










这是一篇个人向的笔记。
推荐学习顺序:
- (可选)最好掌握线性代数、微积分、概率论的一些基本知识
- 学习吴恩达机器学习课程
- 学习吴恩达深度学习的前4课(也可以选择性学习部分内容)
- 然后可以学习本课,即吴恩达深度学习第五课的第一周内容
本课程视频
本课程文字版
目录
- 1.1 为什么选择序列模型?(Why Sequence Models?)
- 1.2 数学符号(Notation)
- 1.3 循环神经网络模型(Recurrent Neural Network Model)
- 1.4 通过时间的反向传播(Backpropagation through time)
- 1.5 不同类型的循环神经网络(Different types of RNNs)
- 1.6 语言模型和序列生成(Language model and sequence generation)
- 1.7 对新序列采样(Sampling novel sequences)
- 1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
- 1.9 GRU单元(Gated Recurrent Unit(GRU))
- 1.10 长短期记忆(LSTM(long short term memory)unit)
- 1.11 双向循环神经网络(Bidirectional RNN)
- 1.12 深层循环神经网络(Deep RNNs)
- 本周编程作业
- 另:pytorch的LSTM
1.1 为什么选择序列模型?(Why Sequence Models?)
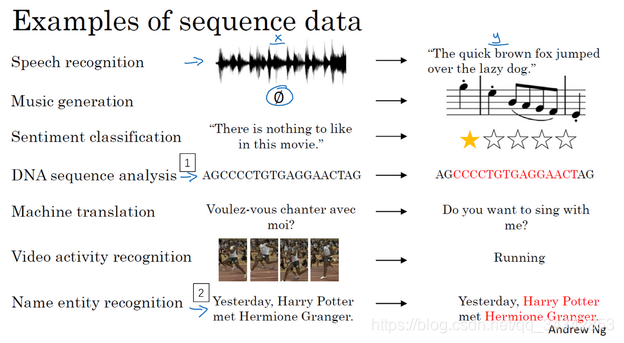
1.2 数学符号(Notation)
- 数学符号
- 输入x,输出y。
- 用x<t>和y<t> 来索引序列中的某个值。
- Tx 和Ty分别表示输入和输出的长度
- x(i)表示第i个训练样本。所以第i个样本的第t个元素是x(i)<t>
- Tx(i)是滴i个训练样本的输入序列长度
- 单词表示
- NLP中的词典:做一张词表/词典,每个单词有一个id:
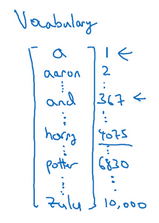
- 本例中词典大小为10000个单词
- 商业应用中常见30000-50000,甚至大公司有百万词。
- 有了词典,每个单词就被表示为一个onehot向量,向量有10000个元素,只有一个元素为1,其余为0
- 词典里面没有的词在后面的课程里会讲怎么办
- NLP中的词典:做一张词表/词典,每个单词有一个id:
1.3 循环神经网络模型(Recurrent Neural Network Model)
传统神经网络的问题:
- 不同样本的输入和输出的长度不同。
- 无法共享从文本不同位置上学到的特征。比如某处的Harry是个人名,别的地方的Harry也是。
- 每个单词是一个和词典等大的onehot向量,因此输入巨大。
.
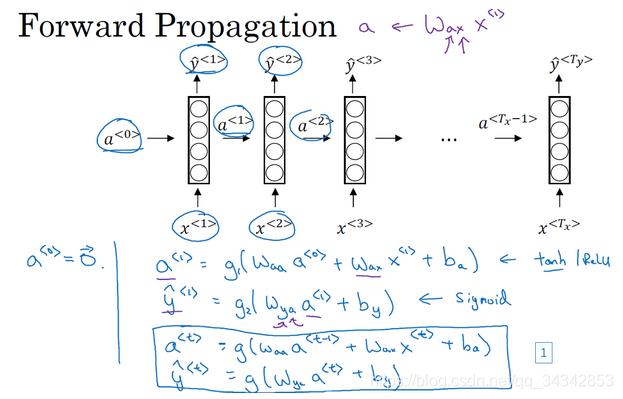
因此最好设计一个全新的网络结构来解决这些问题。这就是RNN。具体流程如图,大意就是,有一个神经网络层。
这个层的有两个输入:单词x<t> 和 上一个单词的激活值a<t-1>。 (x的个数是输入特征的维数,a的是输出的维数)
这个层有两个输出:标签y<t> 和 激活值a<t>.
逐个单词输入该层即可。
注意:
- 第一个单词的需要用到的a<t-1>通常取全零向量即可
- y是在a的基础上激活的,计算y的过程中用到两次激活函数
- 通常a的激活函数选用tanh,偶尔用ReLu
- 通常y的激活函数选sigmoid,因为我们例子是判断一个单词是不是人名(二分类)
更加简化的表达式,我们可以合并Waa和Wax为Wa ,过程如下:
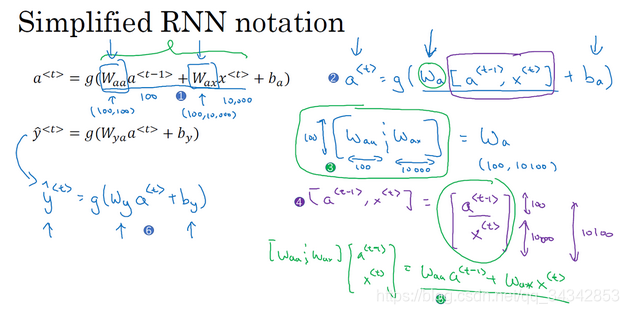
结果是只有Wa,ba,Wy,by四个参数:
a<t> = g(Wa [a<t-1>,x<t> ]) + ba
y<t> = g(Wy a<t>) + by
其中,Wa是原来的Waa和Wax横向拼接的结果,
[a<t-1>,x<t> ]是纵向拼接的结果。
1.4 通过时间的反向传播(Backpropagation through time)
略。(由于框架会自动处理的,但吴老师认为了解一下会有好处。后面有空再看)
1.5 不同类型的循环神经网络(Different types of RNNs)
问题引入:
- 对于上文提到的模型,每个单词x<t> 输入对应一个分类标签y<t> ,即输入和输出的都是序列,且长度一致(Tx = Ty)。
- 但实际上有很多问题输入和输出的长度是不一致的,因此需要修改模型。
- 多对多 many to many
- 上文的人名识别就是,每个单词x<t> 输入对应一个分类标签y<t>
- 在所有时间上都输出
- 另外还有输入输出长度不一致的情况,比如机器翻译,给出一种语言的一句话含Tx个单词,输出另一种语言的一句话,可能含tx个单词
- 多对一: many to one
- 比如情感分类,输入是一句话,里面有很多单词;输出是一个情感数值,比如0-5.
- 不在所有时间上都输出,只在最后输出:
- 一对一 one to one
- 就是普通单层神经网络
- 一对多
- 如音乐生成, 输入一个整数,生成一段音乐
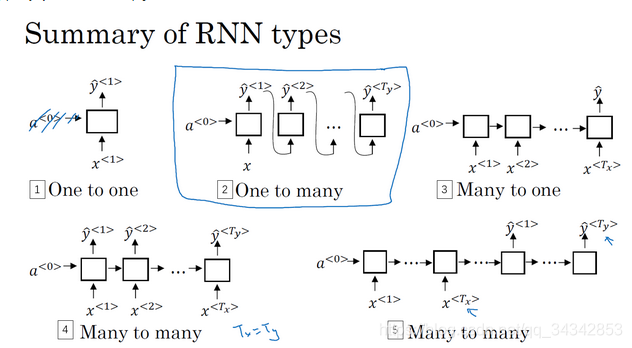
- 如音乐生成, 输入一个整数,生成一段音乐
1.6 语言模型和序列生成(Language model and sequence generation)
一些概念
- 英文文本语料库(corpus)
语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。 - EOS: end of sentence
在某些应用中,需要标明句子的结尾,就在每句话结尾加一个标记。 - UNK: unknown. 如果语料库中出现了不在词典里的词,就用UNK标记代替
一个语言模型:
语言模型所做的就是,它会告诉你某个特定的句子出现的概率是多少。
- 神经网络每一层用上一层的a和y_hat作为输入,输出a和y给下一层。
- 每一层的y_hat的size是字典大小,y_hat的值表示第n个单词是这个单词的概率(softmax)
- 而y是这个词本人(词典的one hot表达) (通常用y_hat的概率做随机采样来获得)
- 这样,每一时间t的输出都用到了前面所有的输入,每一时间t的输出都能得到一个最大概率的单词 把这些单词按顺序连接起来,就得到完整的text。
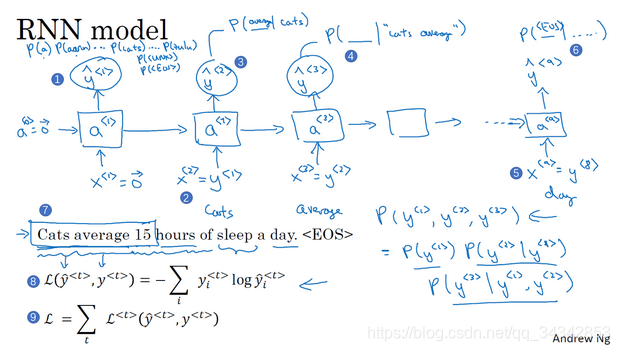
- 损失函数:softmax 的交叉熵函数
1.7 对新序列采样(Sampling novel sequences)
输出的每个yhat包含这个词是词典中每个词的概率,用这个概率进行随机采样,得到这个单词y。
每一层采样得到y,输出给下一层。
知道采样得到EOS
基于字符的语言模型:运算代价更高。现在一般有单词的都不这样操作。
1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
梯度消失问题:
- 长期依赖:t靠后的元素受离得很远的t靠前的元素的影响。
- 比如:The cats, which already ate, were full. 这个were需要考虑前面cats的单复数。而中间的which 可以无限长。
- RNN有多长的时间序列就有多少层。因此它层数多即网络深,很容易出现梯度消失问题。即反向传播的时候后层的梯度很难影响到前面。
- 因此必须想办法处理这个问题,否则RNN的每个t的元素只受前几个的影响。
- 解决方法详见后面几节。
为什么RNN的首要问题是梯度消失,梯度爆炸呢?
- 梯度爆炸很明显:模型参数会很大,会看到很多NaN
- 一个简单的解决办法:梯度修剪:观察梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大
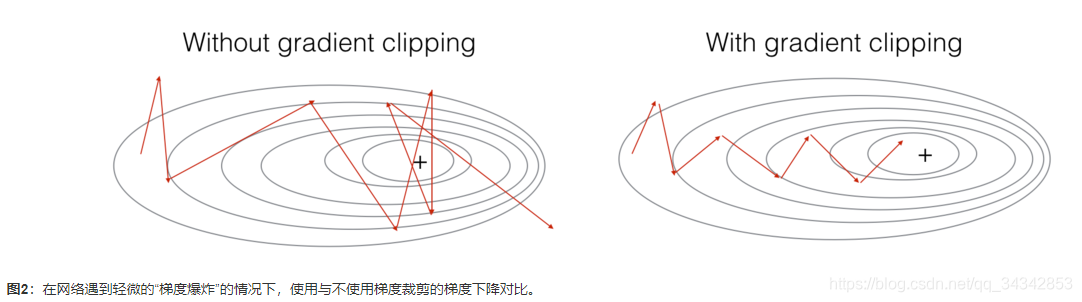
1.9 GRU单元(Gated Recurrent Unit(GRU))
- 增加一个变量叫c (memory cell)。
- ct在每个t时刻,可以保持不变,也可以更新。
- 用一个门来决定是否更新 (update gate)。(实际上是一个sigmoid得到的0-1的概率,为了直观,可以理解为就是0或1 ,即是否更新
- 门的shape和c一样,他俩是逐元素相乘;其他W乘什么东西的,都是点乘(或者说矩阵乘法)
- 门的参数由训练和输入得到。
- 在完整版中,增加了一个门 relerence gate,用来乘ct-1(相当于ct-1的权重)(至于为什么要这样呢,其实人们尝试过很多方法,发现这种操作效果挺好)
- 在GRU中,c就是a;但在LSTM中他俩不一样。
- 也有人把c叫h。
- 为了和LSTM统一符号,吴老师还是统一叫c。
- (编程作业中只有基础单双向RNN 和LSTM,没有GRU)

1.10 长短期记忆(LSTM(long short term memory)unit)
- (LSTM(long short term memory)unit)可以在序列中学习非常深的连接,甚至比GRU更加有效。
- LSTM有点像一个复杂版本的GRU:
- 增加forget gate, 用来乘以 ct-1
- 增加output gate, 用于:at = output gate * ct

LSTM总结:
- 首先用at-1 和 xt计算 c~ 和三个门:update gate, forget gate, output gate. (一个常见变种是用用at-1 和 xt和ct-1, 这叫做“窥视孔连接”(peephole connection))
- 两个门乘各自对应的c,相加得到新c
- 新c依此经过tanh和output gate,得到新a
- 新a乘Wy加by再经过激活函数(sigmoid或softmax)得到y
- 一般常见的分类的激活函数用sigmoid或softmax,其他的用tanh

c的记忆功能:
- c的值是否更新是可以学习的。
- 假设c是个n维向量,则它可以记住n个变量。比如其中一个就是cat是单数还是复数。
什么时候用GRU,什么时候用LSTM?
- 没有固定的规律
- 现在一般LSTM是普遍默认项,但也有很多人用GRU
- GRU的优点是参数少,容易扩展到更大的网络。
- LSTM的优点是更强大灵活
1.11 双向循环神经网络(Bidirectional RNN)
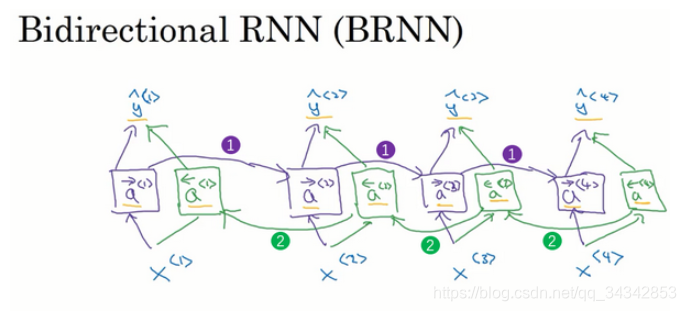
如图,在原来的单向RNN的基础上,中间的所有a都增加一个反向的。
网络首先从左到右计算紫色的a们,然后从又到左计算所有绿色的a们。
然后在基于紫色和绿色的a们计算y。
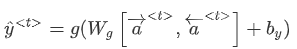
这些单元不仅可以是标准RNN单元,也可以是GRU单元或者LSTM单元。
很多的NLP问题,有LSTM单元的双向RNN模型是用的最多的。(这是几年前的说法了,现在有Transformer/BERT了)
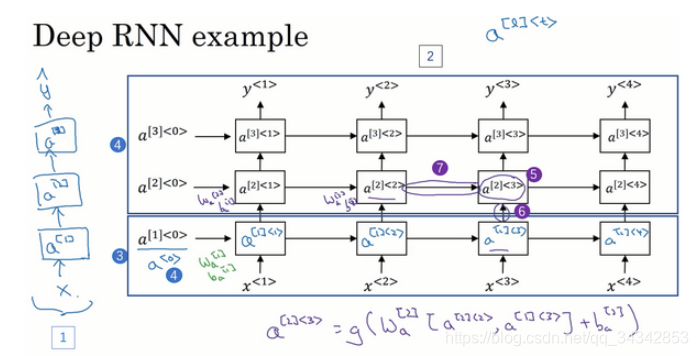
1.12 深层循环神经网络(Deep RNNs)
基础:
- 在上面的例子中,每个时间点t,我们都用了一个隐藏层a,(输入层x,输出层y)
- 我们可以用更多的隐藏层,比如三个。a[1],a[2],a[3]. 如图所示
- a是一个向量(隐藏层),每个a只由它下面和正左边的a影响(斜左边不行)
- 一般竖着的三层就已经很多了,因为还有时间维度
- 关于符号的整理:
- 尖括号上标t表示时间t
- 方括号上标l表示层数
- 圆括号上标i表示样本个数
- 下标i(如果有)表示这个向量的第i个元素
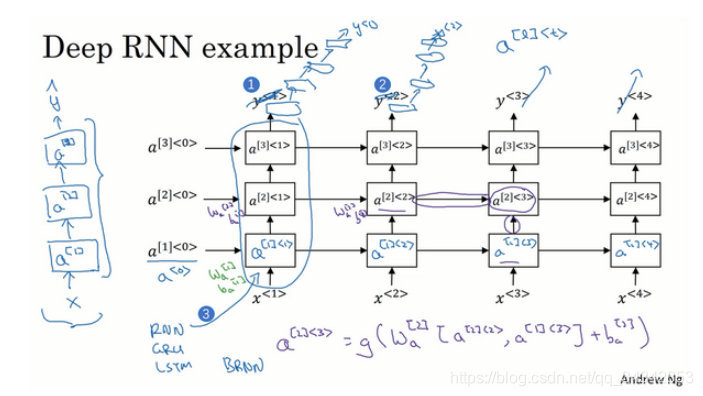
进阶版:
- 如图所示,可以再最后增加普通的DNN层,和下面三层的区别是不受左边元素影响
本周编程作业
本周课程完结撒花,接下来是作业时间。
作业指导链接
作业指导即所需文件数据连接
注意本周有三个作业:

作业一:RNN和LSTM用numpy构建
作业一指导链接
作业一只是实现了最基础的RNN和LSTM的结构,测试是使用的随机数,没有真实的数据或有趣的应用。只用了一个隐藏层。
- 二维矩阵点乘可以用np.dot 或np.matmul
- 门的形状和c是一样的,他俩是主元素相乘np.multiply 或 *
- LSTM 里的y还是要乘Wy再加by再激活,而不是直接激活就完事儿了
- 拼接可以用函数
concat = np.concatenate([a_prev,xt]), 注意需要一个中括号 - 第一遍写的时候发现,总的LSTM里面c是对的,但其他都是错的;核对发现a的初始化是给了个值的,c就直接0初始化就行了
- 反向传播我暂时没做
作业二:字符级语言模型(cclm: Character level language model)
搭建一个字符集语言模型,训练集是一些恐龙的名字,模型要能生成恐龙的名字
- 链接里面引用的包有点问题,应该是
import cclm_utils, 而不是import utils - 一维向量一定要注意:
np.zeros((n,1))不要漏了那个1,不然会有很多问题 - 注意到引用cllm_utils里面的rnn_forward的时候,最好把之前自己写的rnn_forward注释掉,不然有冲突
- 我的前几步结果都和链接一样,但最后我的loss在变,不知道是不是中途哪个seed没弄对
作业三:用LSTM生成爵士小歌
- 如果你在用Pycharm作为IDE,那么
IPython.display.Audio('./data/30s_seq.mp3')并不会播放音乐
官方回复如下:Unfortunately, PyCharms’ Jupyter integration doesn’t support widgets (PY-14534) so it is impossible to play audio files from the IDE.
参见https://intellij-support.jetbrains.com/hc/en-us/community/posts/360000019579-ipython-display-audio- 可以考虑直接到相应目录下双击打开mp3文件,用系统自带的播放器播放试听。
- 用pygame库代替IPython。首先
pip install pygame, 然后使用如下代码可播放:
import pygame
import time
path = r'./data/30s_seq.mp3'
#初始化音频
pygame.mixer.init()
#加载路径文件
pygame.mixer.music.load(path)
#播放
pygame.mixer.music.play()
#停止播放
#screen = pygame.display.set_mode((800, 600)) #音乐窗口是否显示. 没啥用,打开未响应。
#代码运行后持续10秒
time.sleep(10)
pygame.mixer.music.stop()
我跑的有点问题,下图中应为78的值我跑出来一直是90,导致后面有很多问题

另:pytorch的LSTM
官方文档: https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
符号
pytorch里的符号和吴老师用的有点不同,这里放个对照供参考

官方代码
rnn = torch.nn.LSTM(10, 20, 2) #input size, hidden size, num_layers
input = torch.randn(5, 3, 10) # seq_len, batch, input_size
# If the LSTM is bidirectional, num_directions should be 2, else it should be 1.
h0 = torch.randn(2, 3, 20) # num_layers * num_directions, batch, hidden_size
c0 = torch.randn(2, 3, 20) # num_layers * num_directions, batch, hidden_size
output, (hn, cn) = rnn(input, (h0, c0))
解释
torch.nn.LSTM
torch.nn.LSTM构造一个LSTM网络。(而非一个层)其参数如下。加粗的是重点参数,
- input_size:
输入特征维数(比如nlp中每个单词用词典的onehot表达,词典长度即为输入特征维数)- hidden_size:
隐层状态的维数- num_layers:
RNN层的个数,在图中竖向的是层数,横向的是seq_len- bias:
隐层状态是否带bias,默认为true- batch_first:
是否输入输出的第一维为batch_size,因为pytorch中batch_size维度默认是第二维度,故此选项可以将 batch_size放在第一维度。如input是(4,1,5),中间的1是batch_size,指定batch_first=True后就是(1,4,5)- dropout:
是否在除最后一个RNN层外的RNN层后面加dropout层- bidirectional:
是否是双向RNN,默认为false,若为true,则num_directions=2,否则为1
网络的输入
output, (hn, cn) = rnn(input, (h0, c0))
网络输入有三个,input, h0, c0. 三者都是三维tensor。
- input:(seq_len, batch, input_size)是我们的输入X,
- h0 : (num_layers * num_directions, batch, hidden_size)相当于吴老师讲的a0。 a只activation,h指hidden state,可以随机初始化或任意指定。direction是指单向还是双向。
- c:(num_layers * num_directions, batch, hidden_size)可以随机初始化或任意指定。
比如NLP,字典onehot表示每个词。
字典长度为5000,有100句话,每句话有10个词,则
seqlen = 10, batch = 100,inputsize=5000

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









