




第8章描述了Linux-2.6.11中的内核内存分配。这一章补充描述Linux-5.10.110中的内存分配。主要从三个方面描述。首先是伙伴系统,我们已经看到,他是内核中内存分配的基础,不管是slab还是vmalloc,都需要从伙伴系统中分配内存。然后我们会描述kmem_cache和kmalloc,他们是内核中最常使用的分配内存的手段。最后,我们会描述vmalloc。与kmalloc相比,它主要用于分配大块的内存。
1:数据结构
这一节描述内存管理模块使用的结构体。
1.1:节点node和管理区zone
在现代的计算机内存中,有节点node这一概念。每个节点node又包含了几个内存区zone。每个节点使用结构体struct pglist_data描述。因此,在NUMA系统中,有多个节点,多个节点的struct pglist_data就会组成数组
|
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly; |
而在UMA模型中,只有一个节点,因此使用
|
struct pglist_data __refdata contig_page_data; |
来描述。总之,结构体struct pglist_data描述了一个内存结点。
|
/* * On NUMA machines, each NUMA node would have a pg_data_t to describe * it's memory layout. On UMA machines there is a single pglist_data which * describes the whole memory. * * Memory statistics and page replacement data structures are maintained on a * per-zone basis. */ typedef struct pglist_data { /* * node_zones contains just the zones for THIS node. Not all of the * zones may be populated, but it is the full list. It is referenced by * this node's node_zonelists as well as other node's node_zonelists. *///这个节点包含的所有管理区 struct zone node_zones[MAX_NR_ZONES]; /* * node_zonelists contains references to all zones in all nodes. * Generally the first zones will be references to this node's * node_zones. */ /* 在UMA中,node_zonelists包含了一个个struct zonelist。而struct zonelist是系统中所有的zone构成的数组 struct zonelist { struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1]; }; */ struct zonelist node_zonelists[MAX_ZONELISTS]; int nr_zones; /* number of populated zones in this node */ #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ struct page *node_mem_map; #ifdef CONFIG_PAGE_EXTENSION struct page_ext *node_page_ext; #endif #endif #if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT) /* * Must be held any time you expect node_start_pfn, * node_present_pages, node_spanned_pages or nr_zones to stay constant. * Also synchronizes pgdat->first_deferred_pfn during deferred page * init. * * pgdat_resize_lock() and pgdat_resize_unlock() are provided to * manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG * or CONFIG_DEFERRED_STRUCT_PAGE_INIT. * * Nests above zone->lock and zone->span_seqlock */ spinlock_t node_size_lock; #endif unsigned long node_start_pfn; unsigned long node_present_pages; /* total number of physical pages */ unsigned long node_spanned_pages; /* total size of physical page range, including holes */ int node_id; wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait; struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */ int kswapd_order; enum zone_type kswapd_highest_zoneidx; int kswapd_failures; /* Number of 'reclaimed == 0' runs */ #ifdef CONFIG_COMPACTION int kcompactd_max_order; enum zone_type kcompactd_highest_zoneidx; wait_queue_head_t kcompactd_wait; struct task_struct *kcompactd; #endif /* * This is a per-node reserve of pages that are not available * to userspace allocations. */ unsigned long totalreserve_pages; #ifdef CONFIG_NUMA /* * node reclaim becomes active if more unmapped pages exist. */ unsigned long min_unmapped_pages; unsigned long min_slab_pages; #endif /* CONFIG_NUMA */ /* Write-intensive fields used by page reclaim */ ZONE_PADDING(_pad1_) spinlock_t lru_lock; #ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * If memory initialisation on large machines is deferred then this * is the first PFN that needs to be initialised. */ unsigned long first_deferred_pfn; #endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */ #ifdef CONFIG_TRANSPARENT_HUGEPAGE struct deferred_split deferred_split_queue; #endif /* Fields commonly accessed by the page reclaim scanner */ /* * NOTE: THIS IS UNUSED IF MEMCG IS ENABLED. * * Use mem_cgroup_lruvec() to look up lruvecs. */ struct lruvec __lruvec; unsigned long flags; ZONE_PADDING(_pad2_) /* Per-node vmstats */ struct per_cpu_nodestat __percpu *per_cpu_nodestats; atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS]; } pg_data_t; |
一个节点中包含了多个内存区。内存区使用结构体struct zone描述
|
struct zone { /* Read-mostly fields */ /* zone watermarks, access with *_wmark_pages(zone) macros */ unsigned long _watermark[NR_WMARK]; unsigned long watermark_boost; unsigned long nr_reserved_highatomic; /* * We don't know if the memory that we're going to allocate will be * freeable or/and it will be released eventually, so to avoid totally * wasting several GB of ram we must reserve some of the lower zone * memory (otherwise we risk to run OOM on the lower zones despite * there being tons of freeable ram on the higher zones). This array is * recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl * changes. */ long lowmem_reserve[MAX_NR_ZONES]; #ifdef CONFIG_NEED_MULTIPLE_NODES int node; #endif struct pglist_data *zone_pgdat; struct per_cpu_pageset __percpu *pageset; #ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsigned long *pageblock_flags; #endif /* CONFIG_SPARSEMEM */ /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ unsigned long zone_start_pfn; /* * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; * * present_pages is physical pages existing within the zone, which * is calculated as: * present_pages = spanned_pages - absent_pages(pages in holes); * * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): * managed_pages = present_pages - reserved_pages; * * So present_pages may be used by memory hotplug or memory power * management logic to figure out unmanaged pages by checking * (present_pages - managed_pages). And managed_pages should be used * by page allocator and vm scanner to calculate all kinds of watermarks * and thresholds. * * Locking rules: * * zone_start_pfn and spanned_pages are protected by span_seqlock. * It is a seqlock because it has to be read outside of zone->lock, * and it is done in the main allocator path. But, it is written * quite infrequently. * * The span_seq lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. * * Write access to present_pages at runtime should be protected by * mem_hotplug_begin/end(). Any reader who can't tolerant drift of * present_pages should get_online_mems() to get a stable value. */ atomic_long_t managed_pages; unsigned long spanned_pages; unsigned long present_pages; const char *name; int initialized; /* Write-intensive fields used from the page allocator */ ZONE_PADDING(_pad1_) /* free areas of different sizes */ struct free_area free_area[MAX_ORDER]; /* zone flags, see below */ unsigned long flags; /* Primarily protects free_area */ spinlock_t lock; /* Write-intensive fields used by compaction and vmstats. */ ZONE_PADDING(_pad2_) /* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsigned long percpu_drift_mark; bool contiguous; ZONE_PADDING(_pad3_) /* Zone statistics */ atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS]; } ____cacheline_internodealigned_in_smp; |
1.2:struct alloc_context
结构体struct alloc_context用于描述从伙伴系统分配物理内存的行为。
|
/* * in mm/page_alloc.c */ /* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and highest_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and highest_zoneidx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole structure * by a const pointer. */ struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; /* * highest_zoneidx represents highest usable zone index of * the allocation request. Due to the nature of the zone, * memory on lower zone than the highest_zoneidx will be * protected by lowmem_reserve[highest_zoneidx]. * * highest_zoneidx is also used by reclaim/compaction to limit * the target zone since higher zone than this index cannot be * usable for this allocation request. */ enum zone_type highest_zoneidx; bool spread_dirty_pages; }; |
2:伙伴系统
伙伴系统的对外接口是alloc_page或者alloc_pages。它的作用是,指定分配的页数目(1<<order)和分配的标志位,分配连续的物理内存页,并且返回首页的page结构。
|
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0) |
|
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order) { return alloc_pages_node(numa_node_id(), gfp_mask, order); //在UMA系统中,numa_node_id()返回0 } |
|
/* * Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE, * prefer the current CPU's closest node. Otherwise node must be valid and * online. */ static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order) { if (nid == NUMA_NO_NODE) nid = numa_mem_id(); return __alloc_pages_node(nid, gfp_mask, order); } |
|
/* * Allocate pages, preferring the node given as nid. The node must be valid and * online. For more general interface, see alloc_pages_node(). */ static inline struct page * __alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order) { VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES); VM_WARN_ON((gfp_mask & __GFP_THISNODE) && !node_online(nid)); return __alloc_pages(gfp_mask, order, nid); } |
|
static inline struct page * __alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid) { return __alloc_pages_nodemask(gfp_mask, order, preferred_nid, NULL); } |
上面只是简单的调用流程,没有有价值的地方。我们终于进入了函数__alloc_pages_nodemask。这是伙伴系统的核心。
2.1:伙伴系统的核心——__alloc_pages_nodemask
函数__alloc_pages_nodemask的实现如下:
|
/* * This is the 'heart' of the zoned buddy allocator. */ struct page * __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask) { struct page *page; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */ struct alloc_context ac = { }; /* * There are several places where we assume that the order value is sane * so bail out early if the request is out of bound. */ if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN)); return NULL; } gfp_mask &= gfp_allowed_mask; alloc_mask = gfp_mask; if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags)) //初始化struct alloc_context结构体 return NULL; /* * Forbid the first pass from falling back to types that fragment * memory until all local zones are considered. */ alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask); /* First allocation attempt *///第一次分配,快速分配 page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac); if (likely(page)) goto out; /* * Apply scoped allocation constraints. This is mainly about GFP_NOFS * resp. GFP_NOIO which has to be inherited for all allocation requests * from a particular context which has been marked by * memalloc_no{fs,io}_{save,restore}. */ alloc_mask = current_gfp_context(gfp_mask); ac.spread_dirty_pages = false; /* * Restore the original nodemask if it was potentially replaced with * &cpuset_current_mems_allowed to optimize the fast-path attempt. */ ac.nodemask = nodemask; page = __alloc_pages_slowpath(alloc_mask, order, &ac); out: return page; } |
这个函数主要包含了三个部分:
1:prepare_alloc_pages
2:get_page_from_freelist
3:__alloc_pages_slowpath
2.2:prepare_alloc_pages
这个函数的实现如下,它主要填充了结构体struct alloc_context
|
/* * in mm/page_alloc.c */ /* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and highest_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and highest_zoneidx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole structure * by a const pointer. *///从注释中,我们知道,成员zonelist, preferred_zone and highest_zoneidx在快速分配和慢速分配中,会发生改变 struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; /* * highest_zoneidx represents highest usable zone index of * the allocation request. Due to the nature of the zone, * memory on lower zone than the highest_zoneidx will be * protected by lowmem_reserve[highest_zoneidx]. * * highest_zoneidx is also used by reclaim/compaction to limit * the target zone since higher zone than this index cannot be * usable for this allocation request. *///这个枚举变量的取值可能是ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM,ZONE_MOVABLE。这个值限制了可以使用的zone的idx最大值 enum zone_type highest_zoneidx; bool spread_dirty_pages; }; |
|
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_mask, unsigned int *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); //根据gfp_mask的最后4bit,我们可以获得从哪些内存区中分配内存。例如,GFP_HIGHUSER_MOVABLE包含了__GFP_HIGHMEM| __GFP_MOVABLE。在GFP_ZONE_TABLE中,对应了ZONE_MOVABLE。也就是说,分配内存的时候,内存区最高使用到MOVABLE ac->zonelist = node_zonelist(preferred_nid, gfp_mask); //每个节点node的struct zonelist node_zonelists[MAX_ZONELISTS]成员都存放了所有的内存区的zone数据,但是每个node的node_zonelists最开始都是自己的zone。并且每个节点node的struct zonelist node_zonelists[MAX_ZONELISTS]是从高级zone向低级排的,也就是说,这里zonelist可能是这个node的NORMAL,DMA32,DMA这个顺序 ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); //根据gfp_mask中是否设置__GFP_RECLAIMABLE与__GFP_MOVABLE,设置migratetype为enum migratetype中的值 might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); if (should_fail_alloc_page(gfp_mask, order)) return false; *alloc_flags = current_alloc_flags(gfp_mask, *alloc_flags); /* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); /* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, //我们拿到最开始进行分配的zone。要求这个zoneref的zone_idx <= highest_zoneidx。例如,我们使用GFP_KERNEL宏,我们会按照NORMAL,DMA32,DMA的顺序分配,所以这里拿到的是NORMAL ac->highest_zoneidx, ac->nodemask); return true; } |
2.3:get_page_from_freelist
get_page_from_freelist是我们第一次分配。说明一下各参数的含义。gfp_mask:我们传入的gfp_mask;order:我们传入的order;alloc_flags:包含水位,能否做内存回收等信息;ac:包含要使用的内存区信息等。函数prepare_alloc_pages实现如下:
|
static struct page * get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) { struct zoneref *z; struct zone *zone; struct pglist_data *last_pgdat_dirty_limit = NULL; bool no_fallback; retry: /* * Scan zonelist, looking for a zone with enough free. * See also __cpuset_node_allowed() comment in kernel/cpuset.c. */ no_fallback = alloc_flags & ALLOC_NOFRAGMENT; z = ac->preferred_zoneref; for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx, //这里遍历所有能够做内存分配的zone ac->nodemask) { struct page *page; unsigned long mark; ……//这部分内容我们不关注 mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);//我们获得这次分配使用的水位线。在快速分配的时候,我们使用的是LOW水位线。这时候,mark是页数 if (!zone_watermark_fast(zone, order, mark, //这里判断zone能够满足分配条件。满足的话返回true,从而进入rmqueue进行内存分配。判断的标准就是,分配完成后,剩下的内存应该大于LOW水线的一个相关值 ac->highest_zoneidx, alloc_flags, gfp_mask)) { int ret; /* Checked here to keep the fast path fast */ BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone; continue; //我们假设我们是UMA模型。这种情况下一定会走到continue …… //在NUMA模型中,后面的流程无效,我们不关注 } try_this_zone://流程走到这里,表示我们已经找到了一个满足水位要求的zone,或者我们设置了ALLOC_NO_WATERMARKS,也就是不考虑水位 page = rmqueue(ac->preferred_zoneref->zone, zone, order, //使用rmqueue从伙伴系统中分配内存 gfp_mask, alloc_flags, ac->migratetype); if (page) { prep_new_page(page, order, gfp_mask, alloc_flags); //设置page->_refcount=1,清->private=0 /* * If this is a high-order atomic allocation then check * if the pageblock should be reserved for the future */ if (unlikely(order && (alloc_flags & ALLOC_HARDER))) reserve_highatomic_pageblock(page, zone, order); return page; } //我们选择了一个内存区,但是这个内存区也可能分不出来内存。分不出来就继续做大循环 } //我们遍历了所有的zone,还是没能找到合适的内存区,返回NULL /* * It's possible on a UMA machine to get through all zones that are * fragmented. If avoiding fragmentation, reset and try again. */ if (no_fallback) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } return NULL; } |
因此,在第一次快速分配的时候,我们扫描zone,看他是否满足条件。如果满足的话,就通过函数rmqueue进行分配。否则返回NULL。而这里是否满足条件,和水线LOW有强相关关系。当水线很高的时候,很可能我们不能通过快速路径分出来内存。
注意,在快速路径中,我们不会进行内存回收。
2.4:__alloc_pages_slowpath
如果我们在第一次快速分配的时候,没有成功,那么就会进行慢速分配的流程。这里的参数,gfp_mask:我们传入的gfp_mask;order:我们传入的order;ac:包含要使用的内存区信息等。
|
static inline struct page * __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order, struct alloc_context *ac) { bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM; const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER; //order > 3?当order比较小的时候,内存分配不受内存碎片的干扰,因此无法分配内存的时候,不应该尝试内存压缩(迁移) struct page *page = NULL; unsigned int alloc_flags; unsigned long did_some_progress; enum compact_priority compact_priority; enum compact_result compact_result; int compaction_retries; int no_progress_loops; unsigned int cpuset_mems_cookie; int reserve_flags; /* * We also sanity check to catch abuse of atomic reserves being used by * callers that are not in atomic context. *///__GFP_ATOMIC表示分配内存是原子操作。在此过程中不能进行内存回收 if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) == (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM))) gfp_mask &= ~__GFP_ATOMIC; retry_cpuset: compaction_retries = 0; no_progress_loops = 0; compact_priority = DEF_COMPACT_PRIORITY; /* * The fast path uses conservative alloc_flags to succeed only until * kswapd needs to be woken up, and to avoid the cost of setting up * alloc_flags precisely. So we do that now. *///相较于快速路径,慢速路径中对alloc_flags做了以下修改:1:水位值使用MIN;2:如果gfp_mask设置__GFP_HIGH(高优先级)或__GFP_KSWAPD_RECLAIM(允许唤醒kswapd),在alloc_flags中设置相应的位;3:如果gfp_mask设置__GFP_ATOMIC或者当前进程是实时进程,且不在中断中,设置ALLOC_HARDER alloc_flags = gfp_to_alloc_flags(gfp_mask); /* * We need to recalculate the starting point for the zonelist iterator * because we might have used different nodemask in the fast path, or * there was a cpuset modification and we are retrying - otherwise we * could end up iterating over non-eligible zones endlessly. *///我们重新设置preferred_zoneref的值 ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); if (!ac->preferred_zoneref->zone) goto nopage; if (alloc_flags & ALLOC_KSWAPD)//如果gfp_mask设置了__GFP_KSWAPD_RECLAIM,这里就会唤醒kswapd回收内存。注意有__GFP_KSWAPD_RECLAIM(通过kswapd)或者__GFP_RECLAIM(直接回收两种形式) wake_all_kswapds(order, gfp_mask, ac); /* * The adjusted alloc_flags might result in immediate success, so try * that first *///我们使用了MIN水位,并且唤醒了kswapd。这里直接分配一下,看能不能分出来 page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg; /* * For costly allocations, try direct compaction first, as it's likely * that we have enough base pages and don't need to reclaim. For non- * movable high-order allocations, do that as well, as compaction will * try prevent permanent fragmentation by migrating from blocks of the * same migratetype. * Don't try this for allocations that are allowed to ignore * watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen. *///下面都是和内存压缩有关的代码。我们暂时不关注内存压缩 if (can_direct_reclaim && (costly_order || (order > 0 && ac->migratetype != MIGRATE_MOVABLE)) && !gfp_pfmemalloc_allowed(gfp_mask)) { page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac, INIT_COMPACT_PRIORITY, &compact_result); if (page) goto got_pg; /* * Checks for costly allocations with __GFP_NORETRY, which * includes some THP page fault allocations */ if (costly_order && (gfp_mask & __GFP_NORETRY)) { /* * If allocating entire pageblock(s) and compaction * failed because all zones are below low watermarks * or is prohibited because it recently failed at this * order, fail immediately unless the allocator has * requested compaction and reclaim retry. * * Reclaim is * - potentially very expensive because zones are far * below their low watermarks or this is part of very * bursty high order allocations, * - not guaranteed to help because isolate_freepages() * may not iterate over freed pages as part of its * linear scan, and * - unlikely to make entire pageblocks free on its * own. */ if (compact_result == COMPACT_SKIPPED || compact_result == COMPACT_DEFERRED) goto nopage; /* * Looks like reclaim/compaction is worth trying, but * sync compaction could be very expensive, so keep * using async compaction. */ compact_priority = INIT_COMPACT_PRIORITY; } } retry://我们已经使用了MIN水位。但是还是分不出来内存 /* Ensure kswapd doesn't accidentally go to sleep as long as we loop *///这里再唤醒一下kswapd进程 if (alloc_flags & ALLOC_KSWAPD) wake_all_kswapds(order, gfp_mask, ac); reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);//如果当前进程是要释放内存的进程,那么会设置ALLOC_NO_WATERMARKS,不再使用水位线 if (reserve_flags) alloc_flags = current_alloc_flags(gfp_mask, reserve_flags); /* * Reset the nodemask and zonelist iterators if memory policies can be * ignored. These allocations are high priority and system rather than * user oriented. */ if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) { ac->nodemask = NULL; ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); } /* Attempt with potentially adjusted zonelist and alloc_flags *///再次更改水位线,或者使用kswapd释放内存后,再次分配内存 page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg; /* Caller is not willing to reclaim, we can't balance anything *///这个进程不愿意直接回收内存 if (!can_direct_reclaim) goto nopage; /* Avoid recursion of direct reclaim *///这个进程就是回收内存的进程。我们避免他一直重复在回收内存的过程中 if (current->flags & PF_MEMALLOC) goto nopage; /* Try direct reclaim and then allocating */ page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,//我们直接回收内存后,看能否分配出内存 &did_some_progress); if (page) goto got_pg; /* Try direct compaction and then allocating */ page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,compact_priority, &compact_result); if (page) goto got_pg; /* Do not loop if specifically requested *///经过内存回收以及压缩后,我们还是无法成功分配内存。如果gfp_mask & __GFP_NORETRY,就不会做oom kill等操作 if (gfp_mask & __GFP_NORETRY) goto nopage; /* * Do not retry costly high order allocations unless they are * __GFP_RETRY_MAYFAIL */// if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL)) goto nopage; if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags, did_some_progress > 0, &no_progress_loops)) goto retry; //重新做reclaim操作。这里面会判断no_progress_loops是否大于MAX_RECLAIM_RETRIES(16)?如果是的话,已经做了16次没有进展的回收和压缩操作了,进OOM吧 /* * It doesn't make any sense to retry for the compaction if the order-0 * reclaim is not able to make any progress because the current * implementation of the compaction depends on the sufficient amount * of free memory (see __compaction_suitable) */ if (did_some_progress > 0 && should_compact_retry(ac, order, alloc_flags, //重新做compact操作 compact_result, &compact_priority, &compaction_retries)) goto retry; /* Reclaim has failed us, start killing things *///oom_killer机制 page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress); if (page) goto got_pg; /* Avoid allocations with no watermarks from looping endlessly */ if (tsk_is_oom_victim(current) && (alloc_flags & ALLOC_OOM || (gfp_mask & __GFP_NOMEMALLOC))) goto nopage; /* Retry as long as the OOM killer is making progress *///oom已经杀死了一些进程。我们这时候再次尝试内存分配 if (did_some_progress) { no_progress_loops = 0; goto retry; } nopage: /* * Make sure that __GFP_NOFAIL request doesn't leak out and make sure * we always retry */ if (gfp_mask & __GFP_NOFAIL) { //设置了__GFP_NOFAIL,我们最终还会继续retry,始终不会返回NULL /* * All existing users of the __GFP_NOFAIL are blockable, so warn * of any new users that actually require GFP_NOWAIT */ if (WARN_ON_ONCE(!can_direct_reclaim)) goto fail; /* * PF_MEMALLOC request from this context is rather bizarre * because we cannot reclaim anything and only can loop waiting * for somebody to do a work for us */ WARN_ON_ONCE(current->flags & PF_MEMALLOC); /* * non failing costly orders are a hard requirement which we * are not prepared for much so let's warn about these users * so that we can identify them and convert them to something * else. */ WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER); /* * Help non-failing allocations by giving them access to memory * reserves but do not use ALLOC_NO_WATERMARKS because this * could deplete whole memory reserves which would just make * the situation worse */ page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac); if (page) goto got_pg; cond_resched(); goto retry; } fail: warn_alloc(gfp_mask, ac->nodemask, "page allocation failure: order:%u", order); got_pg: return page; } |
因此,在慢速流程中,我们会通过kswapd,或者直接进行内存回收(前提是设置了__GFP_DIRECT_RECLAIM)
3:kmalloc
我们已经无需说明kmalloc的功能了。直接看它的实现。
|
/** * kmalloc - allocate memory * @size: how many bytes of memory are required. * @flags: the type of memory to allocate. * * kmalloc is the normal method of allocating memory * for objects smaller than page size in the kernel. * * The allocated object address is aligned to at least ARCH_KMALLOC_MINALIGN * bytes. For @size of power of two bytes, the alignment is also guaranteed * to be at least to the size. * * The @flags argument may be one of the GFP flags defined at * include/linux/gfp.h and described at * :ref:`Documentation/core-api/mm-api.rst <mm-api-gfp-flags>` * * The recommended usage of the @flags is described at * :ref:`Documentation/core-api/memory-allocation.rst <memory_allocation>` * * Below is a brief outline of the most useful GFP flags * * %GFP_KERNEL * Allocate normal kernel ram. May sleep. * * %GFP_NOWAIT * Allocation will not sleep. * * %GFP_ATOMIC * Allocation will not sleep. May use emergency pools. * * %GFP_HIGHUSER * Allocate memory from high memory on behalf of user. * * Also it is possible to set different flags by OR'ing * in one or more of the following additional @flags: * * %__GFP_HIGH * This allocation has high priority and may use emergency pools. * * %__GFP_NOFAIL * Indicate that this allocation is in no way allowed to fail * (think twice before using). * * %__GFP_NORETRY * If memory is not immediately available, * then give up at once. * * %__GFP_NOWARN * If allocation fails, don't issue any warnings. * * %__GFP_RETRY_MAYFAIL * Try really hard to succeed the allocation but fail * eventually. */ static __always_inline void *kmalloc(size_t size, gfp_t flags) { return __kmalloc(size, flags); } |
|
void *__kmalloc(size_t size, gfp_t flags) { struct kmem_cache *s; void *ret; if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) //KMALLOC_MAX_CACHE_SIZE= 1 >> 13 return kmalloc_large(size, flags); s = kmalloc_slab(size, flags); //根据size,选择一个合适的slub if (unlikely(ZERO_OR_NULL_PTR(s))) return s; ret = slab_alloc(s, flags, _RET_IP_); trace_kmalloc(_RET_IP_, ret, size, s->size, flags); ret = kasan_kmalloc(s, ret, size, flags); return ret; } |
系统中,和slub相关的数据结构关系图如下所示:
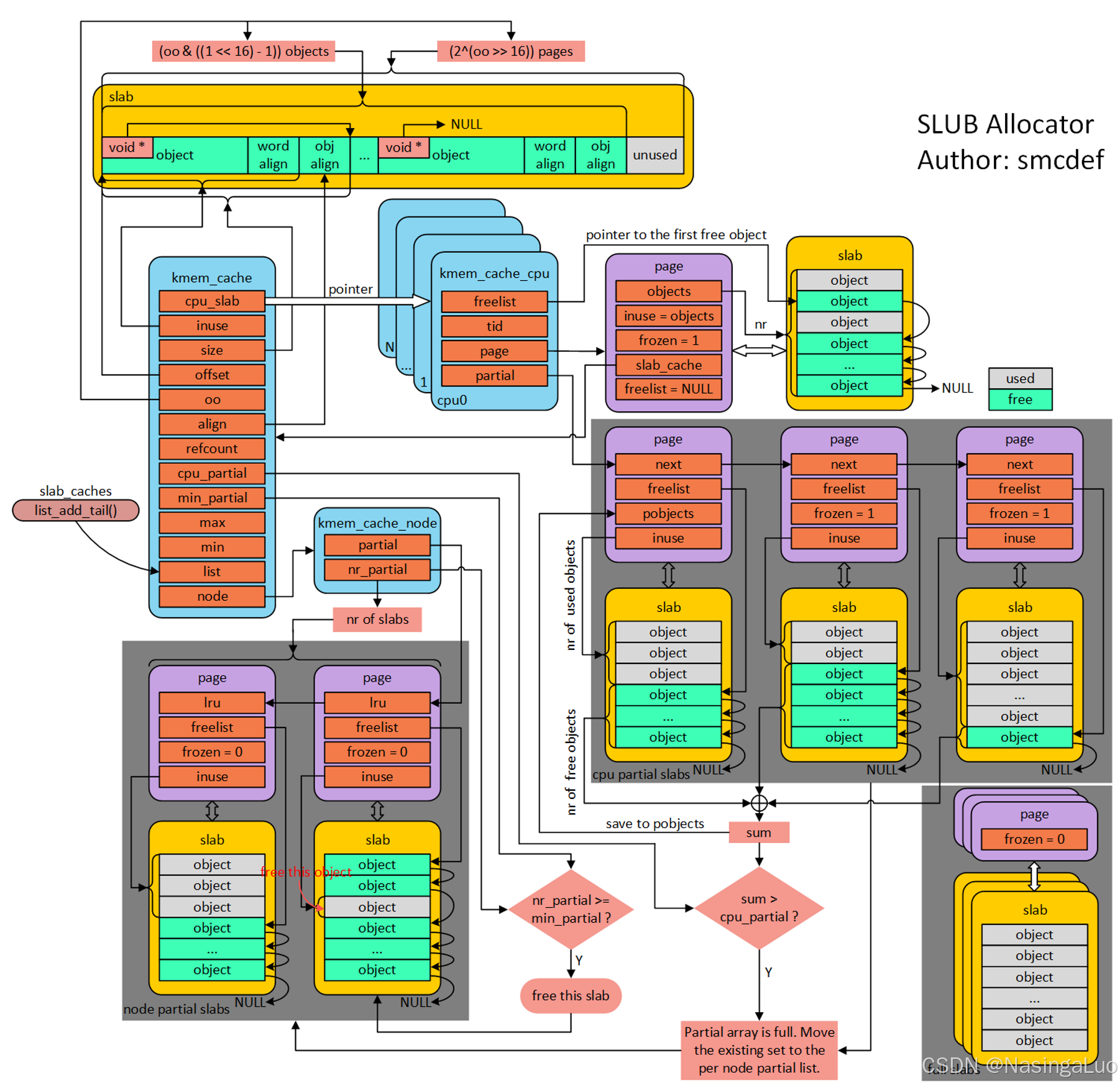
这张图描述了很多的信息。
1:kmem_cache是slub的管理结构。
2:slub作为伙伴系统的缓存,它自身也分成多级,kmem_cache_cpu.page->kmem_cache_cpu.partical->kmem_cache.node.partical。可以认为,分配内存的时候首先从kmem_cache_cpu.page中分配;分不出来,找这个cpu对应的kmem_cache_cpu.partical,将一个partical中包含的page赋值给kmem_cache_cpu.page,做分配;还是分不出来,找到这个node对应的kmem_cache.node.partical,将最开始有空闲对象的page赋值给kmem_cache_cpu.page,再额外将一些page添加到kmem_cache_cpu.partical中。如果还是分不出来,那么就从伙伴系统中做分配。
3:作为kmem_cache_cpu.page,它的成员具有以下特点:page->inuse=page->objects;page->frozen=1;page->freelist=NULL。
4:作为kmem_cache_cpu.partical,它的成员具有以下特点:page->inuse是真正使用了的对象数目;page->frozen=1;page->freelist是第一个空闲对象的地址。
3.1:创建一个slub
使用函数kmem_cache_create创建一个slub。这个函数只创建并初始化了描述slub的struct kmem_cache结构体,还并没有真正的从伙伴系统中给slub分配内存。我们首先看一下struct kmem_cache的数据结构
|
/* * Slab cache management. */ struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; /* Used for retrieving partial slabs, etc. */ slab_flags_t flags; unsigned long min_partial; unsigned int size; /* The size of an object including metadata */ unsigned int object_size;/* The size of an object without metadata */ struct reciprocal_value reciprocal_size; unsigned int offset; /* Free pointer offset */ #ifdef CONFIG_SLUB_CPU_PARTIAL /* Number of per cpu partial objects to keep around */ unsigned int cpu_partial; #endif struct kmem_cache_order_objects oo; /* Allocation and freeing of slabs */ struct kmem_cache_order_objects max; struct kmem_cache_order_objects min; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); unsigned int inuse; /* Offset to metadata */ unsigned int align; /* Alignment */ unsigned int red_left_pad; /* Left redzone padding size */ const char *name; /* Name (only for display!) */ struct list_head list; /* List of slab caches */ unsigned int useroffset; /* Usercopy region offset */ unsigned int usersize; /* Usercopy region size */ struct kmem_cache_node *node[MAX_NUMNODES]; }; |
函数kmem_cache_create实现如下:
|
/** * kmem_cache_create - Create a cache. * @name: A string which is used in /proc/slabinfo to identify this cache.//slabinfo中显示的名字 * @size: The size of objects to be created in this cache.//slab中每个对象的大小 * @align: The required alignment for the objects.//slab中每个对象的对其要求 * @flags: SLAB flags//下面有可能的取值以及它们的含义,一般无需关注 * @ctor: A constructor for the objects.//当一个页被分配给slub时,执行的初始化函数 * * Cannot be called within a interrupt, but can be interrupted. * The @ctor is run when new pages are allocated by the cache. * * The flags are * * %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5) * to catch references to uninitialised memory. * * %SLAB_RED_ZONE - Insert `Red` zones around the allocated memory to check * for buffer overruns. * * %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware * cacheline. This can be beneficial if you're counting cycles as closely * as davem. * * Return: a pointer to the cache on success, NULL on failure. */ struct kmem_cache * kmem_cache_create(const char *name, unsigned int size, unsigned int align, slab_flags_t flags, void (*ctor)(void *)) { return kmem_cache_create_usercopy(name, size, align, flags, 0, 0, ctor); } |
|
struct kmem_cache * kmem_cache_create_usercopy(const char *name, unsigned int size, unsigned int align, slab_flags_t flags, unsigned int useroffset, unsigned int usersize, void (*ctor)(void *)) { struct kmem_cache *s = NULL; const char *cache_name; int err; get_online_cpus(); get_online_mems(); mutex_lock(&slab_mutex); /* Refuse requests with allocator specific flags */ if (flags & ~SLAB_FLAGS_PERMITTED) { err = -EINVAL; goto out_unlock; } /* * Some allocators will constraint the set of valid flags to a subset * of all flags. We expect them to define CACHE_CREATE_MASK in this * case, and we'll just provide them with a sanitized version of the * passed flags. */ flags &= CACHE_CREATE_MASK; if (!usersize) s = __kmem_cache_alias(name, size, align, flags, ctor); //在此函数中,通过调用find_mergeable,寻找已有的slub中,是否有一个可以和当前要创建的slub合并 if (s) goto out_unlock; cache_name = kstrdup_const(name, GFP_KERNEL); //如果name在用户态地址空间,那么将name拷贝到内核态地址空间 if (!cache_name) { err = -ENOMEM; goto out_unlock; } //如果没有找到能够merge的slub,我们就新创建一个slub s = create_cache(cache_name, size, calculate_alignment(flags, align, size), flags, useroffset, usersize, ctor, NULL); if (IS_ERR(s)) { err = PTR_ERR(s); kfree_const(cache_name); } out_unlock: mutex_unlock(&slab_mutex); put_online_mems(); put_online_cpus(); return s; } |
|
static struct kmem_cache *create_cache(const char *name, unsigned int object_size, unsigned int align, slab_flags_t flags, unsigned int useroffset, unsigned int usersize, void (*ctor)(void *), struct kmem_cache *root_cache) { struct kmem_cache *s; int err; s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL); //从slub中分配一个kmem_cache if (!s) goto out; s->name = name; s->size = s->object_size = object_size; //object_size就是slub中,每个结构体的大小 s->align = align; s->ctor = ctor; s->useroffset = useroffset; s->usersize = usersize; //上面这些参数的值可以通过/sys/kernel/slab/下的文件查看 err = __kmem_cache_create(s, flags); if (err) goto out_free_cache; s->refcount = 1; list_add(&s->list, &slab_caches); //slab_cached是所有slub组成的链表 out: if (err) return ERR_PTR(err); return s; } |
3.1.1:__kmem_cache_create
__kmem_cache_create在slab,slub,slob中有不同的实现。现在一般使用slub。我们看这个函数在slub.c中的实现。
|
int __kmem_cache_create(struct kmem_cache *s, slab_flags_t flags) { int err; err = kmem_cache_open(s, flags); if (err) return err; /* Mutex is not taken during early boot */ if (slab_state <= UP) return 0; err = sysfs_slab_add(s); //这个slub已经初始化完成。在sys/kernel/slab中添加对应的文件。之后,我们就可以在这个文件中看和这个slub相关的信息 if (err) __kmem_cache_release(s); return err; } |
这个函数调用kmem_cache_open,实现如下
|
static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags) { s->flags = kmem_cache_flags(s->size, flags, s->name); if (!calculate_sizes(s, -1)) //设置slub->order,返回一个slub需要多少个page,对应多少个对象 goto error; /* * The larger the object size is, the more pages we want on the partial * list to avoid pounding the page allocator excessively. */ set_min_partial(s, ilog2(s->size) / 2); //这个值可以在/sys/kernel/slab/<slab_name>/ min_partial中查看。设置了kmem_cache.min_partial。当kmem_cache.kmem_cache_node中的page数目大于min_partial,就会释放slub(也就是一个slub包含的order页) set_cpu_partial(s); //设置struct kmem_cache -> unsigned int cpu_partial。在第3节的图中我们看到,如果kmem_cache_cpu中,partical链表链接的page中的空闲slub对象数目大于cpu_partial,就会将这些page移动到kmem_cache.kmem_cache_node的partial链表中 if (!init_kmem_cache_nodes(s)) //创建并初始化kmem_cache.kmem_cache_node结构体 goto error; if (alloc_kmem_cache_cpus(s)) /* struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; ……} struct kmem_cache_cpu是一个每cpu变量。也就是每个cpu都有一个。这个结构体的内容如下 struct kmem_cache_cpu { void **freelist; /* Pointer to next available object */ unsigned long tid; /* Globally unique transaction id */ struct page *page; /* The slab from which we are allocating */ }; 这里分配这个结构体的内存。在后面适当的时候,会给这个结构体赋值 */ return 0; error: __kmem_cache_release(s); return -EINVAL; } |
3.1.2:calculate_sizes
函数calculate_sizes决定了一个slub的order,以及数据在slub中的分布。order表示了每个slub占用的内存大小(1<<order)。也就是说,一个slub可能占据多个连续的物理页
|
/* * calculate_sizes() determines the order and the distribution of data within * a slab object. */ static int calculate_sizes(struct kmem_cache *s, int forced_order) { slab_flags_t flags = s->flags; unsigned int size = s->object_size; unsigned int order; /* * Round up object size to the next word boundary. We can only * place the free pointer at word boundaries and this determines * the possible location of the free pointer. */ size = ALIGN(size, sizeof(void *)); /* * With that we have determined the number of bytes in actual use * by the object and redzoning. */ s->inuse = size; if ((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) || ((flags & SLAB_RED_ZONE) && s->object_size < sizeof(void *)) || s->ctor) { …… } else { /* * Store freelist pointer near middle of object to keep * it away from the edges of the object to avoid small * sized over/underflows from neighboring allocations. */ s->offset = ALIGN_DOWN(s->object_size / 2, sizeof(void *)); //slub->offset是偏移量。一个slub中包含了多个对象。我们可以用未分配的slub对象存放下一个未分配的slub对象的首地址,类似形成一个链表。offset就是相对于空闲object的首地址,存放下一个空闲object的首地址的地址的偏移 } /* * SLUB stores one object immediately after another beginning from * offset 0. In order to align the objects we have to simply size * each object to conform to the alignment. */ size = ALIGN(size, s->align); s->size = size; s->reciprocal_size = reciprocal_value(size); if (forced_order >= 0) order = forced_order; else order = calculate_order(size); //根据slub的每个对象的大小size,计算得到slab使用多少个页。当我们调用函数new_slab_objects给一个struct kmem_cache_cpu分配新的page的时候,就会从伙伴系统中分配1<<order个page if ((int)order < 0) return 0; s->allocflags = 0; if (order) s->allocflags |= __GFP_COMP; if (s->flags & SLAB_CACHE_DMA) s->allocflags |= GFP_DMA; if (s->flags & SLAB_CACHE_DMA32) s->allocflags |= GFP_DMA32; if (s->flags & SLAB_RECLAIM_ACCOUNT) s->allocflags |= __GFP_RECLAIMABLE; /* * Determine the number of objects per slab */ s->oo = oo_make(order, size); //oo记录了slub的order,还记录了一个slub总可以容纳多少个对象 s->min = oo_make(get_order(size), size); if (oo_objects(s->oo) > oo_objects(s->max)) s->max = s->oo; return !!oo_objects(s->oo); } |
3.2:给slub分配内存
我们在上面的内容中,创建了一个slub。但是,这个slub还没有内存。因此,我们在使用这个slub的时候,会给这个slub分配页,再从这个slub中分配对象。
上面这个过程的调用链是:kmalloc -> __kmalloc -> slab_alloc -> slab_alloc_node -> __slab_alloc -> ___slab_alloc -> new_slab_objects。也就是说,当要给slub从伙伴系统分配新的page的时候,调用函数new_slab_objects。
|
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags, int node, struct kmem_cache_cpu **pc) { void *freelist; struct kmem_cache_cpu *c = *pc; struct page *page; WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO)); freelist = get_partial(s, flags, node, c); if (freelist) return freelist; //上面的内容会在3.3:kmalloc分配内存中讨论。上面的流程没有走到伙伴系统中做分配 page = new_slab(s, flags, node); //从伙伴系统中分配page给slub if (page) { c = raw_cpu_ptr(s->cpu_slab); if (c->page) flush_slab(s, c); /* * No other reference to the page yet so we can * muck around with it freely without cmpxchg */ freelist = page->freelist; //freelist指向了page对应的物理页的虚拟地址首地址,也是存放第一个空闲的slub对象的首地址 page->freelist = NULL; stat(s, ALLOC_SLAB); c->page = page; //page和freelist是对应的。freelist就是page描述的页面的虚拟地址首地址 *pc = c; } return freelist; } |
|
static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node) { return allocate_slab(s, flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node); } |
|
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node) { struct page *page; struct kmem_cache_order_objects oo = s->oo; gfp_t alloc_gfp; void *start, *p, *next; int idx; bool shuffle; flags &= gfp_allowed_mask; if (gfpflags_allow_blocking(flags)) local_irq_enable(); flags |= s->allocflags; /* * Let the initial higher-order allocation fail under memory pressure * so we fall-back to the minimum order allocation. */ alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL; if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min)) alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~(__GFP_RECLAIM|__GFP_NOFAIL); page = alloc_slab_page(s, alloc_gfp, node, oo); //从伙伴系统中分配出oo_order(oo)个页 page->objects = oo_objects(oo); //一个slub可能包含多个page,这个slub包含的总对象数目放入objects中 page->slab_cache = s; __SetPageSlab(page); if (page_is_pfmemalloc(page)) SetPageSlabPfmemalloc(page); start = page_address(page); //通过page,获得它对应的虚拟地址。这种地址都是直接映射的地址(物理地址和虚拟地址之间是线性关系)。这种虚拟地址从0xffff888000000000开始 if (1) { start = fixup_red_left(s, start); start = setup_object(s, page, start); page->freelist = start; //因此,page->freeelist就是page对应的虚拟地址首地址 for (idx = 0, p = start; idx < page->objects - 1; idx++) { next = p + s->size; next = setup_object(s, page, next); set_freepointer(s, p, next); //将*(p+s->offset) = next。next是下一个空闲的对象块。将他的地址存放在上一个空闲对象块+s->offset处 p = next; } set_freepointer(s, p, NULL); //最后一个slub对象的p+s->offset = NULL } page->inuse = page->objects; page->frozen = 1; out: if (gfpflags_allow_blocking(flags)) local_irq_disable(); if (!page) return NULL; inc_slabs_node(s, page_to_nid(page), page->objects); return page; } |
因此,我们知道了slub是如何管理空闲对象的分配的。
1:struct kmem_cache -> struct kmem_cache_cpu -> freelist 表示了当前slub中空闲对象的地址。
2:struct kmem_cache -> struct kmem_cache_cpu -> freelist + struct kmem_cache ->offset 表示了当前slub中下一个空闲对象的地址
3:每次做分配操作的时候,分配的对象是struct kmem_cache -> struct kmem_cache_cpu -> freelist ,然后将freelist指向下一个空闲对象,也就是 freelist + offset。
4:每次做释放操作的时候,将freelist指向释放的对象,然后freelist + offset 变成之前freelist的地址。
3.3:kmalloc分配内存
这一节我们描述slub是如何进行内存分配的。我们已经知道,内存分配的接口是kmalloc或者kmem_cache_alloc。他们调用链为:
|
kmalloc -> __kmalloc -> slab_alloc kmem_cache_alloc -> slab_alloc |
函数slab_alloc的实现如下
|
static __always_inline void *slab_alloc(struct kmem_cache *s, gfp_t gfpflags, unsigned long addr) { return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr); } |
我们在创建一个kmem_cache_t的时候,会给每个cpu创建单独的slub成员链表,并组织在每cpu变量struct kmem_cache_cpu中。这样的好处是避免多cpu之间并发带来的锁开销。重申struct kmem_cache_cpu结构体定义如下:
|
struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; …… }; |
|
struct kmem_cache_cpu { void **freelist; /* Pointer to next available object */ unsigned long tid; /* Globally unique transaction id */ struct page *page; /* The slab from which we are allocating */ }; |
因此,我们要给slub分配内存,并且根据分配的内存赋值struct kmem_cache_cpu中的成员。
3.3.1:slab_alloc_node
函数slab_alloc_node实现如下
|
//和伙伴系统中的分配类似,这里也有快速路径以及慢速路径两种分配方式 gfp_t gfpflags, int node, unsigned long addr) { void *object; struct kmem_cache_cpu *c; struct page *page; unsigned long tid; struct obj_cgroup *objcg = NULL; s = slab_pre_alloc_hook(s, &objcg, 1, gfpflags); if (!s) return NULL; redo: /* * Must read kmem_cache cpu data via this cpu ptr. Preemption is * enabled. We may switch back and forth between cpus while * reading from one cpu area. That does not matter as long * as we end up on the original cpu again when doing the cmpxchg. * * We should guarantee that tid and kmem_cache are retrieved on * the same cpu. It could be different if CONFIG_PREEMPTION so we need * to check if it is matched or not. */ do { tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); } while (IS_ENABLED(CONFIG_PREEMPTION) && unlikely(tid != READ_ONCE(c->tid))); //已经说过,struct kmem_cache_cpu结构体存储了当前cpu对应的slub对象链表 /* * Irqless object alloc/free algorithm used here depends on sequence * of fetching cpu_slab's data. tid should be fetched before anything * on c to guarantee that object and page associated with previous tid * won't be used with current tid. If we fetch tid first, object and * page could be one associated with next tid and our alloc/free * request will be failed. In this case, we will retry. So, no problem. */ barrier(); /* * The transaction ids are globally unique per cpu and per operation on * a per cpu queue. Thus they can be guarantee that the cmpxchg_double * occurs on the right processor and that there was no operation on the * linked list in between. */ object = c->freelist; //freelist是这个cpu的slub中,空闲对象的首地址 page = c->page; if (unlikely(!object || !page || !node_match(page, node))) { object = __slab_alloc(s, gfpflags, node, addr, c); //慢速分配流程 } else { //快速分配流程。这时候freelist就是空闲对象 void *next_object = get_freepointer_safe(s, object); //这个宏展开就是: (void *)*(unsigned long *)(object + s->offset)。我们已经说过,slub中用未分配的slub存放下一个未分配的slub对象的地址,offset就是偏移。因此,这里拿到了下一个空闲object的首地址 /* * The cmpxchg will only match if there was no additional * operation and if we are on the right processor. * * The cmpxchg does the following atomically (without lock * semantics!) * 1. Relocate first pointer to the current per cpu area. * 2. Verify that tid and freelist have not been changed * 3. If they were not changed replace tid and freelist * * Since this is without lock semantics the protection is only * against code executing on this cpu *not* from access by * other cpus. *///this_cpu_cmpxchg_double比较参数1,2和参数3,4是否相等。如果是的话,将参数5,6设置给参数1,2.其实就是将next_object设置给s->cpu_slab->freelist if (unlikely(!this_cpu_cmpxchg_double( s->cpu_slab->freelist, s->cpu_slab->tid, object, tid, next_object, next_tid(tid)))) { note_cmpxchg_failure("slab_alloc", s, tid); goto redo; } prefetch_freepointer(s, next_object); stat(s, ALLOC_FASTPATH); } maybe_wipe_obj_freeptr(s, object); if (unlikely(slab_want_init_on_alloc(gfpflags, s)) && object) memset(object, 0, s->object_size); slab_post_alloc_hook(s, objcg, gfpflags, 1, &object); return object; } |
因此,在快速路径下,我们直接拿到struct kmem_cache -> struct kmem_cache_cpu ->freelist,作为这次分配出来的slub对象。
3.3.2:___slab_alloc
除了上面的快速路径,还有慢速路径。并且,当第一次做slub分配的时候,也会走到慢速路径。这时候,struct kmem_cache_cpu上没有空闲的slub待使用。
|
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr, struct kmem_cache_cpu *c) { void *p; unsigned long flags; local_irq_save(flags); #ifdef CONFIG_PREEMPTION /* * We may have been preempted and rescheduled on a different * cpu before disabling interrupts. Need to reload cpu area * pointer. *///重新获取struct kmem_cache_cpu c = this_cpu_ptr(s->cpu_slab); #endif p = ___slab_alloc(s, gfpflags, node, addr, c); local_irq_restore(flags); return p; } |
|
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr, struct kmem_cache_cpu *c) { void *freelist; struct page *page; stat(s, ALLOC_SLOWPATH); page = c->page; //c->page可以看作是slub当前正在使用的page。freelist应该是和page配套的 if (!page) { //当slub刚刚创建,还没有对应的内存的时候,page为NULL /* * if the node is not online or has no normal memory, just * ignore the node constraint */ if (unlikely(node != NUMA_NO_NODE && !node_state(node, N_NORMAL_MEMORY))) node = NUMA_NO_NODE; goto new_slab; } redo: /* must check again c->freelist in case of cpu migration or IRQ *///如果这时候,freelist不为空,可能是在进入慢速路径的时候,这个上面又有了空闲的slub。从注释看,可能是中断或者进程迁移造成的 freelist = c->freelist; if (freelist) goto load_freelist; freelist = get_freelist(s, page); //这里的page是struct kmem_cache_cpu.page。因为new_slab中有redo,所以这时候的page可能是进入此函数时,struct kmem_cache_cpu就带有的page,或者struct kmem_cache_cpu.partical上的page。这个函数最重要的作用就是返回page->freelist,并将page->freelist=NULL if (!freelist) { //这种情况下,说明struct kmem_cache_cpu.page也不包含空闲对象 c->page = NULL; stat(s, DEACTIVATE_BYPASS); goto new_slab; //分配新的page } stat(s, ALLOC_REFILL); load_freelist: /* * freelist is pointing to the list of objects to be used. * page is pointing to the page from which the objects are obtained. * That page must be frozen for per cpu allocations to work. */ VM_BUG_ON(!c->page->frozen); c->freelist = get_freepointer(s, freelist); //返回第一个空闲对象,将freelist设置为第二个空闲对象 c->tid = next_tid(c->tid); return freelist; new_slab: //给kmem_cache_cpu创建新的slub(分配kmem_cache.order个页) if (slub_percpu_partial(c)) { //如果kmem_cache_cpu.partical上有page的话,就从这些page上面分。partical是部分分配的页 page = c->page = slub_percpu_partial(c); //将c->page设置为c->partical slub_set_percpu_partial(c, page); //将c->partical设置为之前partical页的下一页 stat(s, CPU_PARTIAL_ALLOC); //将struct kmem_cache_cpu.page设置为struct kmem_cache_cpu.partical。然后将struct kmem_cache_cpu.partical设置为next page goto redo; } //我们走到这里,一定是遍历了kmem_cache_cpu.partical中所有的页,都没有找到空闲对象。这时候必须分配新的slub freelist = new_slab_objects(s, gfpflags, node, &c); //这里就会通过伙伴系统给slub分配新的page,返回的freelist就是slub对象的指针 if (unlikely(!freelist)) { slab_out_of_memory(s, gfpflags, node); return NULL; } page = c->page; if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags))) goto load_freelist; //在分配新的page之后,这里会跳回到load_freelist处执行。然后,就会将c->freelist = get_freepointer(s, freelist),也就是第二个空闲slub对象的地址 /* Only entered in the debug case */ if (kmem_cache_debug(s) && !alloc_debug_processing(s, page, freelist, addr)) goto new_slab; /* Slab failed checks. Next slab needed */ deactivate_slab(s, page, get_freepointer(s, freelist), c); return freelist; } |
除了上面描述的每个cpu的struct kmem_cache_cpu链接的partical链表之外,还有一个partical链表,也就是每个node的partical链表。我们在函数___slab_alloc中搜索了所有的struct kmem_cache_cpu链接的partical链表。之后,我们会在new_slab_objects -> get_partial中搜索每个node的partical链表。
|
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags, int node, struct kmem_cache_cpu **pc) { void *freelist; struct kmem_cache_cpu *c = *pc; struct page *page; WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO)); freelist = get_partial(s, flags, node, c); //从kmem_cache_node找空闲对象 if (freelist) return freelist; page = new_slab(s, flags, node); //还是没有的话,就是kmem_cache_cpu和kmem_cache_node中都没有空闲对象了,所以要从伙伴系统中分配。这个函数已经在3.2节中描述过了 if (page) { c = raw_cpu_ptr(s->cpu_slab); if (c->page) flush_slab(s, c); /* * No other reference to the page yet so we can * muck around with it freely without cmpxchg */ freelist = page->freelist; page->freelist = NULL; stat(s, ALLOC_SLAB); c->page = page; *pc = c; } return freelist; } |
|
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node, struct kmem_cache_cpu *c) { void *object; int searchnode = node; if (node == NUMA_NO_NODE) searchnode = numa_mem_id(); object = get_partial_node(s, get_node(s, searchnode), c, flags); //找我们struct kmem_cache对应当前node的partial链表中,是否有空闲对象。返回找到的第一个空闲对象 if (object || node != NUMA_NO_NODE) return object; return get_any_partial(s, flags, c); //找其他NUMA节点中,是否有struct list_head partial链接的page。在UMA中就是return NULL } |
|
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n, struct kmem_cache_cpu *c, gfp_t flags) { struct page *page, *page2; void *object = NULL; unsigned int available = 0; int objects; /* * Racy check. If we mistakenly see no partial slabs then we * just allocate an empty slab. If we mistakenly try to get a * partial slab and there is none available then get_partial() * will return NULL. *///struct kmem_cache_node->partical是一个空链表的时候,我们直接返回NULL if (!n || !n->nr_partial) return NULL; spin_lock(&n->list_lock); list_for_each_entry_safe(page, page2, &n->partial, slab_list) { //遍历struct kmem_cache_node的partical链表,每个成员都是一个page void *t; t = acquire_slab(s, n, page, object == NULL, &objects); //我们将每个page的空闲对象数目存到objects上(new.objects - new.inuse),将page从struct kmem_cache_node->partical链表上移除 if (!t) break; available += objects; //available是从kmem_cache_node移动到kmem_cache_cpu的空闲对象总数目 if (!object) { c->page = page; //如果是第一个page,那么设置struct kmem_cache_cpu.page=page。作为后面slub分配使用的page,他遵守1:page.freelist=null;2:page.inuse=.page.objects;3:page.frozen=1 stat(s, ALLOC_FROM_PARTIAL); object = t; } else { put_cpu_partial(s, page, 0); //后续的page不做这种处理,只是将这些page添加到kmem_cache_cpu.partical链表上。因此,会将多个partical页从kmem_cache_node移动到kmem_cache_cpu上 stat(s, CPU_PARTIAL_NODE); } if (!kmem_cache_has_cpu_partial(s) || available > slub_cpu_partial(s) / 2) //如果从kmem_cache_node移动的可用对象数目大于kmem_cache.cpu_partial/2,我们就不再移动了。重申,kmem_cache.cpu_partial可以在/sys/kernel/slab/X/cpu_partial查看 break; } spin_unlock(&n->list_lock); return object; } |
总结,上面的分配流程有一下三步,也就是从freelist中分配,或者将c->partical中的页赋给c->page,然后再从c->freelist中分配,或者将node->partical中的页分配c->page与c->partical,然后从c->freelist中分配。
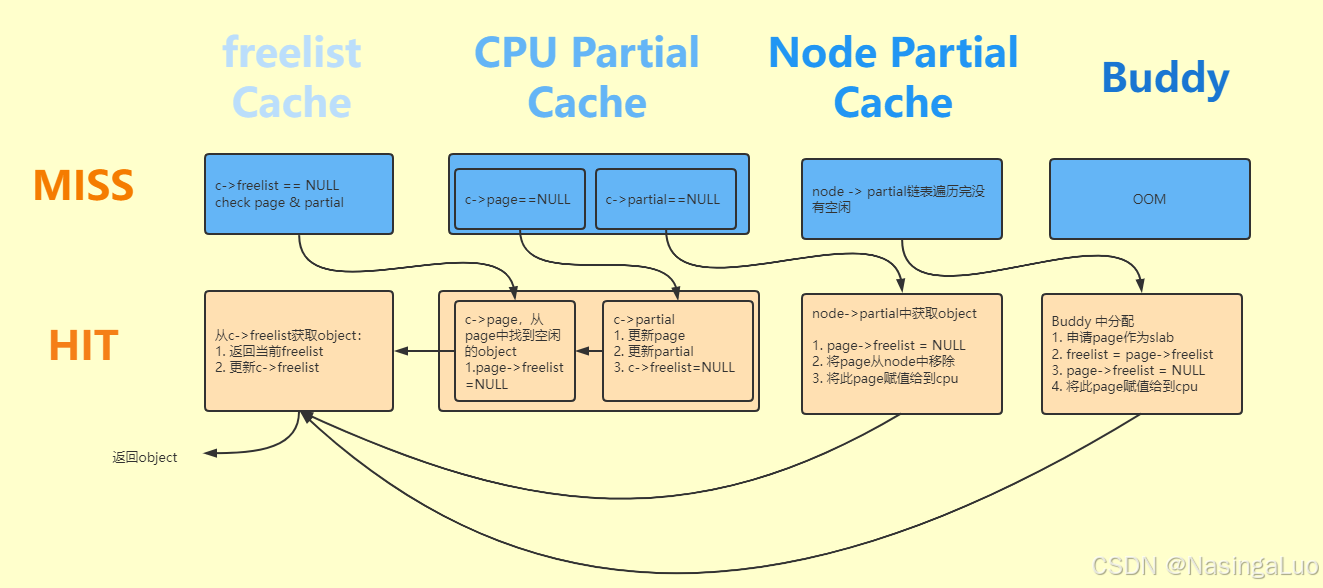
3.4:kfree释放内存
函数kfree的实现如下:
|
void kfree(const void *x) { struct page *page; void *object = (void *)x; page = virt_to_head_page(x); slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_); //可见,参数分别是slub结构体,page结构体和要释放的对象的首地址 } |
|
static __always_inline void slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { if (slab_free_freelist_hook(s, &head, &tail, &cnt)) //这个函数不影响正常流程的执行 do_slab_free(s, page, head, tail, cnt, addr); } |
函数do_slab_free的实现如下。他的入参可以认为和slab_free的入参没有变化。
|
static __always_inline void do_slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { void *tail_obj = tail ? : head; struct kmem_cache_cpu *c; unsigned long tid; redo: /* * Determine the currently cpus per cpu slab. * The cpu may change afterward. However that does not matter since * data is retrieved via this pointer. If we are on the same cpu * during the cmpxchg then the free will succeed. */ do { tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); } while (IS_ENABLED(CONFIG_PREEMPTION) && unlikely(tid != READ_ONCE(c->tid))); /* Same with comment on barrier() in slab_alloc_node() */ barrier(); if (likely(page == c->page)) { //我们从分配的一节知道,struct kmem_cache_cpu.page和struct kmem_cache_cpu.freelist是对应的。因此,如果要释放的slub的page和当前的c->page是一样的,那么直接释放到当前的freelist就行。这也是快速释放 void **freelist = READ_ONCE(c->freelist); set_freepointer(s, tail_obj, freelist); //这时候,让释放的slub对象存放freelist。也就是,我们释放的slub对象放在开头 if (unlikely(!this_cpu_cmpxchg_double( //通过这个函数,设置s->cpu_slab->freelist为head s->cpu_slab->freelist, s->cpu_slab->tid, freelist, tid, head, next_tid(tid)))) { note_cmpxchg_failure("slab_free", s, tid); goto redo; } stat(s, FREE_FASTPATH); } else __slab_free(s, page, head, tail_obj, cnt, addr); } |
3.4.1:慢速路径释放——__slab_free
慢速分配的路径中,我们从struct kmem_cache_cpu.partical中分,不行的话就从struct kmem_cache_node.partical中分。最后在不行的话就从伙伴系统从分配页。因此,对应释放的时候,也可能释放到struct kmem_cache_cpu.partical或者struct kmem_cache_node.partical。这时候,实际上是要释放的slub,不属于当前的kmem_cache_cpu.page。这种情况很好理解,例如我们要释放的是很久之前分配的slub。这个时候,我们就不能将对象地址添加到kmem_cache.freelist链表中,而要添加到其他的链表中。因为freelist和page一定是对应的
|
static void __slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) //这时,head=tail,是要释放的对象地址 { void *prior; int was_frozen; struct page new; unsigned long counters; struct kmem_cache_node *n = NULL; unsigned long flags; stat(s, FREE_SLOWPATH); do { if (unlikely(n)) { spin_unlock_irqrestore(&n->list_lock, flags); n = NULL; } prior = page->freelist; //这个page先前的空闲对象 counters = page->counters; set_freepointer(s, tail, prior); //tail和head是同一个指针,指向了这次要释放的对象。因此,将释放的对象放在freelist的最前面 new.counters = counters; was_frozen = new.frozen; //在kmem_cache_cpu上的page是被frozen的 new.inuse -= cnt; if ((!new.inuse || !prior) && !was_frozen) { //inuse=0,表示这个page中所有slub被释放。prior=0,表示这个page中所有对象都被分出去,是全分配 if (kmem_cache_has_cpu_partial(s) && !prior) { //这个page之前是全部分配。全部分配的page不在kmem_cache_cpu和kmem_cache_node的partical链表上,而是被提出来了 /* * Slab was on no list before and will be * partially empty * We can defer the list move and instead * freeze it. */ new.frozen = 1; //设置page的frozen标志。我们还暂时不处理这个page,不将他移动到任何partical链表上 } else { /* Needs to be taken off a list *///现在,page中所有对象都空闲,并且之前不是frozen状态,也就是page在struct kmem_cache->node[node]链表上 n = get_node(s, page_to_nid(page)); /* * Speculatively acquire the list_lock. * If the cmpxchg does not succeed then we may * drop the list_lock without any processing. * * Otherwise the list_lock will synchronize with * other processors updating the list of slabs. */ spin_lock_irqsave(&n->list_lock, flags); } } } while (!cmpxchg_double_slab(s, page, //将释放的对象设置为page->freelist prior, counters, head, new.counters, "__slab_free")); if (likely(!n)) { //当page中并非所有slub空闲会走到这儿 if (likely(was_frozen)) { /* * The list lock was not taken therefore no list * activity can be necessary. *///之前page属于cpu_partial,这里简单更改freelist后,返回 stat(s, FREE_FROZEN); } else if (new.frozen) { /* * If we just froze the page then put it onto the * per cpu partial list. */ put_cpu_partial(s, page, 1); //之前page是全分配,全分配的页不在任何链表上。会走到这里。将page的freelist更改后,并且froze page,再添加到cpu_partial上 stat(s, CPU_PARTIAL_FREE); } return; /* 1:之前page属于node_partical,这次释放后不是全不分配,会走到这里,简单更改page的freelist后返回 2:之前page属于cpu_partical, */ } //只有当这个page中的所有slub都是空闲,并且page在struct kmem_cache->node[node]链表上的时候会走到这里 if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) //之前page属于node_partical,这次释放后是全不分配,并且node中nr_partial 过多,会走到这里,将page释放到伙伴系统 goto slab_empty; …… spin_unlock_irqrestore(&n->list_lock, flags); return; //之前page属于node_partical,这次释放后是全不分配,并且node中nr_partial数目不多,会走到这里,简单改freelist后返回 slab_empty: if (prior) { /* * Slab on the partial list. */ remove_partial(n, page); stat(s, FREE_REMOVE_PARTIAL); } else { /* Slab must be on the full list */ remove_full(s, n, page); //这个函数什么也不做 } spin_unlock_irqrestore(&n->list_lock, flags); stat(s, FREE_SLAB); discard_slab(s, page); } |
4:vmalloc
我们一般使用vmalloc来分配大块内存。他会首先给内核创建一个struct vm_struct,用于存储虚拟地址空间,然后通过伙伴系统分配物理页面,并建立虚拟地址和物理地址之间的映射。vmalloc的实现如下
|
void *vmalloc(unsigned long size) { return __vmalloc_node(size, 1, GFP_KERNEL, NUMA_NO_NODE, //GFP_KERNEL表示在分配过程中,可能会发生内存回收,甚至是进程被阻塞,做直接回收。因此,vmalloc不能使用在原子路径上 __builtin_return_address(0)); } |
|
void *__vmalloc_node(unsigned long size, unsigned long align, gfp_t gfp_mask, int node, const void *caller) { return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END, gfp_mask, PAGE_KERNEL, 0, node, caller); //VMALLOC_START, VMALLOC_END是内核中,用于vmalloc的虚拟地址空间的起始和结束地址。我们可以通过linux/Documentation/arm64/memory.rst查看这两个值 } |
|
void *__vmalloc_node_range(unsigned long size, unsigned long align, unsigned long start, unsigned long end, gfp_t gfp_mask, pgprot_t prot, unsigned long vm_flags, int node, const void *caller) { struct vm_struct *area; void *addr; unsigned long real_size = size; size = PAGE_ALIGN(size); if (!size || (size >> PAGE_SHIFT) > totalram_pages()) goto fail; area = __get_vm_area_node(real_size, align, VM_ALLOC | VM_UNINITIALIZED | //分配vm_struct,用于存储虚拟地址空间结构体 vm_flags, start, end, node, gfp_mask, caller); if (!area) goto fail; addr = __vmalloc_area_node(area, gfp_mask, prot, node); //分配物理页面,并和vm_struct做映射 if (!addr) return NULL; /* * In this function, newly allocated vm_struct has VM_UNINITIALIZED * flag. It means that vm_struct is not fully initialized. * Now, it is fully initialized, so remove this flag here. */ clear_vm_uninitialized_flag(area); return addr; } |
4.1:__get_vm_area_node——分配vm_struct,vmap_area
函数__get_vm_area_node的作用是分配struct vm_struct和struct vmap_area。内核中可能有许多个vm_struct和vmap_area,他们之间是一一对应的关系。为了能够更快的找到某个地址对应的数据结构图,我们会将struct vmap_area组织成为一棵红黑树。函数实现如下:
|
static struct vm_struct *__get_vm_area_node(unsigned long size, unsigned long align, unsigned long flags, unsigned long start, unsigned long end, int node, gfp_t gfp_mask, const void *caller) { struct vmap_area *va; struct vm_struct *area; unsigned long requested_size = size; BUG_ON(in_interrupt()); size = PAGE_ALIGN(size); if (flags & VM_IOREMAP) align = 1ul << clamp_t(int, get_count_order_long(size), PAGE_SHIFT, IOREMAP_MAX_ORDER); area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node); //分配struct vm_struct占用的内存 if (!(flags & VM_NO_GUARD)) //如果没有设置VM_NO_GUARD,我们会给size多加一个page,作为保护页 size += PAGE_SIZE; va = alloc_vmap_area(size, align, start, end, node, gfp_mask); //分配结构体struct vmap_area结构体并初始化。 if (IS_ERR(va)) { kfree(area); return NULL; } kasan_unpoison_vmalloc((void *)va->va_start, requested_size); setup_vmalloc_vm(area, va, flags, caller); //struct vmap_area -> vm = struct vm_struct return area; } |
函数alloc_vmap_area的实现如下所示
|
static struct vmap_area *alloc_vmap_area(unsigned long size, unsigned long align, unsigned long vstart, unsigned long vend, int node, gfp_t gfp_mask) { struct vmap_area *va, *pva; unsigned long addr; int purged = 0; int ret; gfp_mask = gfp_mask & GFP_RECLAIM_MASK; va = kmem_cache_alloc_node(vmap_area_cachep, gfp_mask, node); //从kmem_cache中分配一个struct vmap_area结构体 if (unlikely(!va)) return ERR_PTR(-ENOMEM); retry: …… /* * If an allocation fails, the "vend" address is * returned. Therefore trigger the overflow path. */ addr = __alloc_vmap_area(size, align, vstart, vend); //这里通过红黑树free_vmap_area_root找到了一个合适的vmap_area,也就是一个满足需求的线性地址空间。这里返回线性地址空间的首地址 spin_unlock(&free_vmap_area_lock); va->va_start = addr; va->va_end = addr + size; va->vm = NULL; spin_lock(&vmap_area_lock); insert_vmap_area(va, &vmap_area_root, &vmap_area_list); //类似于空闲的vmap_area会构成free_vmap_area_root红黑树,使用中的vmap_area也会构成vmap_area_root红黑树 spin_unlock(&vmap_area_lock); return va; } |
|
static __always_inline unsigned long __alloc_vmap_area(unsigned long size, unsigned long align, unsigned long vstart, unsigned long vend) { unsigned long nva_start_addr; struct vmap_area *va; enum fit_type type; int ret; va = find_vmap_lowest_match(size, align, vstart); //这个函数在红黑树free_vmap_area_root中,找到满足size,vstart的空闲虚拟地址空间。free_vmap_area_root是空闲的struct vmap_area构成的红黑树,vmap_area起始地址越小,他在红黑树中的位置越靠左 if (unlikely(!va)) return vend; if (va->va_start > vstart) nva_start_addr = ALIGN(va->va_start, align); else nva_start_addr = ALIGN(vstart, align); //上面的nva_start_addr就是我们这次要分配出去的struct vmap_area的起始地址 /* Check the "vend" restriction. */ if (nva_start_addr + size > vend) return vend; /* Classify what we have found. */ type = classify_va_fit_type(va, nva_start_addr, size); if (WARN_ON_ONCE(type == NOTHING_FIT)) return vend; //我们要分配一段size大小的虚拟地址空间。这时候我们找到了一个struct vmap_area。但是,这个vmap_area和size之间可能不是完全匹配。因此,我们这里获取他的匹配程度,分别是FL_FIT_TYPE(完全匹配),LE_FIT_TYPE(左匹配),RE_FIT_TYPE(右匹配),NE_FIT_TYPE(非边缘匹配)。对于不是完全匹配的struct vmap_area,我们可能需要将剩下的线性地址空间再次插入红黑树free_vmap_area_root中 /* Update the free vmap_area. */ ret = adjust_va_to_fit_type(va, nva_start_addr, size, type); //这里就是我们在上面的注释中描述的逻辑,将剩余的线性地址空间插入红黑树中 if (ret) return vend; return nva_start_addr; } |
因此,我们看到,在给vmalloc分配虚拟地址空间的时候,需要用到内核中的free_vmap_area_root数据结构。他存放了系统中所有空闲的vmap_area,也就是系统中,vmalloc可用的空闲虚拟地址空间。而正在使用的虚拟地址空间,存放在红黑树vmap_area_root中。
4.2:__vmalloc_area_node——分配物理页,并建立虚拟地址和物理地址之间的映射
函数__vmalloc_area_node的实现如下
|
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask, pgprot_t prot, int node) { const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO; unsigned int nr_pages = get_vm_area_size(area) >> PAGE_SHIFT; unsigned int array_size = nr_pages * sizeof(struct page *), i; struct page **pages; //使用page数组存放后面分出来的page指针 gfp_mask |= __GFP_NOWARN; if (!(gfp_mask & (GFP_DMA | GFP_DMA32))) gfp_mask |= __GFP_HIGHMEM; /* Please note that the recursion is strictly bounded. */ if (array_size > PAGE_SIZE) { pages = __vmalloc_node(array_size, 1, nested_gfp, node, area->caller); } else { pages = kmalloc_node(array_size, nested_gfp, node); } //上面分配page数组使用的内存。可见,如果要分配的数组大小太大的时候,可能会嵌套调用_vmalloc area->pages = pages; area->nr_pages = nr_pages; for (i = 0; i < area->nr_pages; i++) { struct page *page; if (node == NUMA_NO_NODE) page = alloc_page(gfp_mask); //从伙伴系统中分配页 else page = alloc_pages_node(node, gfp_mask, 0); area->pages[i] = page; if (gfpflags_allow_blocking(gfp_mask)) cond_resched(); } atomic_long_add(area->nr_pages, &nr_vmalloc_pages); if (map_kernel_range((unsigned long)area->addr, get_vm_area_size(area), //通过这个函数做vmalloc虚拟地址空间和物理地址空间之间的映射。这里get_vm_area_size很有讲究,它不映射保护页。因此,当内存越界访问到保护页的时候,就会发生缺页异常报错。此外,需要知道的是,我们这里将映射添加到页表swapper_pg_dir中 prot, pages) < 0) goto fail; return area->addr; } |
我们看到,上面通过vmalloc更新了页表swapper_pg_dir中的页表项。同时,我们还知道,不管是内核线程,或者是在内核态执行的用户进程,在访问内核地址的时候,都是使用页表swapper_pg_dir。因此,映射之后,所有进程都能够访问这个映射的地址。
5:out of memory
这个函数就是我们熟知的oom流程。在系统内存不足的时候,会选出一个进程杀掉。
|
/** * out_of_memory - kill the "best" process when we run out of memory * @oc: pointer to struct oom_control * * If we run out of memory, we have the choice between either * killing a random task (bad), letting the system crash (worse) * OR try to be smart about which process to kill. Note that we * don't have to be perfect here, we just have to be good. */ bool out_of_memory(struct oom_control *oc) { unsigned long freed = 0; if (oom_killer_disabled) return false; /* * If current has a pending SIGKILL or is exiting, then automatically * select it. The goal is to allow it to allocate so that it may * quickly exit and free its memory. */ if (task_will_free_mem(current)) { //在这里检查current是否正要退出。如果是的话,就选择杀死current进程 mark_oom_victim(current); wake_oom_reaper(current); //唤醒内核线程oom_reaper处理 return true; } /* * The OOM killer does not compensate for IO-less reclaim. * pagefault_out_of_memory lost its gfp context so we have to * make sure exclude 0 mask - all other users should have at least * ___GFP_DIRECT_RECLAIM to get here. But mem_cgroup_oom() has to * invoke the OOM killer even if it is a GFP_NOFS allocation. */ if (oc->gfp_mask && !(oc->gfp_mask & __GFP_FS) && !is_memcg_oom(oc)) return true; /* * Check if there were limitations on the allocation (only relevant for * NUMA and memcg) that may require different handling. */ oc->constraint = constrained_alloc(oc); if (oc->constraint != CONSTRAINT_MEMORY_POLICY) oc->nodemask = NULL; check_panic_on_oom(oc); //检查发生oom的时候,是否要做系统panic。一般不做 if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task && //如果设置了sysctl_oom_kill_allocating_task,则发生oom的时候,会将当前要内存分配的进程杀掉。这个值可以通过/proc/sys/vm/oom_kill_allocating_task设置 current->mm && !oom_unkillable_task(current) && oom_cpuset_eligible(current, oc) && current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) { get_task_struct(current); oc->chosen = current; oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)"); //这时候,杀死导致内存分配失败的进程,而不是选择一个进程杀死 return true; } select_bad_process(oc); //一般流程,我们选择一个进程杀死 /* Found nothing?!?! */ if (!oc->chosen) { dump_header(oc, NULL); pr_warn("Out of memory and no killable processes...\n"); /* * If we got here due to an actual allocation at the * system level, we cannot survive this and will enter * an endless loop in the allocator. Bail out now. */ if (!is_sysrq_oom(oc) && !is_memcg_oom(oc)) panic("System is deadlocked on memory\n"); } if (oc->chosen && oc->chosen != (void *)-1UL) oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" : //杀死我们选择的进程 "Memory cgroup out of memory"); return !!oc->chosen; } |
5.1:select_bad_process——选择一个进程杀死
一般情况下,我们会找到系统中一个合适的进程杀掉来解决oom。
|
/* * Simple selection loop. We choose the process with the highest number of * 'points'. In case scan was aborted, oc->chosen is set to -1. */ static void select_bad_process(struct oom_control *oc) { oc->chosen_points = LONG_MIN; if (is_memcg_oom(oc)) mem_cgroup_scan_tasks(oc->memcg, oom_evaluate_task, oc); else { struct task_struct *p; rcu_read_lock(); for_each_process(p) //遍历系统中的所有进程。通过task_struct -> tasks.next完成遍历 if (oom_evaluate_task(p, oc)) break; rcu_read_unlock(); } } |
|
static int oom_evaluate_task(struct task_struct *task, void *arg) { struct oom_control *oc = arg; long points; if (oom_unkillable_task(task)) //内核线程,和进程1属于同一个线程组的进程不能杀 goto next; …… points = oom_badness(task, oc->totalpages); //计算当前进程的oom得分 if (points == LONG_MIN || points < oc->chosen_points) //我们最终杀死得分最高的那个进程 goto next; select: if (oc->chosen) put_task_struct(oc->chosen); get_task_struct(task); oc->chosen = task; oc->chosen_points = points; next: return 0; abort: if (oc->chosen) put_task_struct(oc->chosen); oc->chosen = (void *)-1UL; return 1; } |
|
long oom_badness(struct task_struct *p, unsigned long totalpages) { long points; long adj; if (oom_unkillable_task(p)) return LONG_MIN; p = find_lock_task_mm(p); if (!p) return LONG_MIN; /* * Do not even consider tasks which are explicitly marked oom * unkillable or have been already oom reaped or the are in * the middle of vfork */ adj = (long)p->signal->oom_score_adj; //可以通过/proc/PID/oom_score_adj查看 if (adj == OOM_SCORE_ADJ_MIN || //oom_score_adj设置为-1000的进程不会被oom杀死 test_bit(MMF_OOM_SKIP, &p->mm->flags) || in_vfork(p)) { task_unlock(p); return LONG_MIN; } /* * The baseline for the badness score is the proportion of RAM that each * task's rss, pagetable and swap space use. */ points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) + mm_pgtables_bytes(p->mm) / PAGE_SIZE; //计算进程使用的页数 task_unlock(p); /* Normalize to oom_score_adj units */ adj *= totalpages / 1000; points += adj; //将分数做处理后,返回分数 return points; } |
每个进程的oom得分数还可以通过/proc/pid/oom_score查看。

















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









