




1:内存地址
逻辑地址:在x86结构中,每一个逻辑地址都由两部分组成:一个16位的存储在段寄存器中的段选择符、还有一个32位的偏移量。偏移量指明了从段开始的地方到实际地址的偏移。逻辑地址就是我们反汇编看到的地址,比如0x3f00000。而存储在段寄存器中的段选择符是从反汇编出来的文件中看不到的。
线性地址:也叫做虚拟地址,32位无符号整数,可以用来表达高达4GB的地址。是由逻辑地址生成的。
物理地址:
MMU中通过分段单元的硬件电路将逻辑地址转化成线性地址。然后在分页单元中,将线性地址转换成物理地址。
本章中,分段的目的是将逻辑地址转换成线性地址;分页的目的是将线性地址转化成物理地址。之所以又有硬件,又有软件,是因为硬件提供了寻址能力,软件要为硬件的寻址能力服务,设置好硬件寻址需要的数据结构等内容。
2:硬件中的分段
intel处理器用两种方法执行地址转换,分别是实地址模式以及保护模式。实地址模式主要是为了让处理器与早期系统兼容,并且让操作系统启动。分段用于将逻辑地址转化成为虚拟地址。
2.1:段选择符和段寄存器
x86系统中,使用32位逻辑地址加上16位存储在段寄存器中的段选择符,获得线性地址。
系统中总共有六个段寄存器:
cs:代码段寄存器;ss:栈段寄存器;ds:数据段寄存器。其他三个寄存器可以指向任意的数据段。
段选择符有16位,高13位index用于在GDT或LDT中选择段描述符。第3位TI用于表示是在全局描述附表还是局部描述符表中选择。cs段选择符的第1~2位RPL指明了当前CPU的特权级(CPL),0表示内核态,3表示用户态。

2.2:段描述符
段描述符存储在全局描述符表(GDT)或者局部描述符表(LDT)中,描述了段的基本信息:如:段的首地址;段的长度,段的访问权限(linux中,0表示内核态,3表示用户态)
|
/* 8 byte segment descriptor */ struct desc_struct { u16 limit0; u16 base0; u16 base1: 8, type: 4, s: 1, dpl: 2, p: 1; u16 limit1: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8; } __attribute__((packed)); |
系统中只有一个GDT,每个进程特有的段存储在自己的LDT中。GDT的位置大小信息存储在寄存器gdtr中,LDT的地址大小存储在寄存器ldtr中,这个寄存器中的值随着进程切换而改变。段描述符中,字段DPL表示了段的访问特权级。当DPL=0的时候,只有当前cs段寄存器中,段选择符CPL=0的时候,才能够访问这个段。
2.3:快速访问段描述符
由于每次寻址的时候,都要获得当前的段选择符(存放在段寄存器中)所对应的段描述符。而段描述符存放在GDT或LDT,也就是内存中。如果每次都要访问一次内存的话,开销很大,所以x86提供了对应六个段寄存器的寄存器,用于存储当前段寄存器中段选择符所对应的段描述符。当段寄存器中的值不发生变化的时候,这六个寄存器中的值也不会改变。这样就可以加速段描述符的获取。这六个寄存器对我们而言是不可见的。
2.4:分段单元
已经获得逻辑地址,段描述符,就可以获得对应的线性地址。直接让段描述符中的base和逻辑地址相加就得到了线性地址。
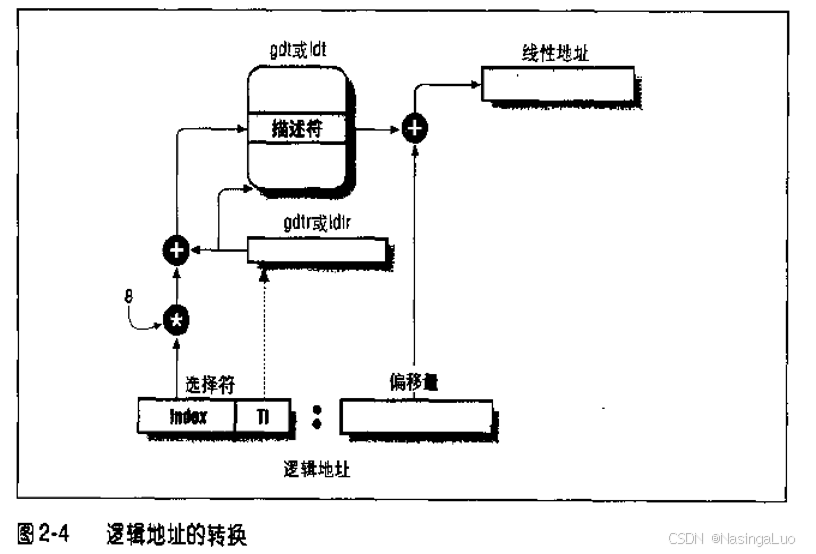
也就是说,建立一个虚拟地址的步骤如下:
1:获得逻辑地址;
2:根据段寄存器中的内容,查询GDT或者LDT的相应表项,获得对应的段描述符。
3:将段描述符的base字段加上逻辑地址就是线性地址。
3:LINUX中的分段
运行在用户态的Linux进程都使用同一个段来对指令和数据寻址(用户代码段和用户数据段),运行在内核态的Linux进程也都使用同一个段来寻址(内核代码段和内核数据段)
例如,在用户态切到内核态的时候,只需要将__KERNEL_CS放入cs段寄存器中,__KERNEL_DS放入ds段寄存器中。
并且,这些段描述符的基地址都是0,也就是说,在Linux系统中,逻辑地址和线性地址是相同的。但是,不同的段描述符的CPL是不一样的,这就保证了特权级的正常工作。
3.1:linux GDT
GDT的成员如下:
|
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = { /* * We need valid kernel segments for data and code in long mode too * IRET will check the segment types kkeil 2000/10/28 * Also sysret mandates a special GDT layout * * TLS descriptors are currently at a different place compared to i386. * Hopefully nobody expects them at a fixed place (Wine?) */ [GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff), [GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff), [GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff), } }; EXPORT_PER_CPU_SYMBOL_GPL(gdt_page); |
3.2:linux LDT
LDT和进程相关。如果进程没有自己定义LDT,那么使用默认的缺省的LDT。
4:硬件中的分页
之前的分段已经将逻辑地址转化成了线性地址。还需要借助分页,将线性地址转化成物理地址。其中,一个关键任务是将访问类型和线性地址的访问权限相比较,如果这次的访问无效,就产生一个缺页异常。
线性地址被分成固定大小的页。同时物理地址也被分为固定大小的页框。要知道页只是一个数据块,可以放在页框或者磁盘中。
这一节介绍32位或者64位时,硬件的分页规则。Linux实现的软件分页应该能够同时满足这两种要求。
4.1:常规分页
使用多级页表可以有效地减少每个进程页表需要的内存。因为如果一个进程不使用某个地址范围内的地址,那么这个进程就没有这段内存的页表。二级内存通过只为进程实际使用的那些虚拟内存请求页表来减少内存容量。
正在使用的页目录的物理地址放在控制寄存器cr3中。
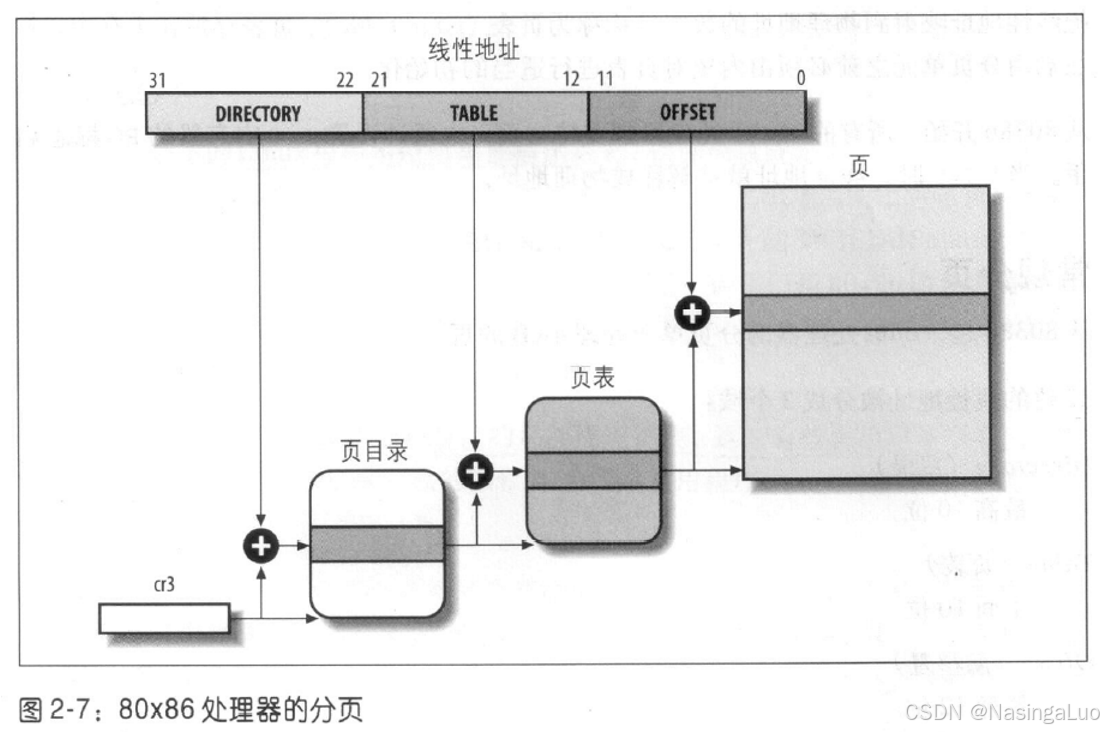
页目录项和页表项有相同的结构,都包含以下字段。
|
字段 |
含义 |
|
present |
1:对应的页在内存中; 0:对应的页不在内存中。如果执行地址转化的时候,present标志被清0,那么MMU就将这个线性地址放在寄存器cr2,并且产生14号异常:缺页异常 |
|
20位物理地址 |
指示下一级页表的物理地址的前20位 |
|
Read/Write标志 |
表示页的访问权限 |
|
User/Supervisor标志 |
表示访问页所需的特权级 |
|
Page Size |
只在一级页表项中有意义,如果被设置,那么一级目录项指向4M页框 |
4.2:扩展分页
扩展分页允许页的大小是4M,而不是4K。只需要将页目录项的Page Size置为1即可。
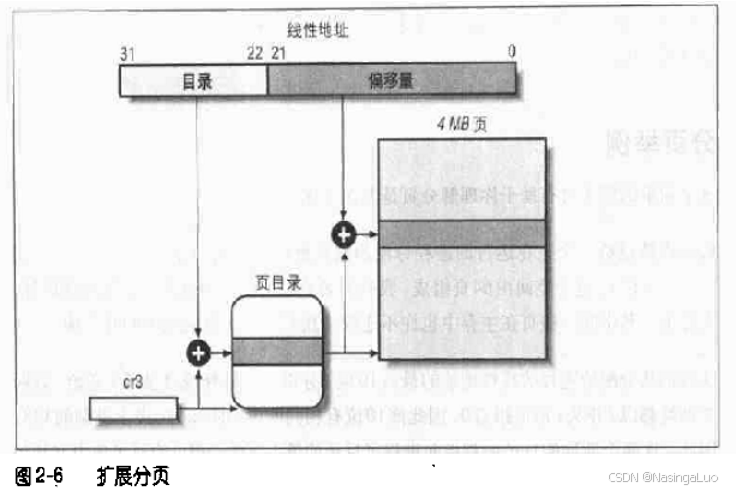
这时候只有线性地址的前10位用于寻找页目录项。剩下的22位,刚好对应4M内容。这样有利于保留TLB项。
4.3:硬件保护方案
分段和分页实现了两种保护方案。这两种保护方案是共同起作用的。在分段单元的保护中,使用的是段描述符的DPL。当DPL设置为0时,只能在CPL=0的时候(即在内核态的时候),才是可以访问的;而在DPL为3的时候,任何特权级都是可以访问的。
在分页单元的保护中,使用的是页表项中的某些位进行限制。特权由User/Supervisor标志控制。如果这个位设置为0,只有CPL等于0(特权态)时才能访问;如果这个位设置为1,那么用户态特权态都能对这个页进行访问。
页表中的Read/Write等于0,说明相应的页只读;如果等于1,说明相应的页可读可写。
4.4:常规分页举例
4.5:物理地址扩展(PAE)分页机制
在一些情况下,虚拟地址仍然为32位,但是物理地址总线超过了32位,这样就需要一种新的机制来完成寻址。例如,物理地址有36位,虚拟地址还是32位。这时候就需要用4G的虚拟地址空间对应64G的物理地址空间,也就是使用32位虚拟地址寻址36位物理地址。
inter引入物理地址扩展PAE机制。使用PAE的时候,需要将同一线性地址映射到不同的物理地址,并没有扩大进程的线性地址,仍然为4G。
这时候,设置cr4寄存器中的PAE标志激活PAE,然后设置页目录项中的Page Size标志启用大尺寸页(扩展分页中为4M,PAE中为2M)。
4.6:64位系统中的分页
4.7:硬件高速缓存cache
cache的作用是:当CPU试图从主存中load/store数据的时候,CPU会首先查找cache,看对应的地址数据是否缓存在cache中。如果数据缓存在cache中,就直接从cache中拿取。
cache的总大小叫做cache size。我们将cache平分成很多相等的块,每个块叫做cache line。cache line是cache和主存间传输数据的最小单位。也就是说,如果cache line的大小是8字节。某一次CPU查询一个char类型的量,没有在cache中,这时候会直接加载char变量附近的8字节到cache中,而不是只加载一个字节的char变量。
4.7.1:直接映射缓存(单路组相连)
cache的查询方式如下所示:
假设我们使用的cache的大小是64字节,然后每个cache line是8个字节。因此,我们有8个cache line。
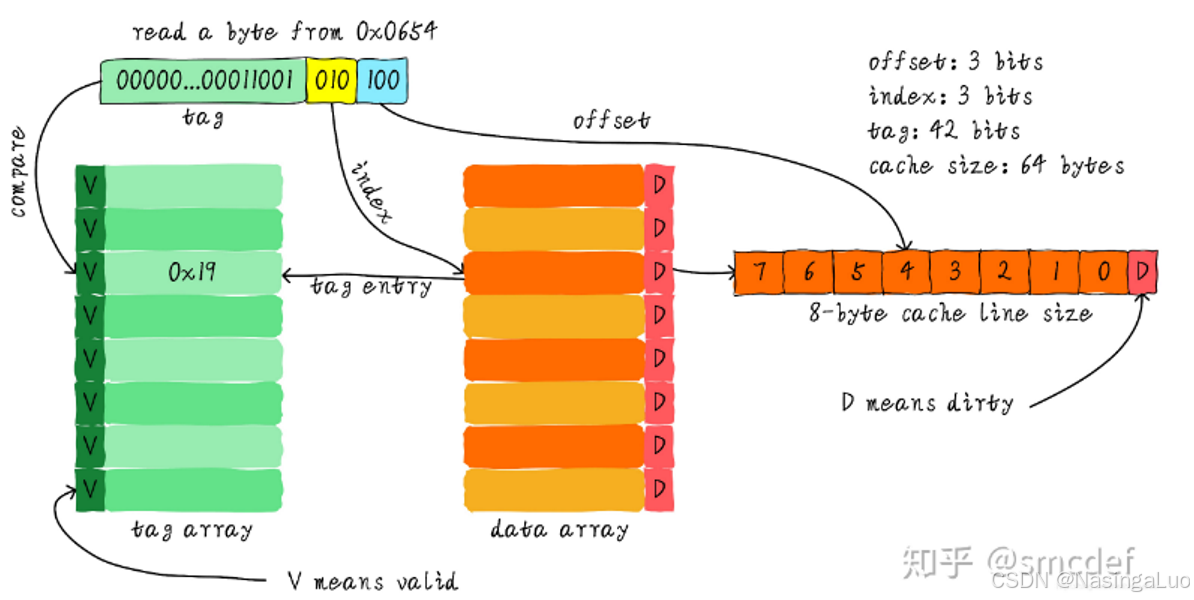
假设我们要访问0x0654地址上存储的数据。由于每个cache line是8个字节。因此,我们需要用地址的最后三位(offset,蓝色部分)来定位cache line中的数据。此外,总共有8个cache line。因此,我们还需要地址中的三位(index,黄色部分)来确定是哪一条cache line。很多地址的最后六位是相通的,仅凭六位地址显然无法进行区分,还需要剩下的位数。因此,将剩下的位数(绿色部分)放入tag中,每个tag和每个cache line对应。tag最前面的V表示这条cache line是否有效。
因此,使用地址进行查找的时候,就是这样的步骤。
1:使用地址的index位找到一个cache line。
2:对比地址的前26位是否和这个cache line对应的tag相同。如果相同,判断这条cache line是否有效。如果有效,说明查找成功;否则查找失败。
3:如果查找成功,那么就使用地址的offset在cache line中寻找,找到对应的字节。
直接映射缓存的优点就是设计简单,然后成本上也比较低。但是缺点就是,如果我们间隔的连续访问一些数据的时候,容易发生颠簸。
例如,整个cache的大小是64字节,然后我们访问一个二维数组a[100][16]。这时候就会发生一个问题,就是a[0][0],a[1][0],a[2][0]……,这些一定对应了同一个cache line。就会不停的换入换出。影响效率。
4.7.2:两路组相连缓存
路的意思,就是我们先将整个cache分成几份。比如,同样是64字节,每个cache line占据8个字节的缓存,两路组相连缓存的结构应该如下所示。
这时候引入一个新概念叫做组。索引一致,也就是下图中在同一行的cache line叫做一个组。
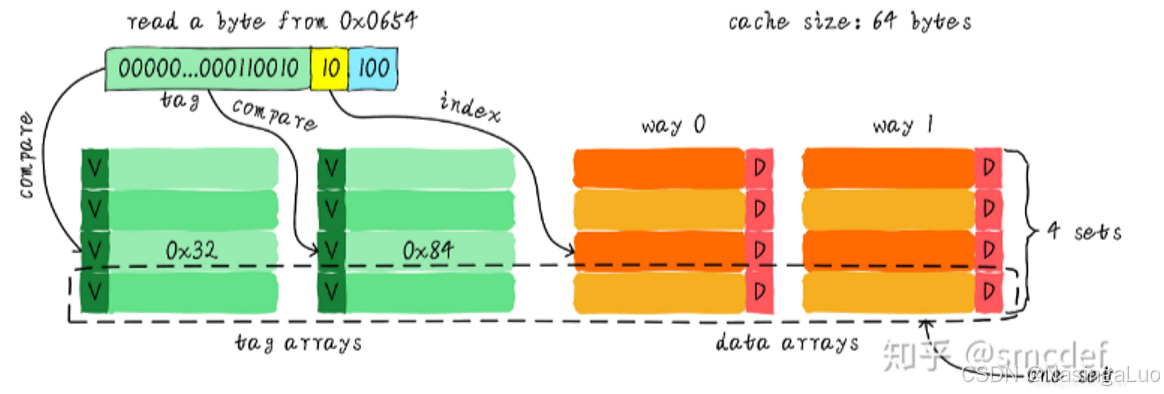
这时,加入我们还是需要查找地址为0x0654位置的数据。这时候,地址的最后三位(offset)还是用于从一个cache line的8个字节中选择一个字节。但是这时候的索引(index)只需要两位即可。因为cache line总共只有4行,也就是一路只有4个cache line。
因此,这时我们只需要两位index找到两个cache line。然后比较剩下的地址和每个cache line的tag。如果比对成功并且cache line有效,那么就说明查找成功。
既然之前讲直接映射缓存的时候,提了直接映射缓存的缺点,引入了两路组相联缓存。那么,两路组相联缓存是如何避免直接映射缓存的缺点的了?可以想象,还是之前那个数组的例子,这时候,我们访问数组的时候,a[0][0],a[1][0]会同时存储在cache中。这就避免了cache发生颠簸的概率。
当然,两路组相联也有缺点。每次需要比较两个tag,降低了速度,增加了硬件复杂度。
4.7.3:全相连缓存
全相连缓存中,没有index,这时候需要比较所有的tag。观察是否发生cache line命中。
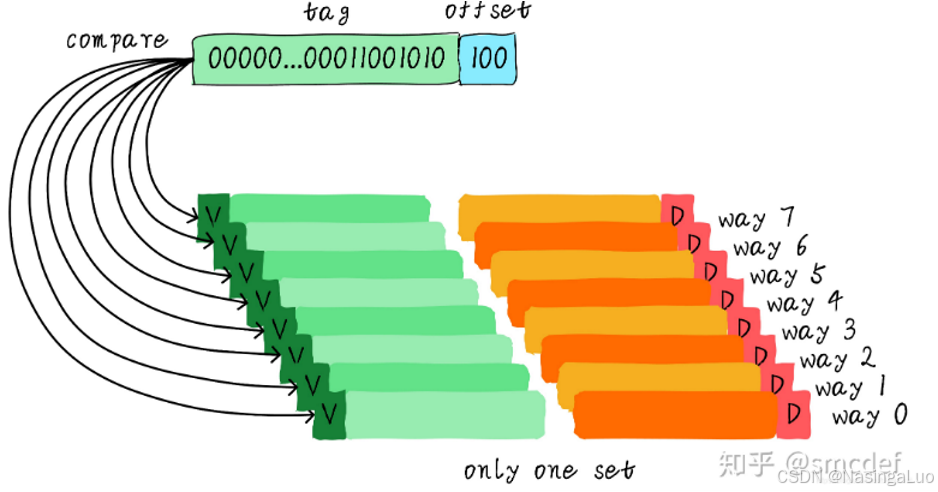
寄存器cr0中的CD位用来表示启用或者禁用高速缓存。NW位标志高速缓存是通写还是写回策略。
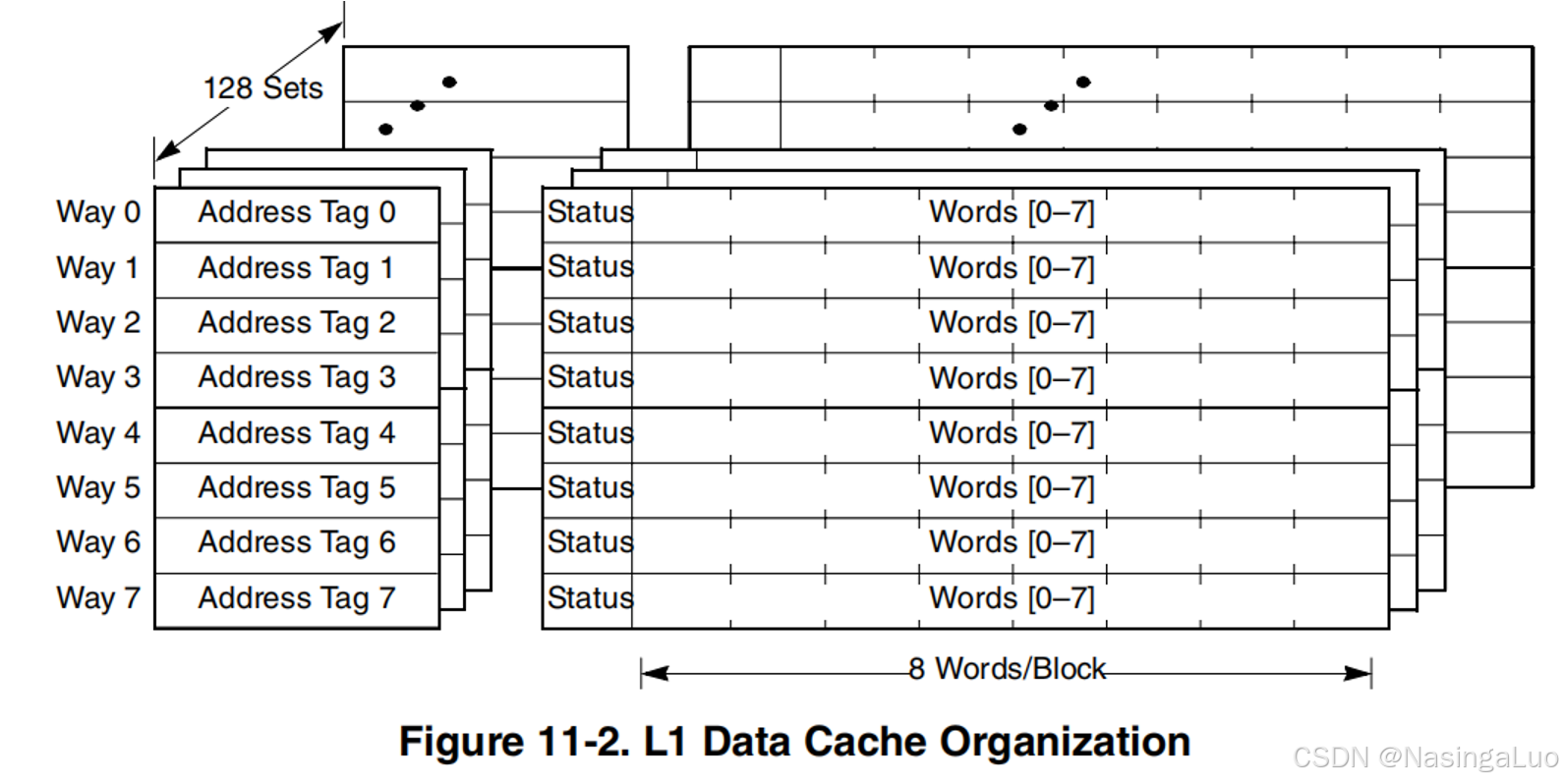
4.7.4:e500的缓存结构
e500的缓存结构如下所示,每个cache line的大小为32字节。
4.8:TLB
每个CPU都有自己的TLB。当CPU的cr3寄存器更新的时候,也就是页表发生切换的时候,会将TLB中的所有数据无效。但是,现代高性能cpu,如果你的 CPU 支持 PCID(Process Context ID) 特性,你可以使用 不同 PCID 标识来区分进程的 TLB 条目;这样在写 CR3 的时候,可以避免强制清空 TLB。
5:Linux中的分页
linux系统不仅兼容x86与arm架构,还兼容32位和64位架构。不同架构以及不同的位使用了不同的头文件描述了对应的数据结构。x86架构中,使用头文件pgtable_types.h总领页表数据结构;arm64架构中,使用头文件pgtable-types.h总领页表数据结构。其他头文件都是被这两个文件引用的。
我们在这里只描述x86_64架构中,linux的分页模式。在这种架构中,可以使用四级页表或者五级页表。要使用五级页表,不仅要求CONFIG_X86_5LEVEL,还要求cpu设置了X86_FEATURE_LA57特性。cpu设置了哪些特性可以通过/proc/cpuinfo查看
|
cat /proc/cpuinfo |
典型的四级页表格式如下:
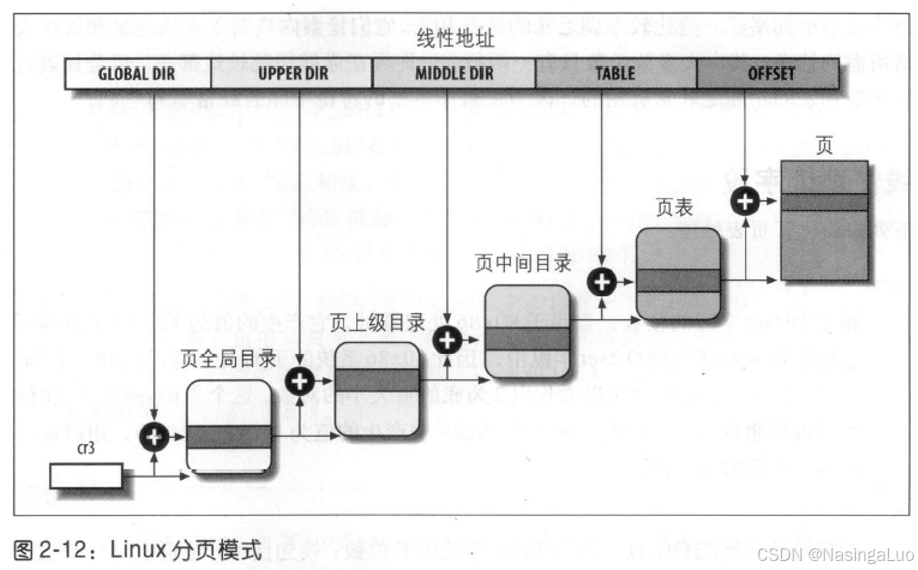
这些页表从高到低分别是pgd(p4d),pud,pmd,pte。此外,在x86_64架构中,64位虚拟地址中,只有低48位进行寻址,这48位按照9,9,9,9,12位的格式分别作为每一级页表的index。
每一个进程都有自己的页全局目录pgd和自己的页表集。当发生进程切换的时候,Linux将cr3寄存器的内容保存在进程的描述符中,然后把下一个要执行的进程的描述符中的cr3的值装入寄存器中。
5.1:线性地址字段
和内存相关的有很多宏。在这里只简要介绍其中比较常见的一些宏。
|
宏 |
含义 |
|
PAGE_SHIFT |
指定offset字段的位数。这表示了页表的粒度。一般值为12,对应一页大小为4K |
|
PMD_SHIFT |
指定offset+table的总位数。x86_64中为21 |
|
PUD_SHIFT |
指定offset+table+middle dir的总位数。x86_64中为30 |
|
PGDIR_SHIFT |
指定offset+table+middle dir+upper dir的总位数。x86_64中为39 |
|
PTRS_PER_PTE |
一个页表中包含了多少页表项。x86_64中为512 |
|
PTRS_PER_PMD |
一个页中级目录中包含了多少页中级目录项。x86_64中为512 |
|
PTRS_PER_PUD |
一个页上级目录中包含了多少页上级目录项。x86_64中为512 |
|
PTRS_PER_PGD |
一个页全局目录中包含了多少页全局目录项。x86_64中为512 |
每级页表都占用了一个4k页。并且,cr3寄存器和每级页表都是存放的下级页表的物理地址首地址。由于他们都是4k对其的,因此他们的低三位必定是0。因此,使用每级页表的低三位(换成二进制就是低12位)做特殊含义处理。
5.2:页表处理
我们举一个从一级页表找到最终的物理地址的例子。例如,我们想找到地址0xffffffff8ea10000对应的物理地址。在crash中翻译这个地址的过程如下:
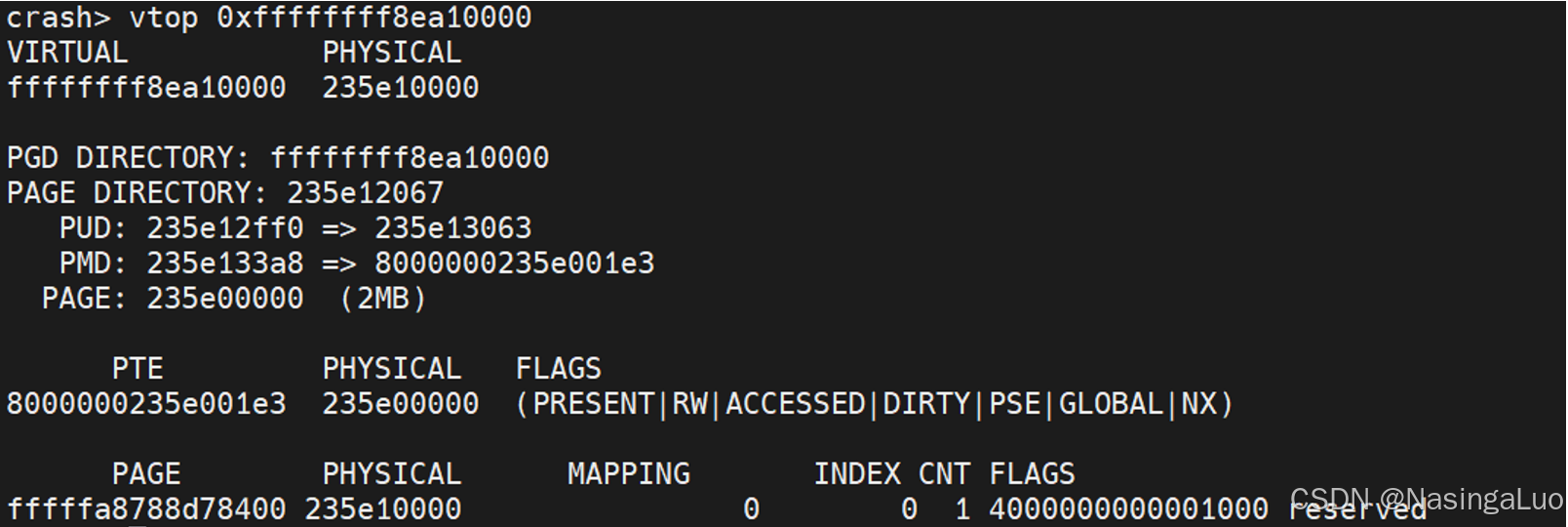
首先,我们找到一级页表的地址。内核页表pgd就是init_top_pgt。而每个用户态进程的页表pgd首地址可以通过cr3查看。一级页表地址如下:

地址0xffffffff8ea10000对应的一级页表项地址为:
|
pgd + pgd_index(0xffffffff8ea10000) = 0xffffffff8ea10000 + (0xffffffff8ea10000 >> 39 & 511) * sizeof(pgd_t) //这里是指针加,因此需要乘sizeof(pgd_t) = 0xffffffff8ea10000 + 0xFF8 = 0xffffffff8ea10ff8 |
因此,可以得到pgd内容为
![]()
可见和图1中pgd的值相同。
地址0x0000000235e12067对应的是二级页表的物理地址,并且还带有标志位。要将他翻译成虚拟地址,如下:
|
0x0000000235e12000 + page_offset_base = 0xffff952035e12000 //这就是pud的首地址 |
地址0xffffffff8ea10000对应的二级页表项地址为:
|
pud + pud_index(0xffffffff8ea10000) = 0xffff952035e12000 + (0xffffffff8ea10000 >> 30 & 511) * sizeof(pud_t) //同上 = 0xffff952035e12000 + 0xFF0 = 0xffff952035e12ff0 |
因此,可以得到pud的内容为

地址0xffffffff8ea10000对应的三级页表项地址为:
|
pmd + pmd_index(0xffffffff8ea10000) = 0x0000000235e13000 + page_offset_base + (0xffffffff8ea10000 >> 21 & 511) * 8 = 0xFFFF952035E13000 + 0x3A8 = 0xFFFF952035E133A8 |
因此,可以得到pmd的内容为

由于pmd的值为0x8000000235e001e3,因此他设置了
|
#define _PAGE_PSE (_AT(pteval_t, 1) << _PAGE_BIT_PSE) //也就是1<<7比特位。表示这是一个2M巨页。此外,8000000235e001e3表示他还设置了PRESENT|RW|ACCESSED|DIRTY|PSE|GLOBAL|NX位(见pgtable_64_types.h) |
所以,虚拟地址0xffffffff8ea10000对应的物理地址就是0x235e10000
5.3:物理内存布局
在初始化阶段,系统需要知道哪些物理地址空间是可用的。内核通过BIOS知道物理内存的布局。然后,内核将部分页框标记为保留页框,这些页框包括:
1:在不可用物理地址范围内的页框。(这些页框映射硬件设备IO的共享内存,或者相应的页框中含有BIOS数据)
2:含有内核代码和已经初始化数据结构的页框。
保留页框中的页不能够被动态分配,或者交换到磁盘上。剩下的页框就是能够动态分配的页框,也就是能够进入伙伴系统中的页框。
一般情况下,Linux一般安装在从内存中第2M开始。这可以从/proc/iomem中看到
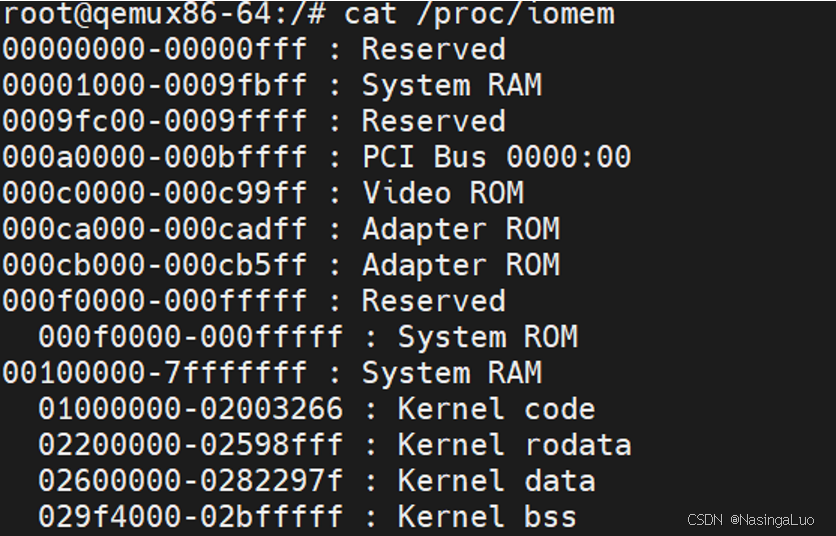
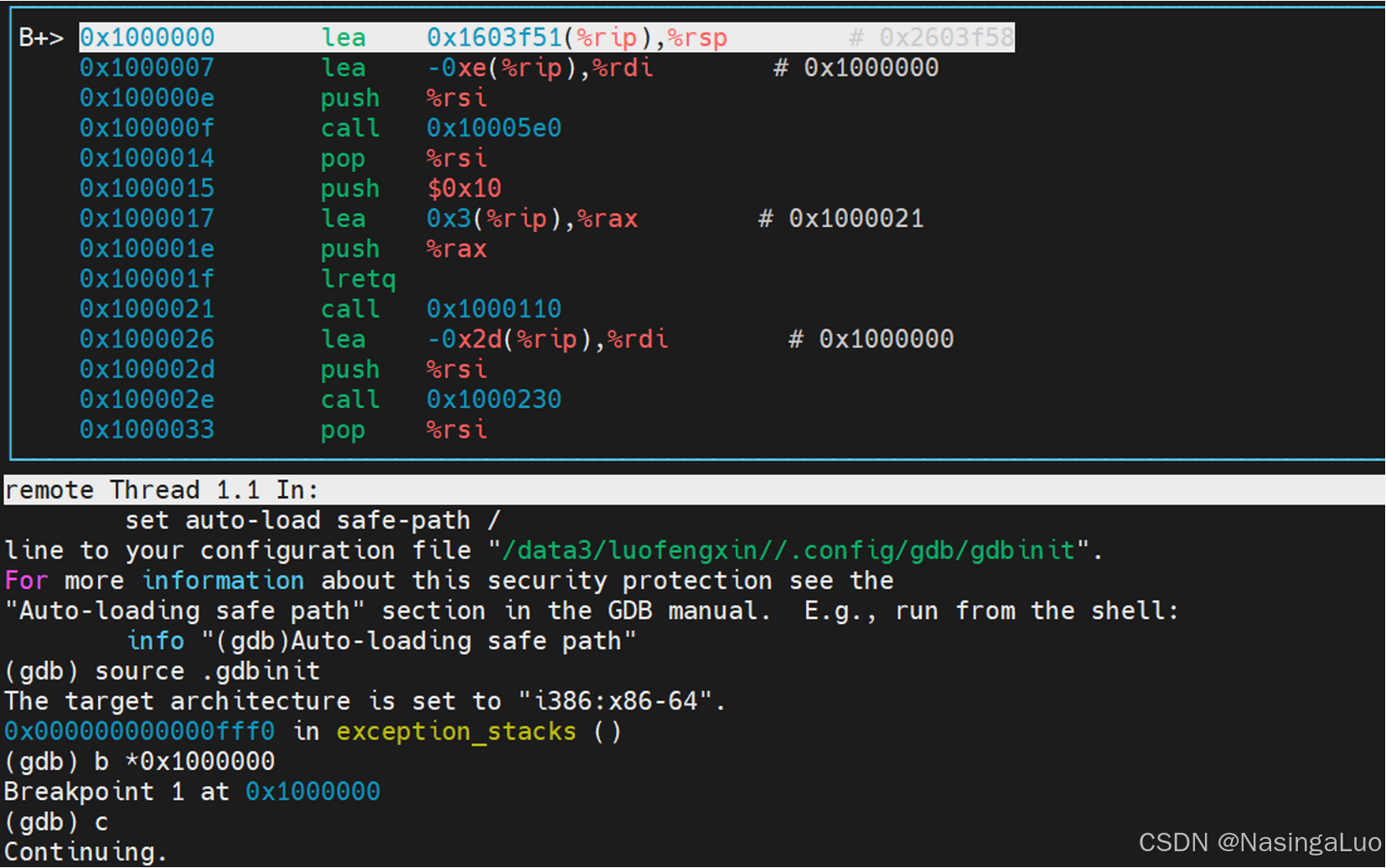
因此,使用gdb调试qemu的时候,断点打到0x01000000就能断到linux的第一句(因为这时候使用的是实模式,在使用保护模式之后,这个地址对应的虚拟地址是0xffffffff81000000)
Linux系统中,物理地址空间的布局如下图所示:
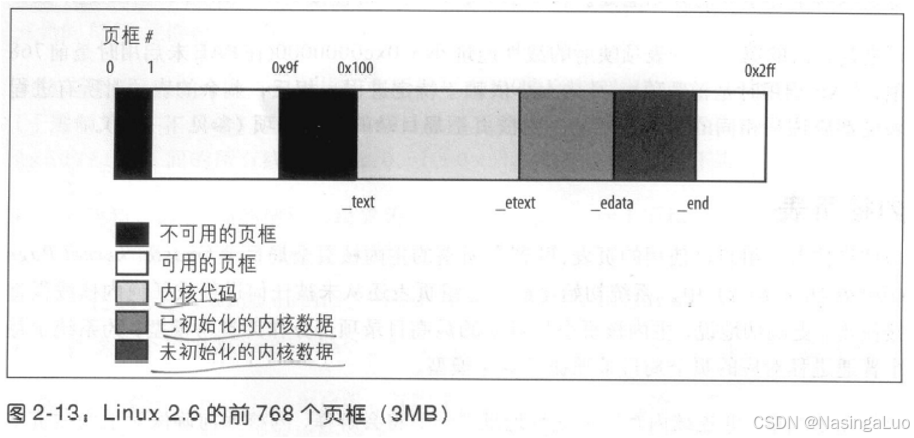
其中,0x9f到0x100页框,也就是640k~1M物理内存,是留给BIOS的著名的洞。白色的页框,就是能够进入伙伴系统的页框。
5.4:进程页表
进程以及内核的线性地址空间按照下面的方式组织(x86_64架构,并且使用4级页表的情况下):
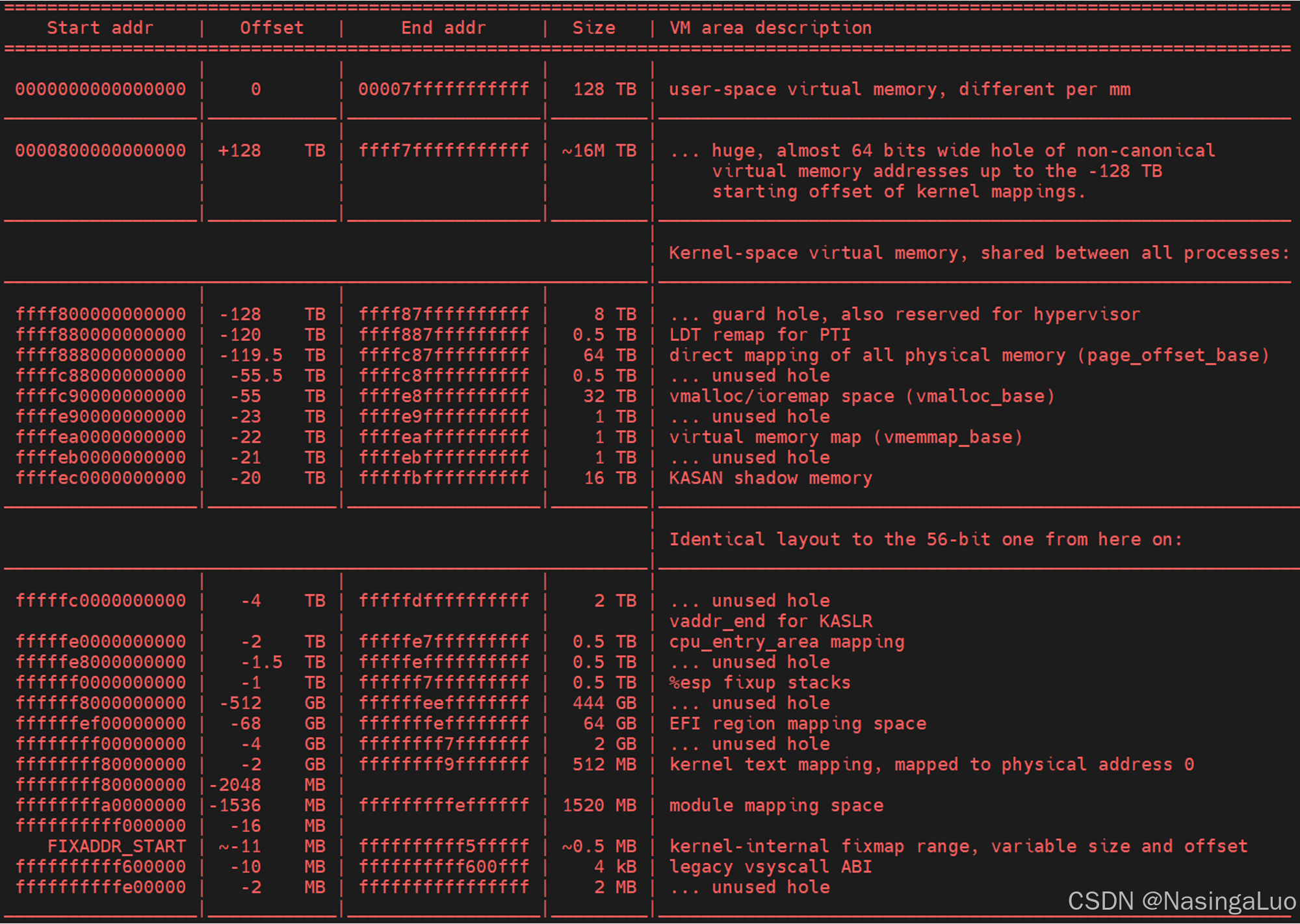
5.5:内核页表
内核维护着一组自己使用的页表。这就是主内核页全局目录。内核初始化自己的页表包含两个阶段:
1:内核在系统启动初期(进入start_kernel)之前,创建一个临时页表。对于x86_64架构和arm64架构,这个临时页表都包含了两块映射,分别是1比1的映射(用于实模式下的地址翻译),以及内核的虚拟地址(vmlinux.lds.S中定义)到物理地址之间的映射。在x86_64中,临时页表是early_top_pgt;arm64架构中,临时页表是init_pg_dir。
2:建立内核真正使用的页表。在x86_64和arm64中,这个页表都是swapper_pg_dir
5.5.1:x86_64——临时内核页表
当linux被uboot起来的时候,这时候使用的是uboot设置的页表。不过,我们会在一开始的时候,在函数__startup_64中初始化好linux的第一张页表,也是一张临时内核页表——early_top_pgt。
这张页表的建立过程在快速笔记——x86_64的启动过程中有详细描述。这里只说明这个页表的建立结果,如下所示:
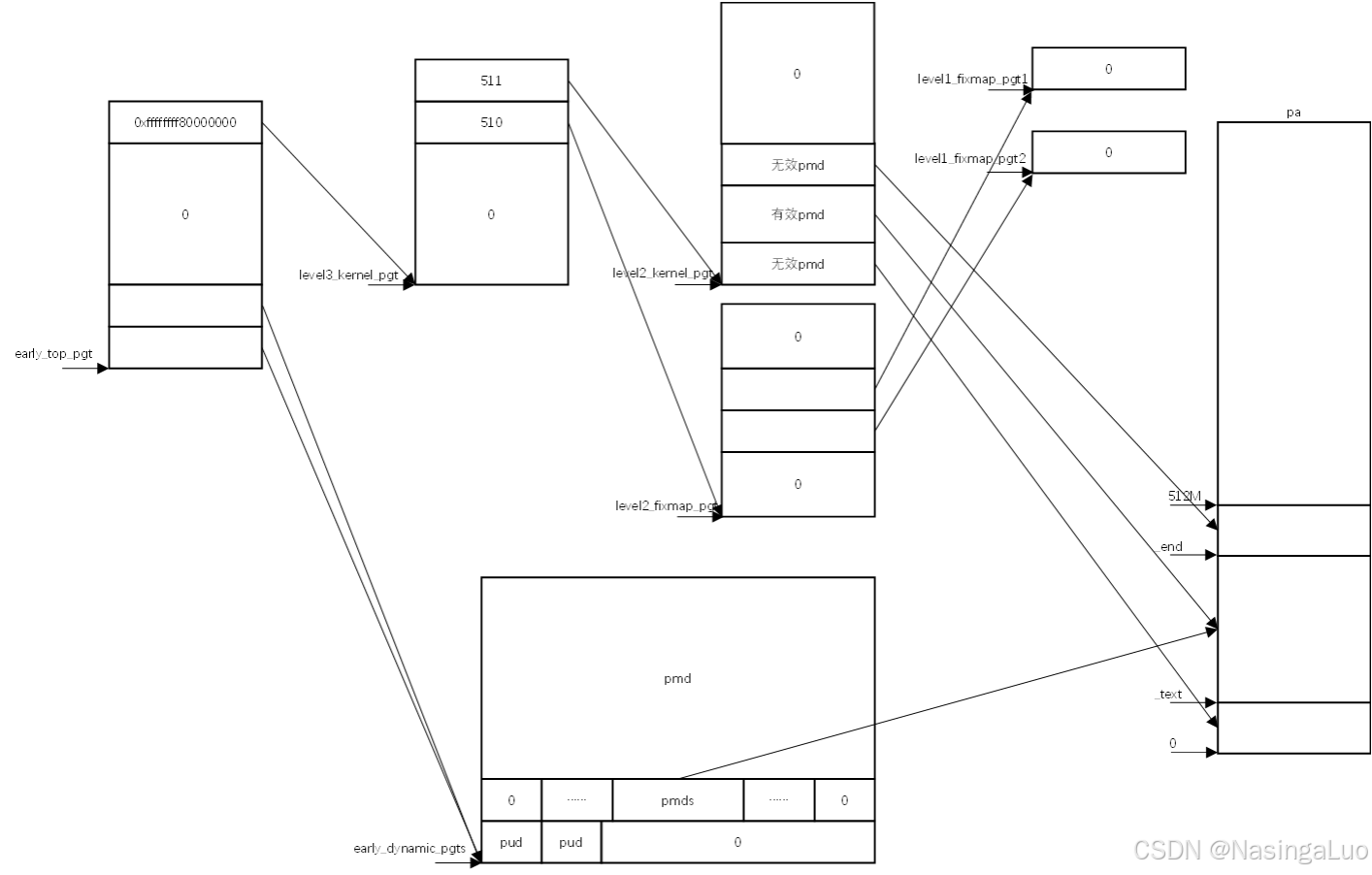
总之,临时内核页表中,建立了从0xffffffff80000000开始的虚拟地址,到0~512M物理地址之间的映射。以及0~512M虚拟地址,到0~512M物理地址之间的映射。
5.5.2:x86_64——内核页表
上面介绍的临时内核页表只在系统起来的很短一段时间内使用。他只映射了存放从_text~_end这段物理地址空间的映射,只包括了少于0~512M的部分。因此,为了系统的正常运行,我们还需要建立系统中所有可用地址空间的直接映射。这之后,我们不再使用early_top_pgt,而是使用内核页表——init_top_pgt,也就是我们常说的swapper_dir
init_top_pgt的初始化分成两个部分,第一部分是复制early_top_pgt中,从0xffffffff80000000开始的虚拟地址,到0~512M物理地址之间的映射。
|
asmlinkage __visible void __init x86_64_start_kernel(char * real_mode_data) { …… clear_page(init_top_pgt); …… /* set init_top_pgt kernel high mapping*/ init_top_pgt[511] = early_top_pgt[511];//复制early_top_pgt中最后一项 x86_64_start_reservations(real_mode_data); } |
这里的复制是为了,当我们切换成init_top_pgt的时候,依然能够执行代码。因为内核代码的虚拟地址就是从0xffffffff80000000开始的(vmlinux.lds.S决定)。
第二部分是建立系统中所有可用内存的直接映射。这是通过函数init_mem_mapping实现的。在执行这个操作之前,我们已经初始化好了memblock数据结构。
|
void __init init_mem_mapping(void) { unsigned long end; pti_check_boottime_disable(); probe_page_size_mask(); setup_pcid();
end = max_pfn << PAGE_SHIFT; /* the ISA range is always mapped regardless of memory holes */ init_memory_mapping(0, ISA_END_ADDRESS, PAGE_KERNEL); //我们总是将0~0x100000(ISA_END_ADDRESS)先做映射 /* Init the trampoline, possibly with KASLR memory offset */ init_trampoline(); /* * If the allocation is in bottom-up direction, we setup direct mapping * in bottom-up, otherwise we setup direct mapping in top-down. */ if (memblock_bottom_up()) { …… } else { memory_map_top_down(ISA_END_ADDRESS, end);//映射从0x100000~max_pfn决定的所有物理地址 }
if (max_pfn > max_low_pfn) { /* can we preseve max_low_pfn ?*/ max_low_pfn = max_pfn; } load_cr3(swapper_pg_dir); //切换页表。swapper_pg_dir就是init_top_pgt __flush_tlb_all(); x86_init.hyper.init_mem_mapping(); early_memtest(0, max_pfn_mapped << PAGE_SHIFT); } |
|
/** * memory_map_top_down - Map [map_start, map_end) top down * @map_start: start address of the target memory range * @map_end: end address of the target memory range * * This function will setup direct mapping for memory range * [map_start, map_end) in top-down. That said, the page tables * will be allocated at the end of the memory, and we map the * memory in top-down. */ static void __init memory_map_top_down(unsigned long map_start, unsigned long map_end) { unsigned long real_end, start, last_start; unsigned long step_size; unsigned long addr; unsigned long mapped_ram_size = 0; /* xen has big range in reserved near end of ram, skip it at first.*/ addr = memblock_find_in_range(map_start, map_end, PMD_SIZE, PMD_SIZE); //我们在memblock中,找到在map_start~map_end之间的最后一个内存块。要求找到的内存块在memblock.memory中,而不在memblock.reserve中 real_end = addr + PMD_SIZE; //real_end就是要做映射的最大物理地址 /* step_size need to be small so pgt_buf from BRK could cover it */ step_size = PMD_SIZE; max_pfn_mapped = 0; /* will get exact value next */ min_pfn_mapped = real_end >> PAGE_SHIFT; last_start = start = real_end; /* * We start from the top (end of memory) and go to the bottom. * The memblock_find_in_range() gets us a block of RAM from the * end of RAM in [min_pfn_mapped, max_pfn_mapped) used as new pages * for page table. */ while (last_start > map_start) { if (last_start > step_size) { start = round_down(last_start - 1, step_size); if (start < map_start) start = map_start; } else start = map_start; mapped_ram_size += init_range_memory_mapping(start, //通过这个while循环,映射从map_start~real_end之间的物理地址空间。对应的虚拟地址空间就是物理地址 + PAGE_OFFSET last_start); last_start = start; min_pfn_mapped = last_start >> PAGE_SHIFT; if (mapped_ram_size >= step_size) step_size = get_new_step_size(step_size); } if (real_end < map_end) init_range_memory_mapping(real_end, map_end); } |
举一个例子说明上面建立的直接内存映射。我们的qemu中,设置内存总大小为2048M。那么,在函数memory_map_top_down中对应的map_end就是0x80000000
我们的memblock在初始化完成后,可用的memblock如下:

因此,上面就是建立了0x0000000000100000-0x000000007fffffff物理地址的直接内存映射。也就是说,内核页表中,不止有0xffffffff80000000~0xffffffffffffffff到物理地址0~512M的映射,还有0~A虚拟地址到0~A物理地址的一比一映射。
5.5.3:arm64——临时内核页表
arm64架构的临时内核页表我们同样在快速笔记——arm64的启动过程中详细描述。在start_kernel之前,使用汇编语言建立了两段映射。这时候使用的页表是init_pg_dir。
5.5.4:arm64——内核页表
在系统起来后,在start_kernel -> setup_arch中,会建立真正的内核页表。这时候使用的内核页表是swapper_pg_dir。我们在函数paging_init中对这个页表进行初始化。
|
void __init paging_init(void) { pgd_t *pgdp = pgd_set_fixmap(__pa_symbol(swapper_pg_dir)); map_kernel(pgdp); map_mem(pgdp); pgd_clear_fixmap(); cpu_replace_ttbr1(lm_alias(swapper_pg_dir)); init_mm.pgd = swapper_pg_dir; memblock_free(__pa_symbol(init_pg_dir), __pa_symbol(init_pg_end) - __pa_symbol(init_pg_dir)); memblock_allow_resize(); } |
5.6:固定映射的线性地址
固定映射的线性地址,不是指线性地址映射的物理地址是固定的,而是说,基于某种目的使用的线性地址的值是固定的。固定映射的线性地址和物理地址的关系,不是差值TASK_SIZE的关系,也不是一比一的关系。
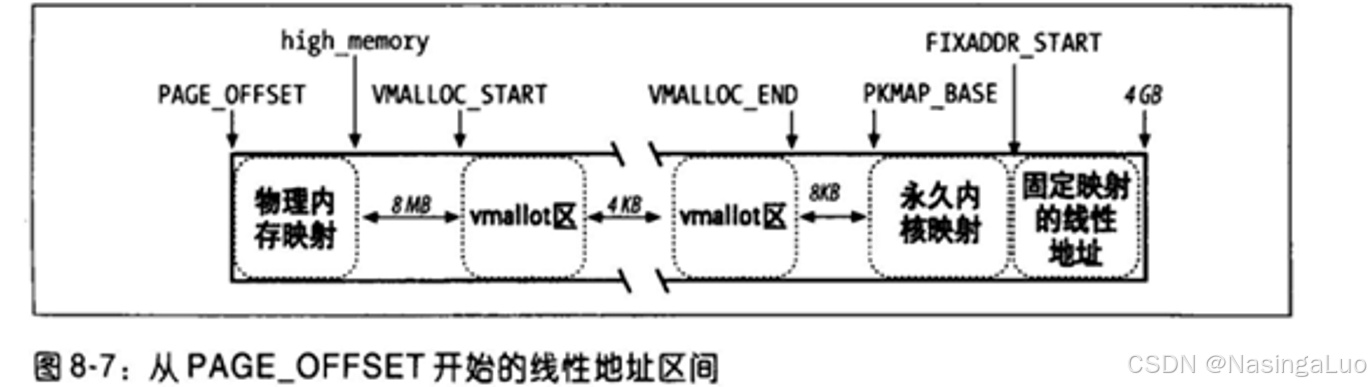
之前对内核虚拟地址空间建立的映射,线性地址和物理线性地址的关系总是:
线性地址-PAGE_OFFSET=物理地址。
而固定映射的线性地址没有这样的关系。固定映射的线性地址数量有限,都在这一枚举变量中列出。每个枚举变量都表示了4K大小的,用于固定映射的线性地址的序号。
在这里解释什么叫做固定映射的线性地址。首先,固定映射的线性地址只适用于i386等少数架构,并非所有架构通用。这些线性地址主要映射了一些特殊用途的物理地址,如硬件设备的寄存器等。这些映射在整个内核的运行过程中都是固定不变的,因此叫做固定映射的线性地址。
|
/* * Here we define all the compile-time 'special' virtual * addresses. The point is to have a constant address at * compile time, but to set the physical address only * in the boot process. * for x86_32: We allocate these special addresses * from the end of virtual memory (0xfffff000) backwards. * Also this lets us do fail-safe vmalloc(), we * can guarantee that these special addresses and * vmalloc()-ed addresses never overlap. * * These 'compile-time allocated' memory buffers are * fixed-size 4k pages (or larger if used with an increment * higher than 1). Use set_fixmap(idx,phys) to associate * physical memory with fixmap indices. * * TLB entries of such buffers will not be flushed across * task switches. */ //注释可知,这些虚拟地址在编译的时候就固定了 enum fixed_addresses { …… __end_of_fixed_addresses }; |
如果需要使用到一个固定映射的线性地址,那么首先使用下面的宏,将对应的固定映射的线性地址的序号转换成真正的线性地址。
|
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT)) //fixmap使用的虚拟地址范围可以参考linux/Documentation/x86/x86_64/mm.rst |
使用下面的宏,建立固定映射的详细地址的页表项。
|
static inline void __set_fixmap(enum fixed_addresses idx, phys_addr_t phys, pgprot_t flags) { native_set_fixmap(idx, phys, flags); } //phys表示这个固定映射的线性地址要映射到哪个物理地址上去。这个物理地址一般是预先确定的。例如,某些外设的物理地址是固定的(主板决定) //这个宏的使用方式如下: set_fixmap(FIX_APIC_BASE, APIC_DEFAULT_PHYS_BASE) |
|
void native_set_fixmap(unsigned /* enum fixed_addresses */ idx, phys_addr_t phys, pgprot_t flags) { /* Sanitize 'prot' against any unsupported bits: *///过滤flags中设置的不支持的位 pgprot_val(flags) &= __default_kernel_pte_mask; __native_set_fixmap(idx, pfn_pte(phys >> PAGE_SHIFT, flags)); } |
|
void __native_set_fixmap(enum fixed_addresses idx, pte_t pte) { unsigned long address = __fix_to_virt(idx); //获得这个idx对应的线性地址 #ifdef CONFIG_X86_64 /* * Ensure that the static initial page tables are covering the * fixmap completely. */ BUILD_BUG_ON(__end_of_permanent_fixed_addresses > (FIXMAP_PMD_NUM * PTRS_PER_PTE)); #endif if (idx >= __end_of_fixed_addresses) { BUG(); return; } set_pte_vaddr(address, pte); //设置页表项,页表项的格式为phy_addr(20位)|prot(12位) fixmaps_set++; } |
5.7:处理硬件高速缓存和TLB
5.7.1:处理硬件高速缓存
为了保证高速缓存的命中率达到最高,应该满足以下要求:
一个数据结构中,经常使用的字段放在该数据结构的低偏移部分,尽可能使他们在高速缓存的同一行中。
6:内存初始化
我们在这一节讨论,系统是如何确定系统中物理内存的情况,以及如何进入我们熟悉的伙伴系统的。
6.1:arm64——从设备树到memblock
以arm64架构为例,在系统启动的时候,需要用到设备树。设备树的作用就是描述系统管理的硬件设备。其中,描述内存的设备树字段如下。因此,物理地址空间并不是从0开始的,而是从0x40000000开始的。
|
memory@40000000 { reg = <0x00 0x40000000 0x00 0x80000000>; //物理内存的起始地址是0x0040000000~0x0080000000 device_type = "memory"; }; |
在start_kernel中,会扫描设备树中的各个节点。其中,扫描内存设备节点的调用路径如下所示:

|
//通过此函数,扫描并解析设备树中的内存节点 int __init early_init_dt_scan_memory(unsigned long node, const char *uname, int depth, void *data) { const char *type = of_get_flat_dt_prop(node, "device_type", NULL); const __be32 *reg, *endp; int l; bool hotpluggable; /* We are scanning "memory" nodes only *///扫描设备类型为memory的节点 if (type == NULL || strcmp(type, "memory") != 0) return 0; reg = of_get_flat_dt_prop(node, "linux,usable-memory", &l); if (reg == NULL) reg = of_get_flat_dt_prop(node, "reg", &l); if (reg == NULL) return 0; endp = reg + (l / sizeof(__be32)); hotpluggable = of_get_flat_dt_prop(node, "hotpluggable", NULL); pr_debug("memory scan node %s, reg size %d,\n", uname, l); while ((endp - reg) >= (dt_root_addr_cells + dt_root_size_cells)) { u64 base, size; base = dt_mem_next_cell(dt_root_addr_cells, ®); size = dt_mem_next_cell(dt_root_size_cells, ®); //获取设备树中,定义的内存结点的base和size if (size == 0) continue; pr_debug(" - %llx , %llx\n", (unsigned long long)base, (unsigned long long)size); early_init_dt_add_memory_arch(base, size); //将内存添加到memblock数据结构中 if (!hotpluggable) continue; if (early_init_dt_mark_hotplug_memory_arch(base, size)) pr_warn("failed to mark hotplug range 0x%llx - 0x%llx\n", base, base + size); } return 0; } |
|
void __init __weak early_init_dt_add_memory_arch(u64 base, u64 size) { …… //错误信息。如果发生错误的话,会打印错误原因 memblock_add(base, size); } |
|
/** * memblock_add - add new memblock region * @base: base address of the new region * @size: size of the new region * * Add new memblock region [@base, @base + @size) to the "memory" * type. See memblock_add_range() description for mode details * * Return: * 0 on success, -errno on failure. */ int __init_memblock memblock_add(phys_addr_t base, phys_addr_t size) { phys_addr_t end = base + size - 1; memblock_dbg("%s: [%pa-%pa] %pS\n", __func__, &base, &end, (void *)_RET_IP_); //memblock中有reserved和memory两种struct memblock_type。它们分别对应了保留的内存,以及可以使用的内存 return memblock_add_range(&memblock.memory, base, size, MAX_NUMNODES, 0); } |
作为一个全局变量,memblock描述了系统中所有内存的情况。数据结构如下:
|
/** * struct memblock - memblock allocator metadata * @bottom_up: is bottom up direction? * @current_limit: physical address of the current allocation limit * @memory: usable memory regions * @reserved: reserved memory regions */ struct memblock { bool bottom_up; /* is bottom up direction? */ phys_addr_t current_limit; struct memblock_type memory; struct memblock_type reserved; }; |
|
/** * struct memblock_type - collection of memory regions of certain type * @cnt: number of regions * @max: size of the allocated array * @total_size: size of all regions * @regions: array of regions * @name: the memory type symbolic name */ struct memblock_type { unsigned long cnt; //包含的regions个数 unsigned long max; phys_addr_t total_size; struct memblock_region *regions; //通过数组,描述了这种类型的memblock_type包含了多少个内存区域 char *name; }; |
总之,我们看一下函数memblock_add_range如何将一块内存添加到memblock中。
|
/** * memblock_add_range - add new memblock region * @type: memblock type to add new region into * @base: base address of the new region * @size: size of the new region * @nid: nid of the new region * @flags: flags of the new region * * Add new memblock region [@base, @base + @size) into @type. The new region * is allowed to overlap with existing ones - overlaps don't affect already * existing regions. @type is guaranteed to be minimal (all neighbouring * compatible regions are merged) after the addition. * * Return: * 0 on success, -errno on failure. */ static int __init_memblock memblock_add_range(struct memblock_type *type, phys_addr_t base, phys_addr_t size, int nid, enum memblock_flags flags) { bool insert = false; phys_addr_t obase = base; phys_addr_t end = base + memblock_cap_size(base, &size); int idx, nr_new; struct memblock_region *rgn; if (!size) return 0; /* special case for empty array */ if (type->regions[0].size == 0) { WARN_ON(type->cnt != 1 || type->total_size); type->regions[0].base = base; type->regions[0].size = size; type->regions[0].flags = flags; memblock_set_region_node(&type->regions[0], nid); type->total_size = size; return 0; } …… //我们的设备树中只有一个memory节点。不会走到后面的内容。后面主要实现了memblock中,内存块的合并,插入等操作。主要应用于reserved内存 } |
事实上,系统中的内存可能用于存放内核镜像,存放设备树等目的。这些memblock是需要保留的内存块,会添加在memblock的reserved中。总之,当我们在memblock完成初始化之后,系统会通过memblock_dump_all获得现在的memblock的分布情况
此外,我们也可以通过/sys/kernel/debug/memblock/memory与/sys/kernel/debug/memblock/reserved,观察不同的memblock分布。
|
root@qemuarm64:/sys/kernel/debug/memblock# cat memory 0: 0x0000000040000000..0x00000000bfffffff root@qemuarm64:/sys/kernel/debug/memblock# cat reserved 0: 0x0000000040210000..0x0000000041b55fff 1: 0x0000000041b58000..0x0000000041b5ffff 2: 0x0000000048000000..0x00000000480fffff 3: 0x00000000bd600000..0x00000000bf9fffff 4: 0x00000000bfa0ebc0..0x00000000bfb0efc7 5: 0x00000000bfb0f000..0x00000000bfbdefff 6: 0x00000000bfbe1300..0x00000000bfbe188f 7: 0x00000000bfbe18c0..0x00000000bfbe191f 8: 0x00000000bfbe1940..0x00000000bfbe1ac7 9: 0x00000000bfbe1b00..0x00000000bfbe1d0f 10: 0x00000000bfbe1d40..0x00000000bfbe1e5f 11: 0x00000000bfbe1e80..0x00000000bfbe1edf 12: 0x00000000bfbe1f00..0x00000000bfbe1f07 13: 0x00000000bfbe1f40..0x00000000bfbe1f47 14: 0x00000000bfbe1f80..0x00000000bfbe1fee 15: 0x00000000bfbe2000..0x00000000bfbe306e 16: 0x00000000bfbe3080..0x00000000bfbffffb 17: 0x00000000bfc00000..0x00000000bfffffff |
6.2:x86_64——从BIOS到memblock
不同于arm64架构中使用的设备树,x86_64架构中,使用的是BIOS传递给Linux的物理内存分布情况。通过调用链

初始化e820_table数据结构。初始化后的内容会打印在dmesg中:
|
[ 0.000000] BIOS-provided physical RAM map: [ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable [ 0.000000] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved [ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000bffdcfff] usable [ 0.000000] BIOS-e820: [mem 0x00000000bffdd000-0x00000000bfffffff] reserved [ 0.000000] BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved [ 0.000000] BIOS-e820: [mem 0x0000000100000000-0x000000043fffffff] usable |
也就是说,这就是BIOS认为的物理地址空间。之后,在函数e820__memblock_setup中, 会初始化好系统的memblock信息
|
void __init e820__memblock_setup(void) { int i; u64 end; /* * The bootstrap memblock region count maximum is 128 entries * (INIT_MEMBLOCK_REGIONS), but EFI might pass us more E820 entries * than that - so allow memblock resizing. * * This is safe, because this call happens pretty late during x86 setup, * so we know about reserved memory regions already. (This is important * so that memblock resizing does no stomp over reserved areas.) */ memblock_allow_resize(); for (i = 0; i < e820_table->nr_entries; i++) { struct e820_entry *entry = &e820_table->entries[i]; end = entry->addr + entry->size; if (end != (resource_size_t)end) continue; if (entry->type == E820_TYPE_SOFT_RESERVED) memblock_reserve(entry->addr, entry->size); if (entry->type != E820_TYPE_RAM && entry->type != E820_TYPE_RESERVED_KERN) continue; memblock_add(entry->addr, entry->size); } //将e820_table中的信息添加到memblock全局变量中 /* Throw away partial pages: */ memblock_trim_memory(PAGE_SIZE); memblock_dump_all(); } |
在进入此函数的时候,e820_table中的内容如下所示。可见,他和BIOS传递的信息基本一致,只有两处修改:
|
(gdb) p/x *e820_table $6 = {nr_entries = 0x7, entries = { {addr = 0x0, size = 0x1000,type = 0x2}, //修改1:我们会将第一个页框设置为保留的页框 {addr = 0x1000, size = 0x9ec00, type = 0x1}, {addr= 0x9fc00, size = 0x400, type = 0x2}, {addr = 0xf0000, size = 0x10000,type = 0x2}, {addr = 0x10000, size = 0x7ff00000, typbe = 0x1}, //修改2:qemu传入的参数中,指定了内存总大小为2G {addr = 0xbffdd000, size = 0x23000, type =0x2}, {addr = 0xfffc0000, size = 0x40000, type = 0x2}, {addr = 0x0, size = 0x0,type = 0x0} <repeats 124 times>}} |
在进入此函数的时候,memblock中的内容如下所示。
|
(gdb) p/x memblock.reserved $1 = {cnt = 0x3, max = 0x80, total_size = 0x1c7a000, regions = 0xfffffff82927b20, name = 0xffffffff8242f0d1} (gdb) p/x *(struct memblock_region_*)0xfffffff82927b20 $2 = {base = 0x0, size = 0x10000, flags = 0x0} //这里保留了0~64K物理地址空间,这部操作在setup_arch函数806行实现。这段物理内存不可用 (gdb) p/x *(struct memblock_region *)Oxffffffff82927b38 $3 = {base = 0x9f000, size = 0x61000, flags = 0x0} //这里保留了636K~1M物理地址空间,这部操作在reserve_bios_regions函数实现,该函数用于保留与传统PC系统BIOS相关的固件内存区域,防止内核将这些区域错误地用作可用RAM (gdb) p/x *(struct memblock_region *)0xffffffff82927b50 $4 = {base = 0x100000, size = 0x1c09000, flags=0x0} //这里保留了0~64K物理地址空间,这部操作在setup_arch函数799行实现。这部分物理地址空间用于存放内核镜像 |
|
(gdb) p/x memblock.memory $7 = {cnt = 0x1, max = 0x80, total_size = 0x0, regions= 0xffffffff82928720, name = 0xfffffff8245b914} (gdb) p/x *(struct memblock_region_*)0xfffffff82928720 $8 = {base = 0x0, size = 0x0, flags = 0x0} |
因此,我们最终开始使用memblock的时候,系统认为memblock的信息如下所示:
|
[ 0.038823] MEMBLOCK configuration: [ 0.038843] memory size = 0x000000007ff9ec00 reserved size = 0x0000000001c7a000 [ 0.038888] memory.cnt = 0x2 [ 0.038956] memory[0x0] [0x0000000000001000-0x000000000009efff], 0x000000000009e000 bytes flags: 0x0 [ 0.039022] memory[0x1] [0x0000000000100000-0x000000007fffffff], 0x000000007ff00000 bytes flags: 0x0 [ 0.039067] reserved.cnt = 0x3 [ 0.039080] reserved[0x0] [0x0000000000000000-0x000000000000ffff], 0x0000000000010000 bytes flags: 0x0 [ 0.039099] reserved[0x1] [0x000000000009f000-0x00000000000fffff], 0x0000000000061000 bytes flags: 0x0 [ 0.039116] reserved[0x2] [0x0000000001000000-0x0000000002c08fff], 0x0000000001c09000 bytes flags: 0x0 |
6.3:从memblock到zone
在系统的最初阶段,我们使用memblock做内存分配。但是在函数start_kernel -> mm_init -> mem_init之后,我们就从memblock转变到了伙伴系统。我们观察函数mem_init的作用
|
void __init mem_init(void) { pci_iommu_alloc(); /* clear_bss() already clear the empty_zero_page */ /* this will put all memory onto the freelists */ memblock_free_all(); //将memblock中的空闲内存释放给伙伴系统 …… } |
通过函数memblock_free_all,将memblock中的非reserved内存块添加到伙伴系统中去。
|
/** * memblock_free_all - release free pages to the buddy allocator * * Return: the number of pages actually released. */ unsigned long __init memblock_free_all(void) { unsigned long pages; reset_all_zones_managed_pages(); //将节点的所有zone的managed_pages设置为0 pages = free_low_memory_core_early(); totalram_pages_add(pages); //将pages数量加到_totalram_pages上 return pages; } |
|
static unsigned long __init free_low_memory_core_early(void) { unsigned long count = 0; phys_addr_t start, end; u64 i; memblock_clear_hotplug(0, -1); for_each_reserved_mem_range(i, &start, &end) reserve_bootmem_region(start, end);//设置这段内存中,所有的page的PG_reserved标志 /* * We need to use NUMA_NO_NODE instead of NODE_DATA(0)->node_id * because in some case like Node0 doesn't have RAM installed * low ram will be on Node1 */ for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end, NULL)//遍历所有在memory,并且不在reserved中的内存块。这些memblock可以通过/sys/kernel/debug/memblock/目录查看 count += __free_memory_core(start, end); //返回页框数目 return count; } |
|
//这里的入参start表示了memory中内存块的起始物理地址,end表示结束物理地址 static unsigned long __init __free_memory_core(phys_addr_t start, phys_addr_t end) { unsigned long start_pfn = PFN_UP(start); //物理地址start对应的页框号 unsigned long end_pfn = min_t(unsigned long, PFN_DOWN(end), max_low_pfn); if (start_pfn >= end_pfn) return 0; __free_pages_memory(start_pfn, end_pfn); return end_pfn - start_pfn; } |
|
//这里的入参分别是起始页框号与结束的页框号 static void __init __free_pages_memory(unsigned long start, unsigned long end) { int order; while (start < end) { order = min(MAX_ORDER - 1UL, __ffs(start)); while (start + (1UL << order) > end) order--; memblock_free_pages(pfn_to_page(start), start, order); //可见,是按照1<<order的数量释放到伙伴系统中的 start += (1UL << order); } } |
|
void __init memblock_free_pages(struct page *page, unsigned long pfn, unsigned int order) { __free_pages_core(page, order); } |
|
void __free_pages_core(struct page *page, unsigned int order) { unsigned int nr_pages = 1 << order; struct page *p = page; unsigned int loop; /* * When initializing the memmap, __init_single_page() sets the refcount * of all pages to 1 ("allocated"/"not free"). We have to set the * refcount of all involved pages to 0. */ prefetchw(p); for (loop = 0; loop < (nr_pages - 1); loop++, p++) { prefetchw(p + 1); __ClearPageReserved(p); //清除每个页的PG_reserved set_page_count(p, 0);//设置page->_refcount = 0。这个参数表示页被多少地方使用 } __ClearPageReserved(p); set_page_count(p, 0); atomic_long_add(nr_pages, &page_zone(page)->managed_pages);//managed_pages是内存区zone管理的所有,由memblock释放过来的可用页 /* * Bypass PCP and place fresh pages right to the tail, primarily * relevant for memory onlining. */ __free_pages_ok(page, order, FPI_TO_TAIL); //添加到伙伴系统使用的数据结构中 } |
函数__free_pages_ok的实现如下:
|
static void __free_pages_ok(struct page *page, unsigned int order, fpi_t fpi_flags) { unsigned long flags; int migratetype; unsigned long pfn = page_to_pfn(page); if (!free_pages_prepare(page, order, true)) return; migratetype = get_pfnblock_migratetype(page, pfn); //一个内存区中,多个页组成一个block。每个block有一种migratetype。这里获得page属于的block的migratetype local_irq_save(flags); __count_vm_events(PGFREE, 1 << order); free_one_page(page_zone(page), page, pfn, order, migratetype, fpi_flags); local_irq_restore(flags); } |
|
static void free_one_page(struct zone *zone, struct page *page, unsigned long pfn, unsigned int order, int migratetype, fpi_t fpi_flags) { spin_lock(&zone->lock); __free_one_page(page, pfn, zone, order, migratetype, fpi_flags); spin_unlock(&zone->lock); } |
|
static inline void __free_one_page(struct page *page, unsigned long pfn, struct zone *zone, unsigned int order, int migratetype, fpi_t fpi_flags) { struct capture_control *capc = task_capc(zone); unsigned long buddy_pfn; unsigned long combined_pfn; unsigned int max_order; struct page *buddy; bool to_tail; max_order = min_t(unsigned int, MAX_ORDER - 1, pageblock_order); //pageblock_order可以通过/proc/pagetypeinfo查看
if (likely(!is_migrate_isolate(migratetype))) __mod_zone_freepage_state(zone, 1 << order, migratetype);
continue_merging: while (order < max_order) {
buddy = page + (buddy_pfn - pfn); if (!pfn_valid_within(buddy_pfn)) goto done_merging; if (!page_is_buddy(page, buddy, order)) goto done_merging;
combined_pfn = buddy_pfn & pfn; page = page + (combined_pfn - pfn); pfn = combined_pfn; order++; } if (order < MAX_ORDER - 1) { /* If we are here, it means order is >= pageblock_order. * We want to prevent merge between freepages on isolate * pageblock and normal pageblock. Without this, pageblock * isolation could cause incorrect freepage or CMA accounting. * * We don't want to hit this code for the more frequent * low-order merging. */ if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt; buddy_pfn = __find_buddy_pfn(pfn, order); buddy = page + (buddy_pfn - pfn); buddy_mt = get_pageblock_migratetype(buddy); if (migratetype != buddy_mt && (is_migrate_isolate(migratetype) || is_migrate_isolate(buddy_mt))) goto done_merging; } max_order = order + 1; goto continue_merging; } done_merging: //我们在这里,找到了要添加到到free_list中的内存块 set_buddy_order(page, order); //伙伴系统的第一个page,page->private=order if (fpi_flags & FPI_TO_TAIL) to_tail = true; else if (is_shuffle_order(order)) to_tail = shuffle_pick_tail(); else to_tail = buddy_merge_likely(pfn, buddy_pfn, page, order); if (to_tail) add_to_free_list_tail(page, zone, order, migratetype); else add_to_free_list(page, zone, order, migratetype); //将page -> lru添加到链表zone -> free_area[order] ->free_list[migratetype]上 /* Notify page reporting subsystem of freed page */ if (!(fpi_flags & FPI_SKIP_REPORT_NOTIFY)) page_reporting_notify_free(order); } |
总之,我们已经从memblock过渡到了zone。也就是说,在最初构建好memblock之后,我们使用memblock做内存分配。然后在mem_init中,将所有的空闲内存释放到伙伴系统中。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









