







内容来自https://www.bilibili.com/video/BV1FT4y1E74V,仅为本人学习所用。
基础模型
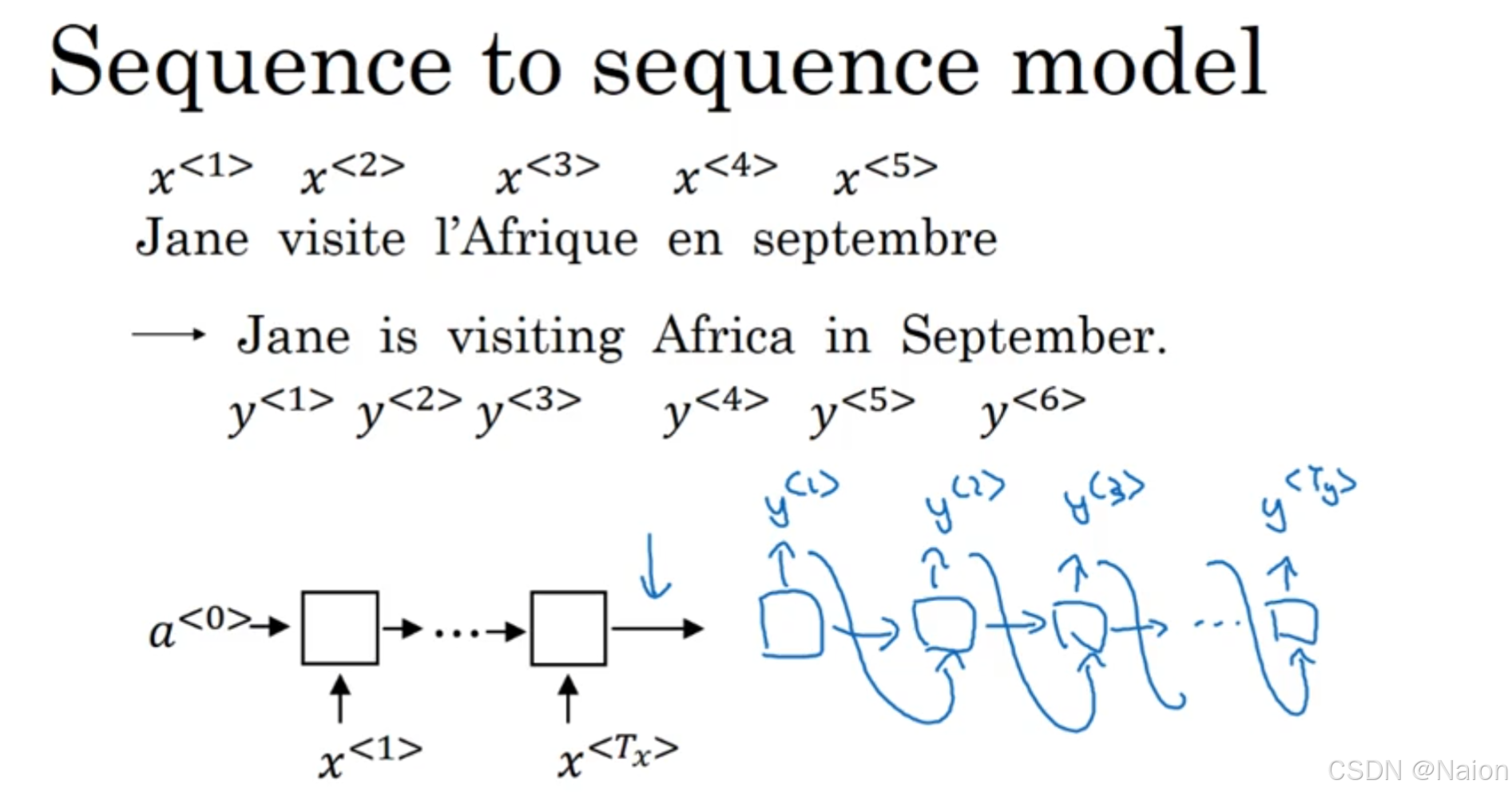
翻译模型:输入一个法语句子“Jane visite l’Afrique en septembre” ,经模型转换后输出对应的英语句子“Jane is visiting Africa in September.” 。分别用
x
<
1
>
x^{<1>}
x<1> 、
x
<
2
>
x^{<2>}
x<2> 、
x
<
3
>
x^{<3>}
x<3> 、
x
<
4
>
x^{<4>}
x<4> 、
x
<
5
>
x^{<5>}
x<5> 表示输入序列的各个元素(单词),用
y
<
1
>
y^{<1>}
y<1> 、
y
<
2
>
y^{<2>}
y<2> 、
y
<
3
>
y^{<3>}
y<3> 、
y
<
4
>
y^{<4>}
y<4> 、
y
<
5
>
y^{<5>}
y<5> 、
y
<
6
>
y^{<6>}
y<6> 表示输出序列的各个元素。
seq2seq模型由编码器和解码器组成:
- 编码器:左侧黑色部分,由RNN构成,RNN单元可以是GRU,也可以是LSTM。初始隐藏状态为 a < 0 > a^{<0>} a<0> ,依次接收输入序列元素 x < 1 > x^{<1>} x<1> 、 x < T x > x^{<T_x>} x<Tx> ( T x T_x Tx 为输入序列长度),对输入序列进行编码,将序列信息编码到隐藏状态中。
- 解码器:右侧蓝色部分,基于编码器的输出,逐步生成输出序列
y
<
1
>
y^{<1>}
y<1> 、
y
<
2
>
y^{<2>}
y<2> 等,生成过程中各时间步之间存在依赖关系。
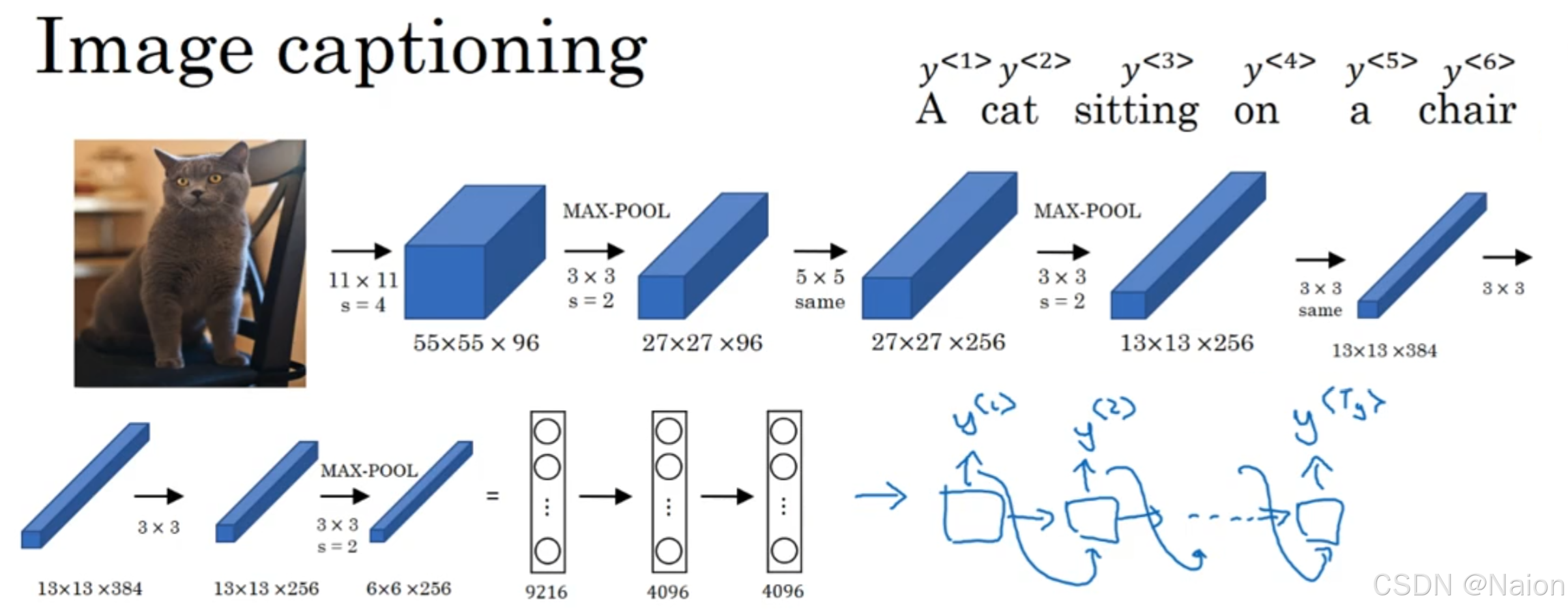
图像描述模型:输入的图像是一张猫坐在椅子上的图片,模型要生成描述这张图片内容的文本,如“A cat sitting on a chair”。
CNN部分,初始的卷积层使用大小为 11 × 11 11\times11 11×11,步长(s)为4的卷积核,输出特征图大小为 55 × 55 × 96 55\times55\times96 55×55×96。接着进行最大池化操作,池化核大小为 3 × 3 3\times3 3×3,步长为2,输出特征图变为 27 × 27 × 96 27\times27\times96 27×27×96。后续又经过多个卷积层和最大池化层,如 5 × 5 5\times5 5×5(same填充)的卷积层、 3 × 3 3\times3 3×3(步长为2)的最大池化层等,特征图尺寸和通道数不断变化,最终得到大小为 6 × 6 × 256 6\times6\times256 6×6×256的特征图。再经过进一步处理,将特征图展开为一维向量,维度从 6 × 6 × 256 6\times6\times256 6×6×256(即9216)经过全连接层变换到4096,再经过一次全连接层,到4096,最后通过接入RNN,而不是softmax层。
RNN部分,CNN处理后的信息输入到RNN中,RNN逐步生成描述文本的各个单词,如 y < 1 > y^{<1>} y<1>、 y < 2 > y^{<2>} y<2> 、 y < 3 > y^{<3>} y<3> 、 y < 4 > y^{<4>} y<4> 、 y < 5 > y^{<5>} y<5> 、 y < 6 > y^{<6>} y<6> ,最终形成完整的图像描述语句“A cat sitting on a chair” 。
选择最可能的句子
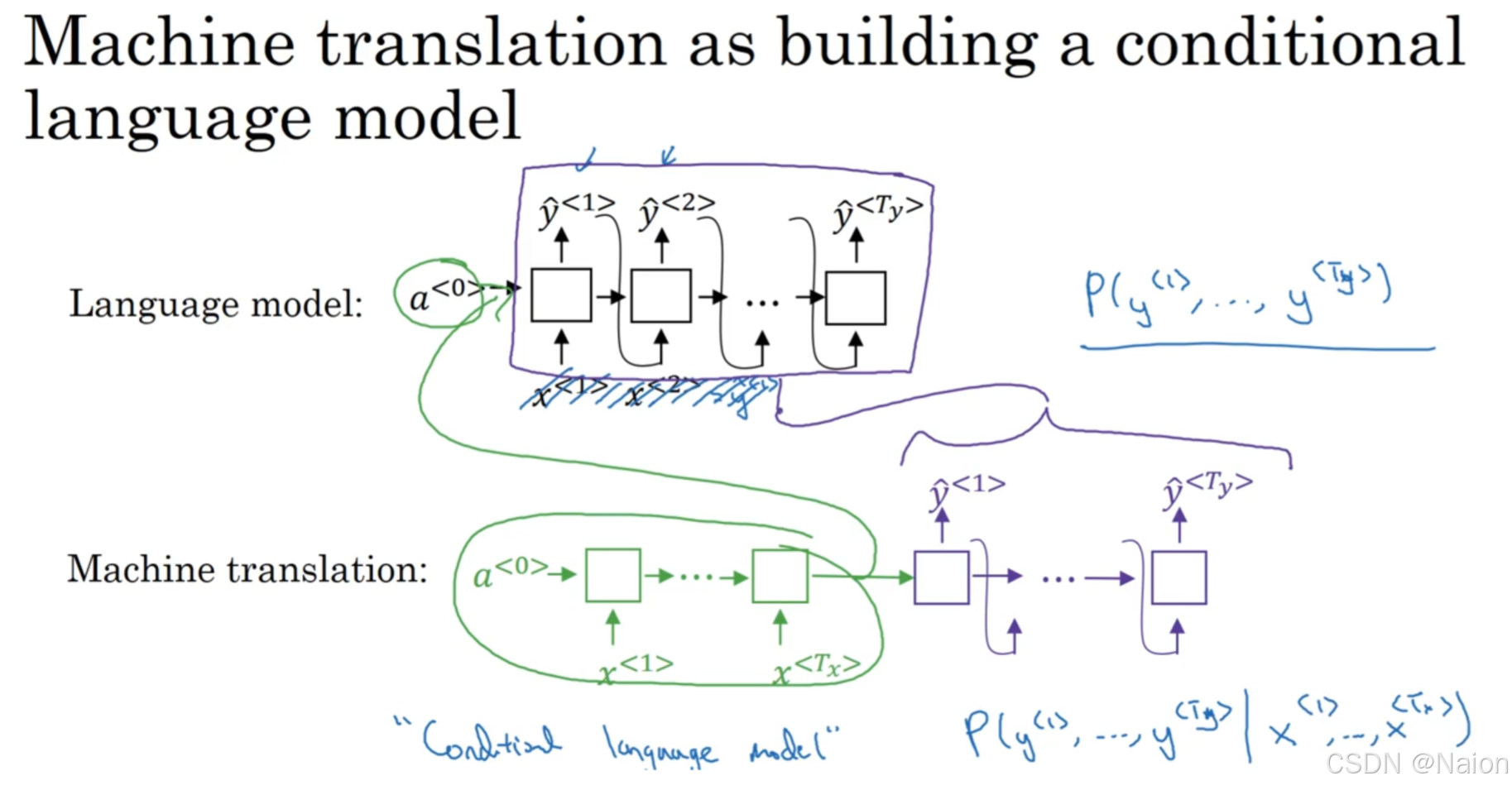
语言模型旨在计算一个句子出现的概率 P ( y < 1 > , … , y < T y > ) P(y^{<1>}, \ldots, y^{<T_y>}) P(y<1>,…,y<Ty>) 。输入初始隐藏状态 a < 0 > a^{<0>} a<0> ,接收输入序列 x < 1 > , x < 2 > , … , x < T x > x^{<1>}, x^{<2>}, \ldots, x^{<T_x>} x<1>,x<2>,…,x<Tx> ,通过一系列处理逐步输出预测的单词 y ^ < 1 > , y ^ < 2 > , … , y ^ < T y > \hat{y}^{<1>}, \hat{y}^{<2>}, \ldots, \hat{y}^{<T_y>} y^<1>,y^<2>,…,y^<Ty> 。
机器翻译可看作是一种条件语言模型,计算给定句子序列的前提下另一个句子序列的概率 P ( y < 1 > , … , y < T y > ∣ x < 1 > , … , x < T x > ) P(y^{<1>}, \ldots, y^{<T_y>} | x^{<1>}, \ldots, x^{<T_x>}) P(y<1>,…,y<Ty>∣x<1>,…,x<Tx>)。先通过编码器(绿色部分)处理输入序列 x < 1 > , x < T x > x^{<1>}, x^{<T_x>} x<1>,x<Tx> ,其结果再由解码器(紫色部分)基于该中间表示生成目标语言句子 y ^ < 1 > , y ^ < T y > \hat{y}^{<1>}, \hat{y}^{<T_y>} y^<1>,y^<Ty> 。该模型用于学习在给定源语言的条件下生成合理目标语言的概率分布,实现从一种语言到另一种语言的转换。
对于翻译出的结果有很多,但是我们希望能够给出最好的翻译,而不是随机文本翻译结果,可以使用Beam搜索算法。
Beam搜索算法
在序列生成过程中,每一步都保留概率最高的
k
k
k个候选(
k
k
k称为beam宽度),而不是像贪心搜索那样只保留一个最优候选。随着生成过程推进,基于这些候选继续生成下一步的可能结果,再从所有可能结果中选取概率最高的
k
k
k个候选,如此反复,直到生成完整序列。
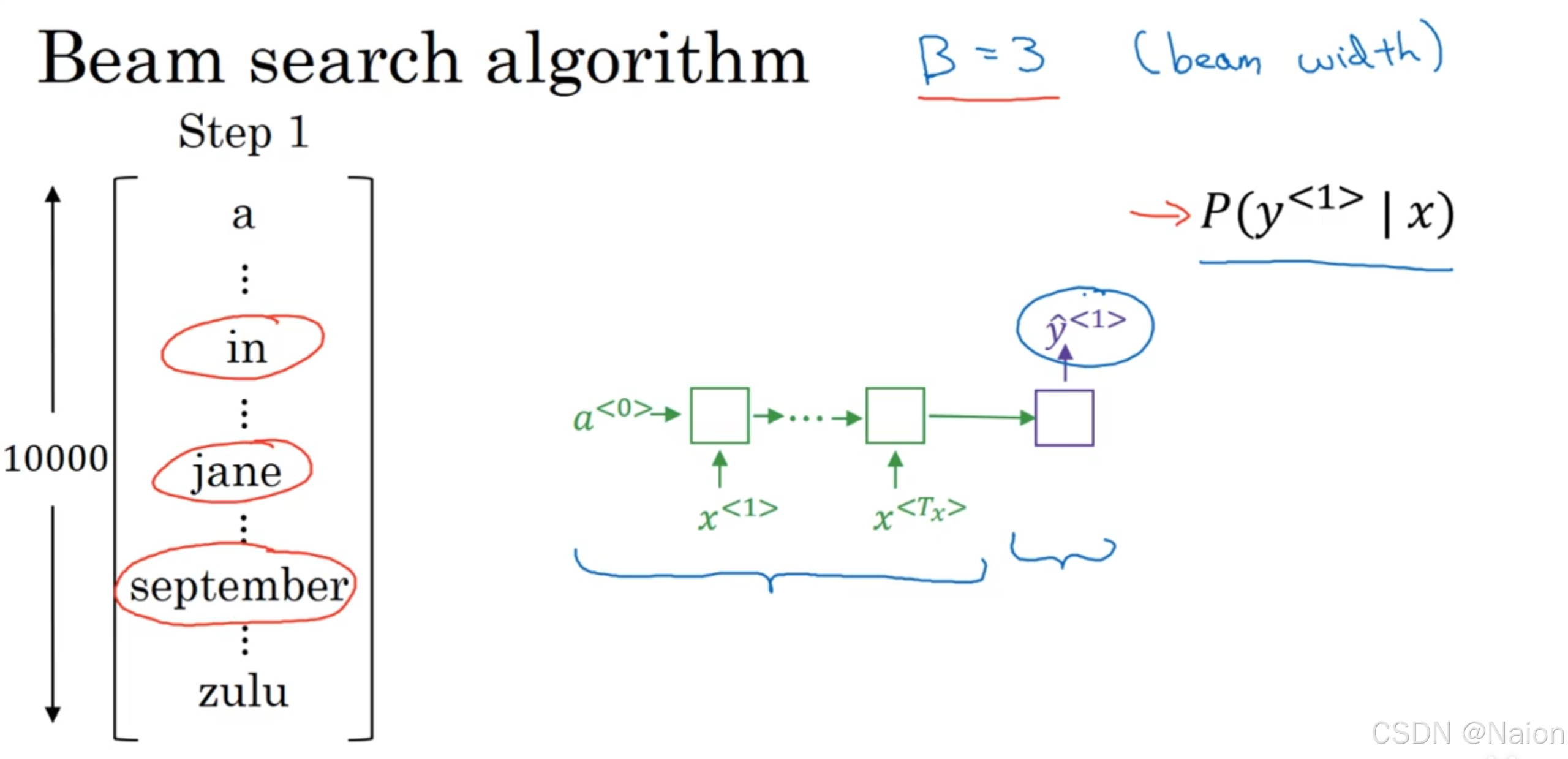 设beam宽度
B
=
3
B = 3
B=3。第一步:
设beam宽度
B
=
3
B = 3
B=3。第一步:
- 对于右侧的序列生成模型,初始隐藏状态 a < 0 > a^{<0>} a<0> ,经过编码器处理输入序列 x < 1 > , x < T x > x^{<1>}, x^{<T_x>} x<1>,x<Tx> (绿色部分),再由解码器(紫色部分)生成输出 y ^ < 1 > \hat{y}^{<1>} y^<1> 。
- 左侧词表大小为10000,在生成第一个单词时,模型计算出每个单词作为输出的概率
P
(
y
<
1
>
∣
x
)
P(y^{<1>} | x)
P(y<1>∣x)。假设用红色椭圆圈出了概率最高的3个单词“in”“jane”“september”。后续步骤会基于这3个候选继续生成下一个单词,重复上述过程,直到生成完整的序列。
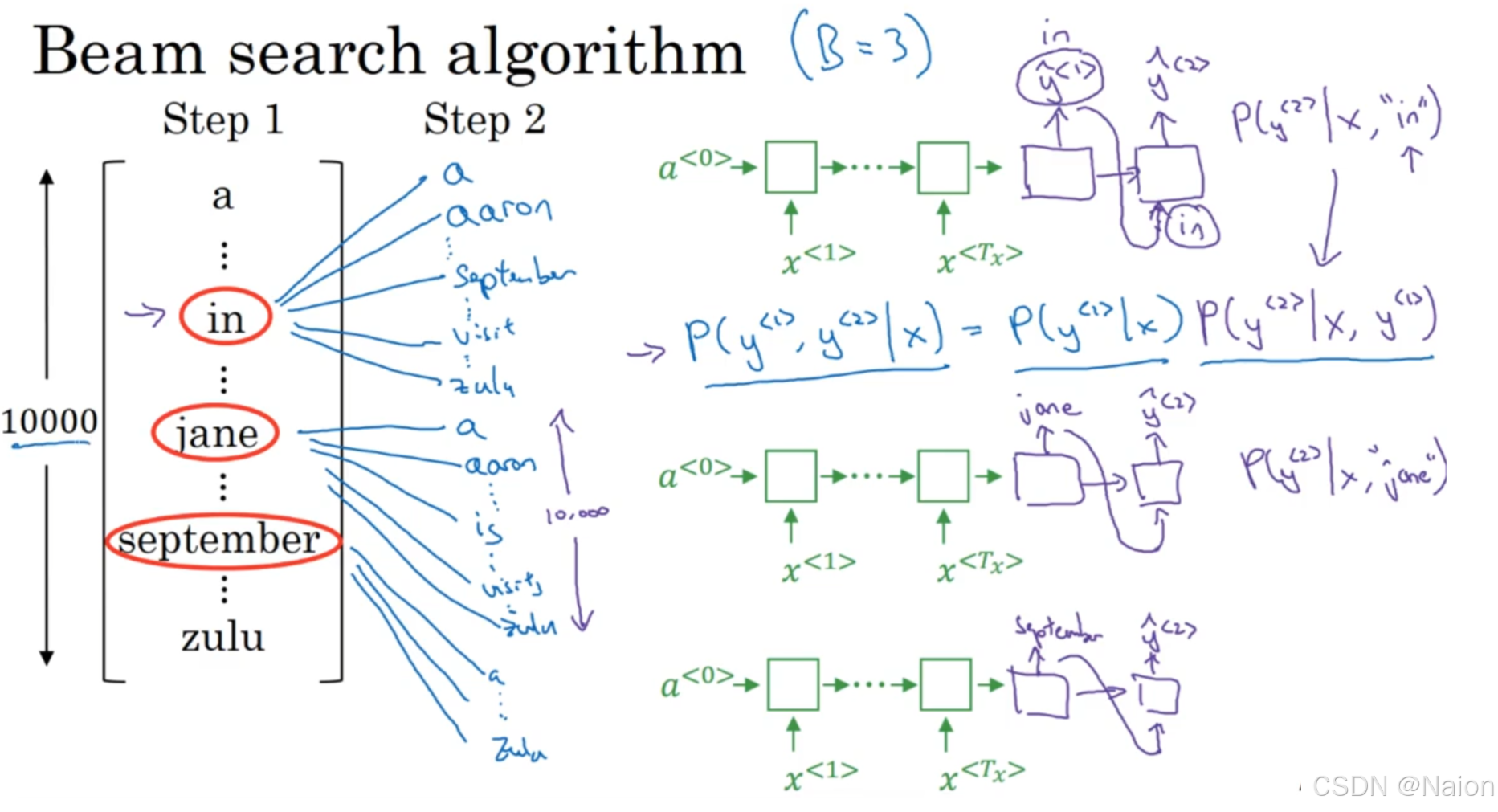
第二步: - 基于第一步保留的每个候选单词,分别计算下一步每个可能单词的概率。例如,对于“in”,计算已知输入序列为 x x x,且第一个单词为in时, P ( y < 2 > ∣ x , ′ i n ′ ) P(y^{<2>} | x, 'in') P(y<2>∣x,′in′) ;对于“jane”,计算 P ( y < 2 > ∣ x , ′ j a n e ′ ) P(y^{<2>} | x, 'jane') P(y<2>∣x,′jane′) 。
- 因为上下文之间有依赖性,计算这两步生成的文本之间的依赖性,使生成的序列更符合人类语言的逻辑和语法规则。因此,根据条件概率公式 P ( y < 1 > , y < 2 > ∣ x ) = P ( y < 1 > ∣ x ) P ( y < 2 > ∣ x , y < 1 > ) P(y^{<1>}, y^{<2>} | x) = P(y^{<1>} | x)P(y^{<2>} | x, y^{<1>}) P(y<1>,y<2>∣x)=P(y<1>∣x)P(y<2>∣x,y<1>) ,计算包含前两个单词的序列的联合概率。
- 从所有基于第一步候选生成的序列中,再次选取概率最高的3个序列作为新的候选,继续后续生成过程。
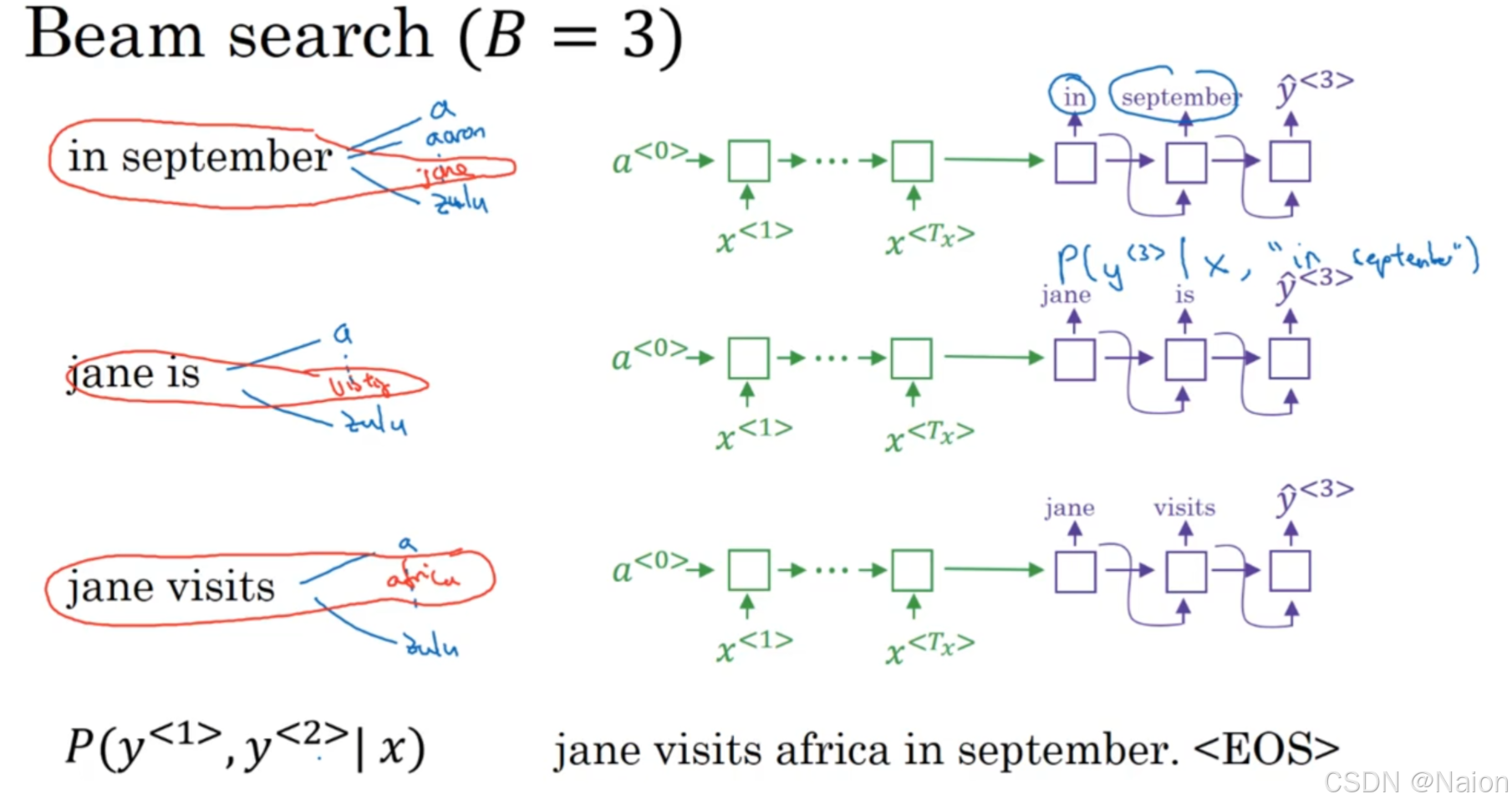
然后继续如此,一直到句末(EOS)。
改进Beam搜索

在原来计算概率的时候,目标是找到使
P
(
y
<
1
>
,
⋯
,
y
<
T
y
>
∣
x
)
P(y^{<1>}, \cdots, y^{<T_y>}|x)
P(y<1>,⋯,y<Ty>∣x)最大的输出序列
y
y
y 。根据概率链式法则,
P
(
y
<
1
>
,
⋯
,
y
<
T
y
>
∣
x
)
=
∏
t
=
1
T
y
P
(
y
<
t
>
∣
x
,
y
<
1
>
,
⋯
,
y
<
t
−
1
>
)
P(y^{<1>}, \cdots, y^{<T_y>}|x) = \prod_{t = 1}^{T_y}P(y^{<t>}|x,y^{<1>},\cdots,y^{<t - 1>})
P(y<1>,⋯,y<Ty>∣x)=∏t=1TyP(y<t>∣x,y<1>,⋯,y<t−1>) ,即整个序列的概率是各步条件概率的乘积。
为了便于计算和处理连乘,通常对其取对数,将连乘转换为累加,得到 ∑ t = 1 T y log P ( y < t > ∣ x , y < 1 > , ⋯ , y < t − 1 > ) \sum_{t = 1}^{T_y}\log P(y^{<t>}|x,y^{<1>},\cdots,y^{<t - 1>}) t=1∑TylogP(y<t>∣x,y<1>,⋯,y<t−1>)通过最大化这个对数概率和来寻找最优序列。
由于较长的序列其概率乘积往往较小,这会导致beam搜索等算法更倾向于较短的序列。为解决此问题,引入长度归一化。公式为 1 T y α ∑ t = 1 T y log P ( y < t > ∣ x , y < 1 > , ⋯ , y < t − 1 > ) \frac{1}{T_y^{\alpha}}\sum_{t = 1}^{T_y}\log P(y^{<t>}|x,y^{<1>},\cdots,y^{<t - 1>}) Tyα1t=1∑TylogP(y<t>∣x,y<1>,⋯,y<t−1>)其中 T y T_y Ty是生成序列的长度, α \alpha α是可调整的超参数(图中给出 α = 0.7 \alpha = 0.7 α=0.7 、 α = 1 \alpha = 1 α=1 、 α = 0 \alpha = 0 α=0等示例)。通过这种方式,对不同长度的序列进行概率调整,使得算法在选择序列时不会过度偏向短序列或长序列,平衡了序列长度对概率计算的影响,有助于找到更合理的输出序列。
如何选择合适的beam宽度?
如果B值较大,能考虑更多的候选路径,有更大机会找到全局较优解,从而得到更好的结果,但由于每一步需要计算和存储更多候选的后续可能性,计算量显著增加,导致算法运行速度变慢。
B值较小,候选路径少,计算量小,算法运行速度快,但可能因考虑的路径有限,容易陷入局部最优,得到较差的结果。
常见的取值范围,有1、3、10、100、1000、3000等。
定向搜索的误差分析
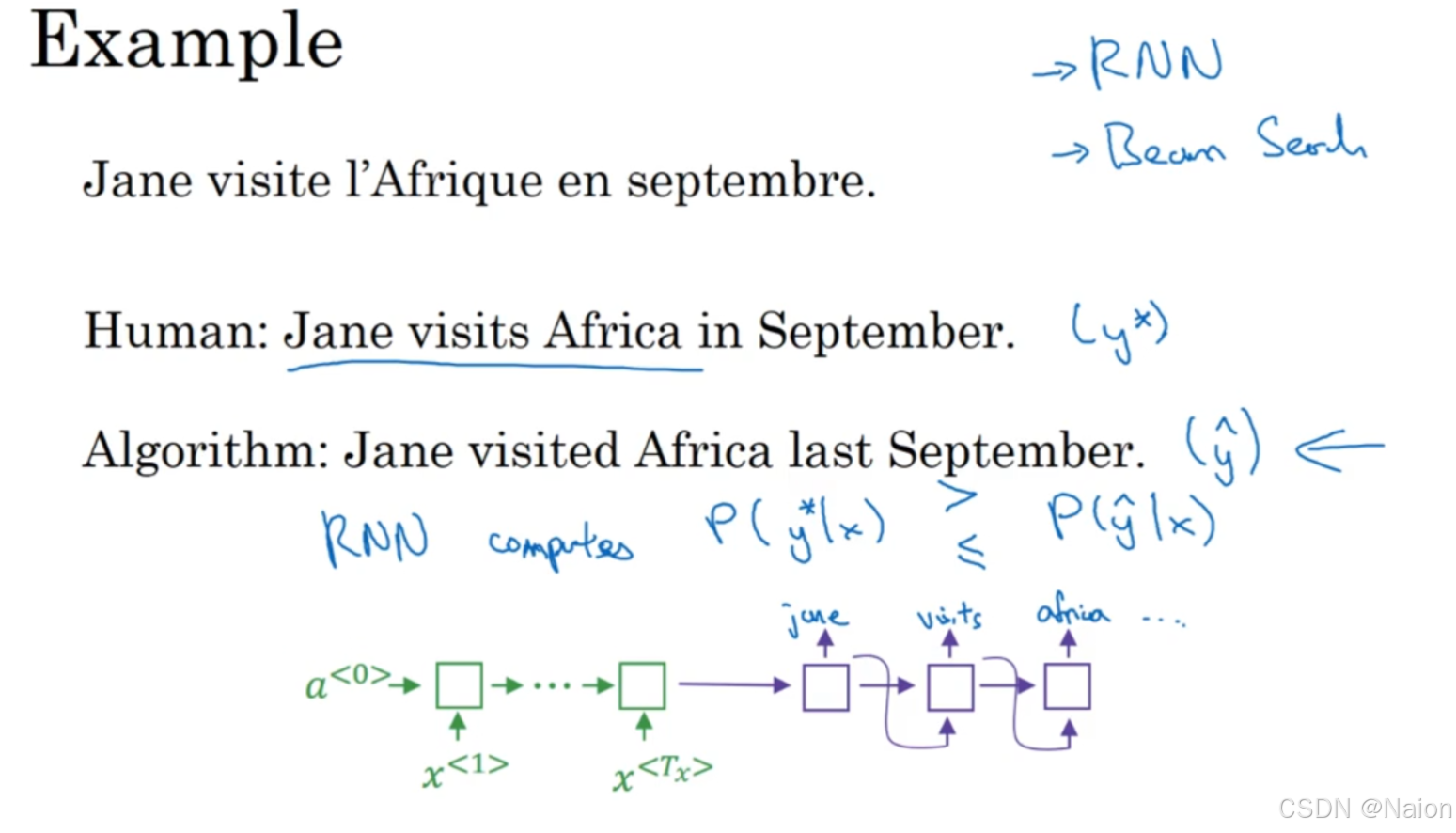
假设在开发集中,源句子是“Jane visite l’Afrique en septembre.” ,人类翻译:“Jane visits Africa in September.” ,标记为
y
∗
y^*
y∗ ,即理想的正确翻译结果。RNN模型运用Beam算法翻译:“Jane visited Africa last September.” ,标记为
y
^
\hat{y}
y^ 。
翻译模型由两部分组成:RNN和Beam算法,想知道算法翻译的不好的原因是这两个部分中的哪个导致的不好,RNN计算 P ( y ∗ ∣ x ) P(y^*|x) P(y∗∣x)即人类翻译结果在给定源语言句子 x x x下的概率和 P ( y ^ ∣ x ) P(\hat{y}|x) P(y^∣x)即算法翻译结果在给定源语言句子 x x x下的概率,比较其大小。

-
情况1: P ( y ∗ ∣ x ) > P ( y ^ ∣ x ) P(y^*|x) > P(\hat{y}|x) P(y∗∣x)>P(y^∣x) 。beam搜索选择了 y ^ \hat{y} y^ ,但实际上 y ∗ y^* y∗在 P ( y ∣ x ) P(y|x) P(y∣x)上取值更高。结论是Beam搜索算法存在问题,它没有选择概率更高的正确结果。
- Beam搜索是一种近似搜索算法,它在每一步只保留概率最高的 k k k(beam宽度)个候选。尽管从整体概率来看 y ∗ y^* y∗ 的 P ( y ∗ ∣ x ) P(y^*|x) P(y∗∣x) 更高,但可能在搜索的某些中间步骤, y ^ \hat{y} y^ 的部分路径概率表现突出,使得beam搜索在后续扩展中沿着 y ^ \hat{y} y^ 的路径进行,最终选择了它,而错过了全局上概率更高的 y ∗ y^* y∗ 。这体现了beam搜索并非全局最优搜索,可能会陷入局部最优解,导致没有选择到真正概率最高的结果。
-
情况2: P ( y ∗ ∣ x ) ≤ P ( y ^ ∣ x ) P(y^*|x) \leq P(\hat{y}|x) P(y∗∣x)≤P(y^∣x) 。虽然 y ∗ y^* y∗是比 y ^ \hat{y} y^更好的翻译,但RNN模型预测出 P ( y ∗ ∣ x ) < P ( y ^ ∣ x ) P(y^*|x) < P(\hat{y}|x) P(y∗∣x)<P(y^∣x) 。结论是RNN模型存在问题,它对概率的预测未能反映出翻译质量的优劣。
- RNN模型计算的概率 P ( y ∣ x ) P(y|x) P(y∣x) 基于其训练学到的模式和参数。可能由于训练数据的局限性、模型结构的不足或对语言理解的偏差等原因,模型错误地估计了 y ∗ y^* y∗ 和 y ^ \hat{y} y^ 的概率。比如训练数据中类似“last September”的表达出现频率较高,使得模型在计算概率时给予了 y ^ \hat{y} y^ 过高的概率;或者模型未能充分捕捉到“in September”在当前语境下的正确语义和语法概率,从而低估了 y ∗ y^* y∗ 的概率,导致预测的概率与实际翻译质量不匹配。
注意力模型
直观理解
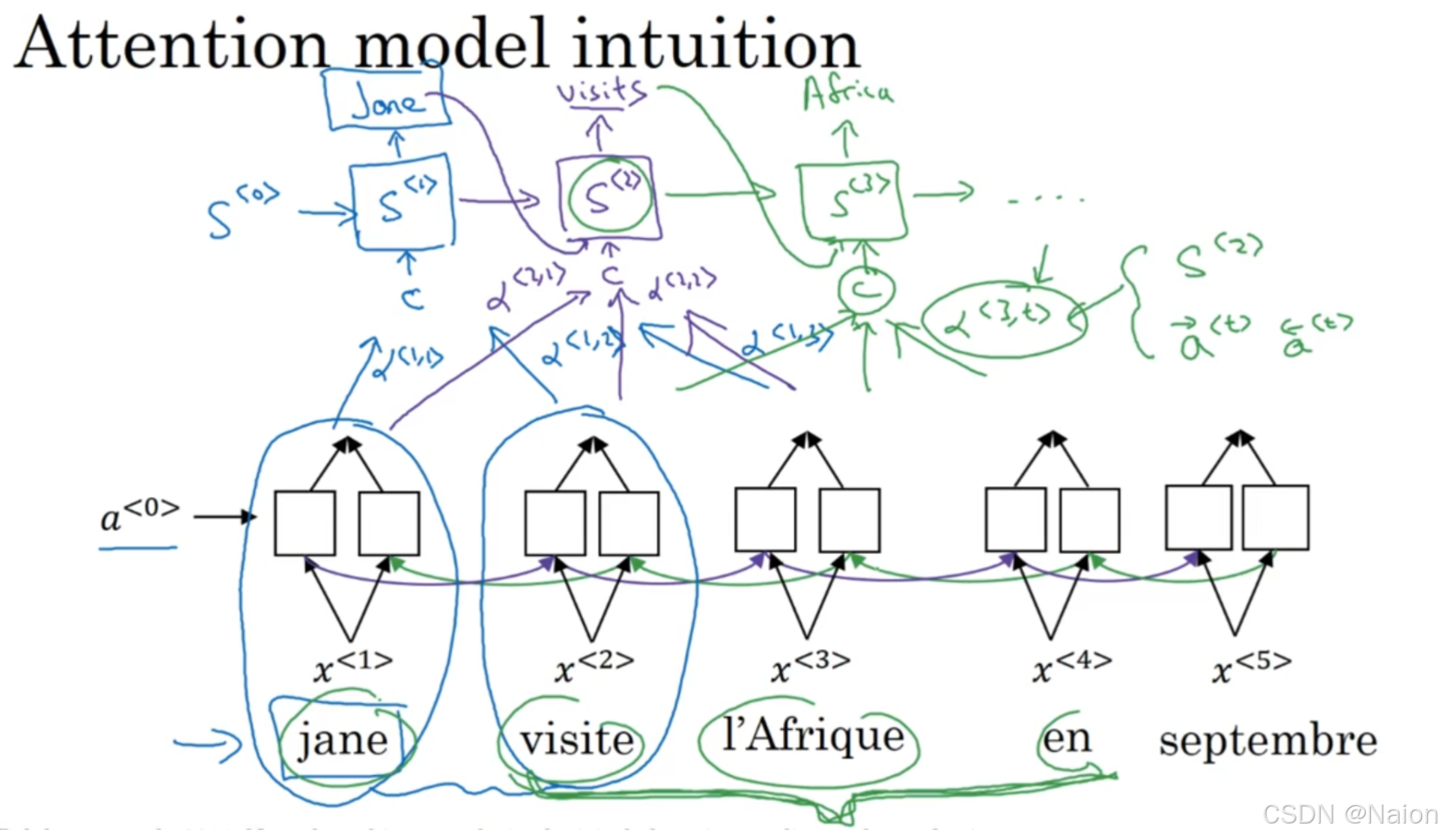
输入句子“jane visite l’Afrique en septembre”,用
x
<
1
>
,
x
<
2
>
,
x
<
3
>
,
x
<
4
>
,
x
<
5
>
x^{<1>}, x^{<2>}, x^{<3>}, x^{<4>}, x^{<5>}
x<1>,x<2>,x<3>,x<4>,x<5> 表示。双向RNN中,初始隐藏状态为
a
<
0
>
a^{<0>}
a<0> ,编码器对输入序列进行处理,使用另一个RNN生成翻译结果,用
s
<
0
>
s^{<0>}
s<0>表示初始隐藏状态。
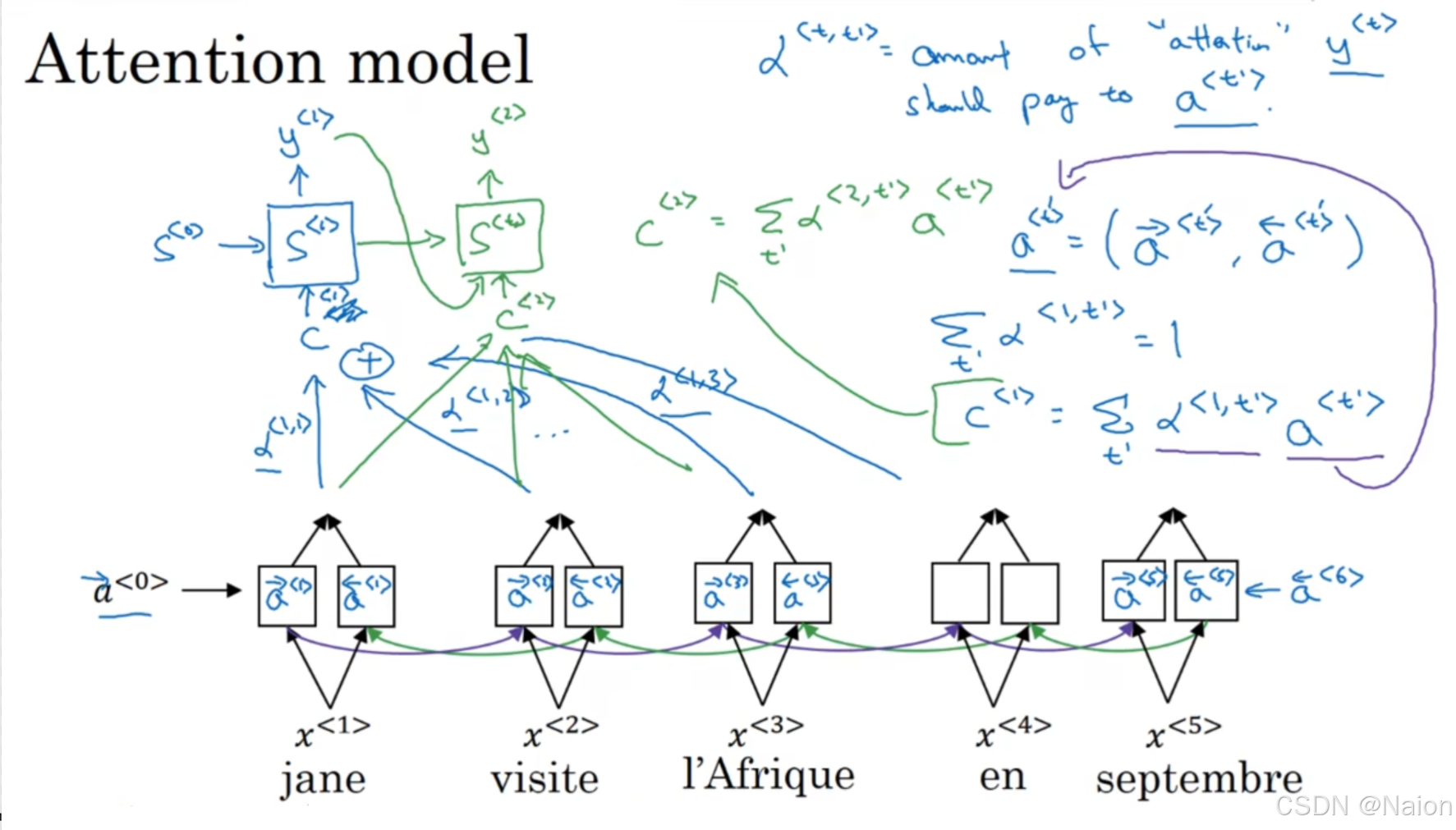
在生成输出时(如生成“Jane”“visits”等单词),注意力机制计算输入序列元素与当前生成位置的权重关系,输出的结果使用 α < 1 , 1 > \alpha^{<1,1>} α<1,1>表示模型应该放多少注意力在 x < 1 > x^{<1>} x<1>中,放多少注意力在 x < 2 > x^{<2>} x<2>中(重点关注上下文)…继续计算下一个 s < 2 > s^{<2>} s<2>,得出权重值。图中的 α < t , t ′ > \alpha^{<t,t'>} α<t,t′>表示这种对齐权重(例如 α < 1 , 1 > , α < 1 , 2 > , α < 1 , 3 > \alpha^{<1,1>}, \alpha^{<1,2>}, \alpha^{<1,3>} α<1,1>,α<1,2>,α<1,3>等)。这些权重体现了在生成某个输出单词时,模型对输入序列中不同位置的关注程度。通过对输入隐藏状态按照注意力权重进行加权求和,得到上下文向量 c c c ,参与到后续输出隐藏状态 S < t > S^{<t>} S<t>的计算中。例如,在生成“Jane”时, S < 1 > S^{<1>} S<1>的计算会用到基于注意力权重得到的上下文向量 c c c ,以及前一个隐藏状态 S < 0 > S^{<0>} S<0>。
模型
α
<
t
,
t
′
>
\alpha^{<t,t'>}
α<t,t′>表示在生成输出
y
<
t
>
y^{<t>}
y<t>时,对输入隐藏状态
a
<
t
′
>
a^{<t'>}
a<t′>的注意力权重,是输出时对输入序列不同位置的关注程度。例如生成
y
<
2
>
y^{<2>}
y<2>时,会计算一系列
α
<
2
,
t
′
>
\alpha^{<2,t'>}
α<2,t′>来确定对各个输入位置的注意力分配。
注意力权重满足 ∑ t ′ α < t , t ′ > = 1 \sum_{t'}\alpha^{<t,t'>}=1 ∑t′α<t,t′>=1,即对输入序列所有位置的注意力权重之和为1,确保权重是一个有效的概率分布。
上下文向量
c
<
t
>
c^{<t>}
c<t>通过对输入隐藏状态
a
<
t
′
>
a^{<t'>}
a<t′>按照注意力权重
α
<
t
,
t
′
>
\alpha^{<t,t'>}
α<t,t′>加权求和得到,即
c
<
t
>
=
∑
t
′
α
<
t
,
t
′
>
a
<
t
′
>
c^{<t>}=\sum_{t'}\alpha^{<t,t'>}a^{<t'>}
c<t>=∑t′α<t,t′>a<t′>。
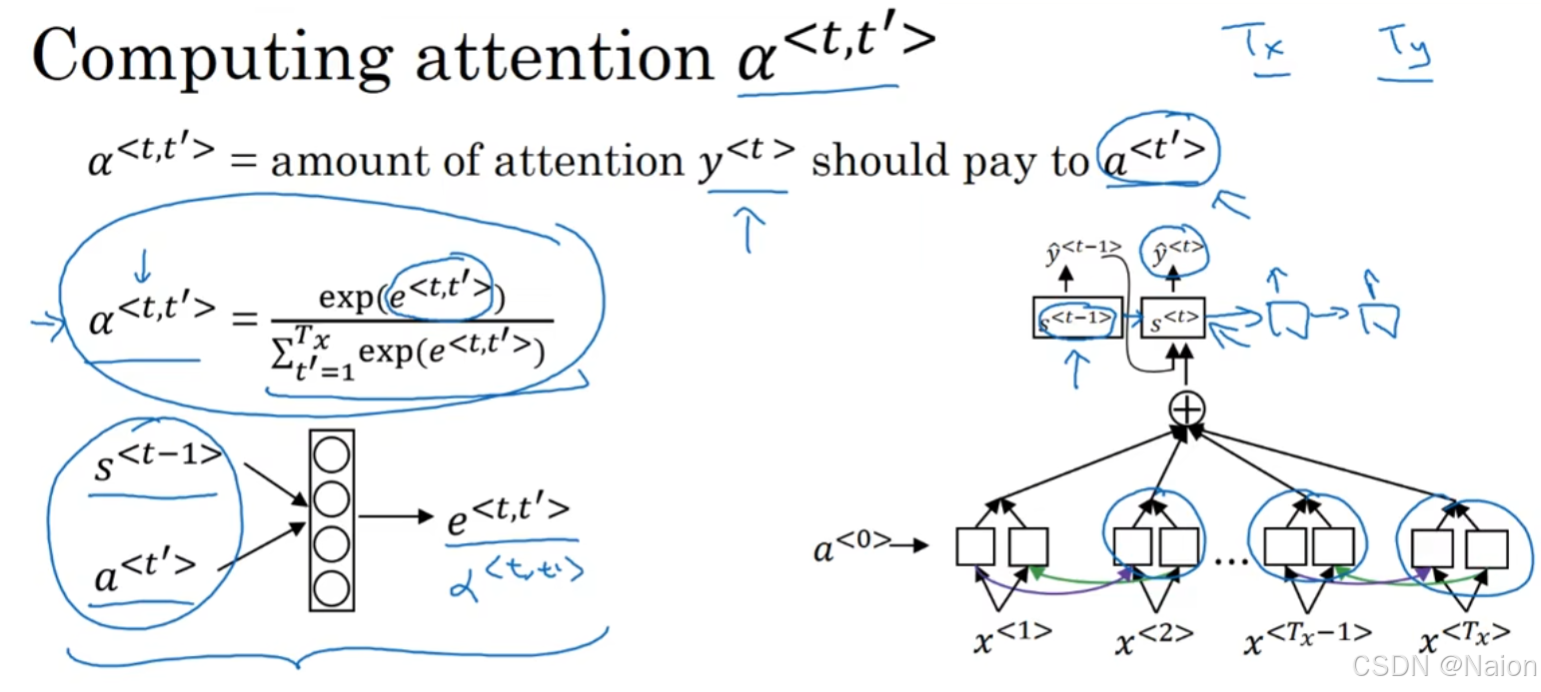
计算
α
<
t
,
t
′
>
\alpha^{<t,t'>}
α<t,t′>步骤如下:
- 计算注意力分数 e < t , t ′ > e^{<t,t'>} e<t,t′>:将解码器前一时刻的隐藏状态 s < t − 1 > s^{<t - 1>} s<t−1>和编码器在 t ′ t' t′时刻的隐藏状态 a < t ′ > a^{<t'>} a<t′>作为输入,通过一个模型(公式下面的模型)计算得到注意力分数 e < t , t ′ > e^{<t,t'>} e<t,t′> 。
- 计算注意力权重 α < t , t ′ > \alpha^{<t,t'>} α<t,t′>:使用softmax函数对注意力分数进行归一化,公式为 α < t , t ′ > = exp ( e < t , t ′ > ) ∑ t ′ = 1 T x exp ( e < t , t ′ > ) \alpha^{<t,t'>}=\frac{\exp(e^{<t,t'>})}{\sum_{t' = 1}^{T_x}\exp(e^{<t,t'>})} α<t,t′>=∑t′=1Txexp(e<t,t′>)exp(e<t,t′>) 。分母是对所有输入位置 t ′ t' t′(从 1 1 1到 T x T_x Tx, T x T_x Tx为输入序列长度)的注意力分数的指数值求和,分子是当前位置 t ′ t' t′的注意力分数的指数值。通过这种方式,将注意力分数转换为概率分布,使得 ∑ t ′ = 1 T x α < t , t ′ > = 1 \sum_{t' = 1}^{T_x}\alpha^{<t,t'>}=1 ∑t′=1Txα<t,t′>=1,得到在生成 y < t > y^{<t>} y<t>时对输入序列各个位置的注意力权重。
语音辨识
语音识别除了可以使用注意力模型之外,还可以使用CTC损失函数。
CTC损失函数

CTC引入了“空白(blank)”标签(图中标注为“blank” ),在输出序列中可以出现空白字符。例如,可能输出像 “ttt_h_eee___” 这样的序列,其中 “_” 代表空白,space表示空格。空白字符的引入允许模型在不确定对应具体字符时输出空白,之后再将连续相同字符合并以及去除空白,从而得到最终的识别文本。比如 “ttt_h_eee___” 经过处理可能得到 “the” 。
触发字检测
触发语音助手时需说一句触发词,比如“小度小度”…
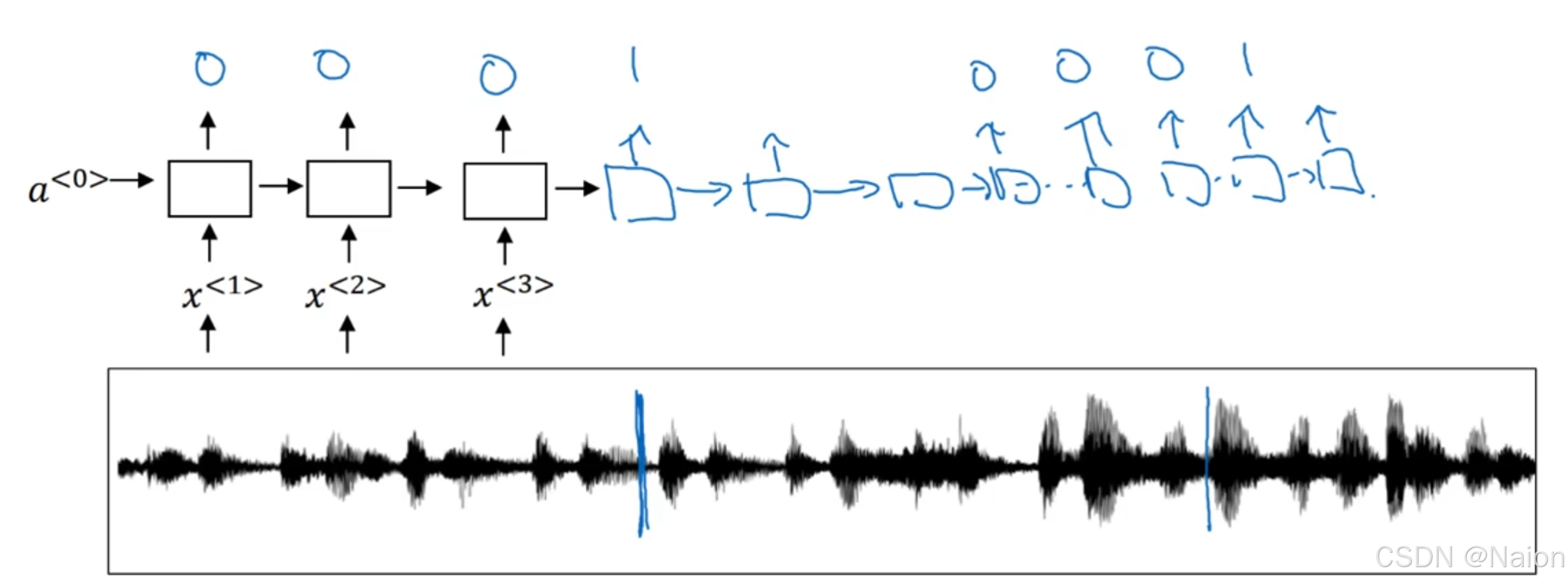
使用RNN来构建模型,输入向量分别为
x
<
1
>
,
x
<
2
>
,
x
<
3
>
x^{<1>}, x^{<2>}, x^{<3>}
x<1>,x<2>,x<3>…当语音未检测到触发字时,输出标签是0;当语音检测到触发字时候,输出标签为1…只要出现触发词后一小段时间内模型识别了出来并给予了标记,那么模型是可以用的。
这个算法有个问题是输出的0较多,输出的1较少,导致训练集不平衡。相对于只在一个时间步上输出1,可以在输出0前多输出1(一段时间内)。

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









