便求解的一些特殊系数矩阵包括:
对角矩阵:直接可以求出。
上三角矩阵:从最后一个未知数开始解,使用后向带入(back-substitution)的方式。
下三角矩阵:从第一个未知数开始解,使用前向带入(forward-substitution)的方式。
正交矩阵:转置求解,特殊的有Householder矩阵 A = I − 2 u u T A=I-2uu^T A=I−2uuT形式可以加快求解。
排列矩阵:实现矩阵的行交换和列交换的矩阵,只有1或者0。直接求解。
矩阵的求解方法可以分为:
因式分解的方法,把系数矩阵A分解成上面所描述的一些方便求解的矩阵的连乘形式进行求解。
分块消元的方法,对系数矩阵具有特殊结构的形式,可以进行分块消元来求解。
因式分解
LU分解
针对非奇异矩阵 ,可以因式分解为
A = P L U (13) A=PLU \tag{13} A=PLU(13)
式中P是排列矩阵,L是单位下三角矩阵,U是上三角矩阵。
带状结构矩阵和稀疏矩阵可以获得更快的运算。对于稀疏矩阵有如下分解:
A = P 1 L U P 2 (14) A=P_1LUP_2 \tag{14} A=P1LUP2(14)
LU若是稀疏的,可以加快求解,它的稀疏性依赖于排列矩阵 P 1 P 2 P_1P_2 P1P2的选择。系数矩阵的LU分解成本依赖于维数、非零元素的个数、稀疏模式和使用的算法等。
Cholesky分解
针对对称正定矩阵,可以因式分解为
A = L L T (15) A=LL^T \tag{15} A=LLT(15)
其中L为下三角非奇异矩阵,对角元素是正数。快于LU分解一倍,对带状和稀疏矩阵,使用特殊算法复杂度远低于稠密矩阵的复杂度。
对于稀疏矩阵,有分解形式:
A = P L L T P T (16) A=PLL^TP^T \tag{16} A=PLLTPT(16)
同样排列矩阵P对L的稀疏性有很大影响,它由系数矩阵的稀疏模式所决定,不取决于非零元素的具体值。因此可以分为两步骤,符号因式分解和数值因式分解。(LU分解的P依赖于具体数值)
LDLT分解
针对非奇异对称矩阵,可以分解为
A = P L D L T P T (17) A=PLDL^TP^T \tag{17} A=PLDLTP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







