



 亚马逊云科技 (AWS) 开发者和解决方案架构师现在可以在基于 NVIDIA GPU 的 Amazon EC2 上使用 NVIDIA Dynamo,包括由 NVIDIA Blackwell 加速的 Amazon EC2 P6,并添加了对 Amazon Simple Storage (S3) 的支持,此外还有与 Amazon Elastic Kubernetes Services (EKS) 和 AWS Elastic Fabric Adapter (EFA) 的现有集成。此次更新将大规模部署大语言模型 (LLM) 的性能、可扩展性和成本效益提升到了新的水平。
亚马逊云科技 (AWS) 开发者和解决方案架构师现在可以在基于 NVIDIA GPU 的 Amazon EC2 上使用 NVIDIA Dynamo,包括由 NVIDIA Blackwell 加速的 Amazon EC2 P6,并添加了对 Amazon Simple Storage (S3) 的支持,此外还有与 Amazon Elastic Kubernetes Services (EKS) 和 AWS Elastic Fabric Adapter (EFA) 的现有集成。此次更新将大规模部署大语言模型 (LLM) 的性能、可扩展性和成本效益提升到了新的水平。
NVIDIA Dynamo 扩展并服务于生成式 AI
NVIDIA Dynamo 是专为大规模分布式环境打造的开源推理服务框架。它支持所有主流推理框架,例如 PyTorch、SGLang、TensorRT-LLM 和 vLLM,并包含高级优化功能,例如:
- 分离服务:在不同的 GPU 上分离预填充和解码推理阶段,以提高吞吐量。
- LLM 感知路由:通过路由请求,以更大限度地提高 KV 缓存命中率,并避免重复计算成本。
- KV 缓存卸载:将 KV 缓存卸载至经济高效的内存层级中,以降低推理成本。
这些功能使 NVIDIA Dynamo 能够为大规模多节点的 LLM 部署提供出色的推理性能和成本效益。
与亚马逊云科技服务无缝集成
对于在 AWS 云上部署 LLM 的 AWS 开发者和解决方案架构师,Dynamo 将无缝集成到您现有的推理架构中:
- Amazon S3: Dynamo NIXL 现在支持 Amazon S3,这是一种对象存储服务,可提供几乎无限的可扩展性、高性能和低成本。
计算 KV 缓存需要大量资源且成本高昂。通常会重复使用缓存值而不是重新计算。但是,随着 AI 工作负载的增长,重用所需的 KV 缓存量可能会迅速超过 GPU 甚至主机显存。通过将 KV 缓存卸载到 S3,开发者可以释放宝贵的 GPU 显存来处理新请求。这种集成减轻了开发者构建自定义插件的负担,使他们能够将 KV 缓存无缝卸载到 S3,从而降低总体推理成本。
- Amazon EKS: Dynamo 在 Amazon EKS 上运行,这是一种完全托管的 Kubernetes 服务,使开发者能够运行和扩展容器化应用程序,而无需管理 Kubernetes 基础设施。
随着 LLM 的规模和复杂性不断增加,生产环境中的推理部署现在需要高级组件,例如可感知 LLM 的请求路由、分离服务和 KV 缓存卸载。这些紧密集成的组件增加了在 Kubernetes 环境中部署的复杂性。借助这种支持,开发者可以将 Dynamo 无缝部署到由 EKS 管理的 Kubernetes 集群中,使他们能够按需快速启动新的 Dynamo 副本,以处理推理工作负载的突发增长。
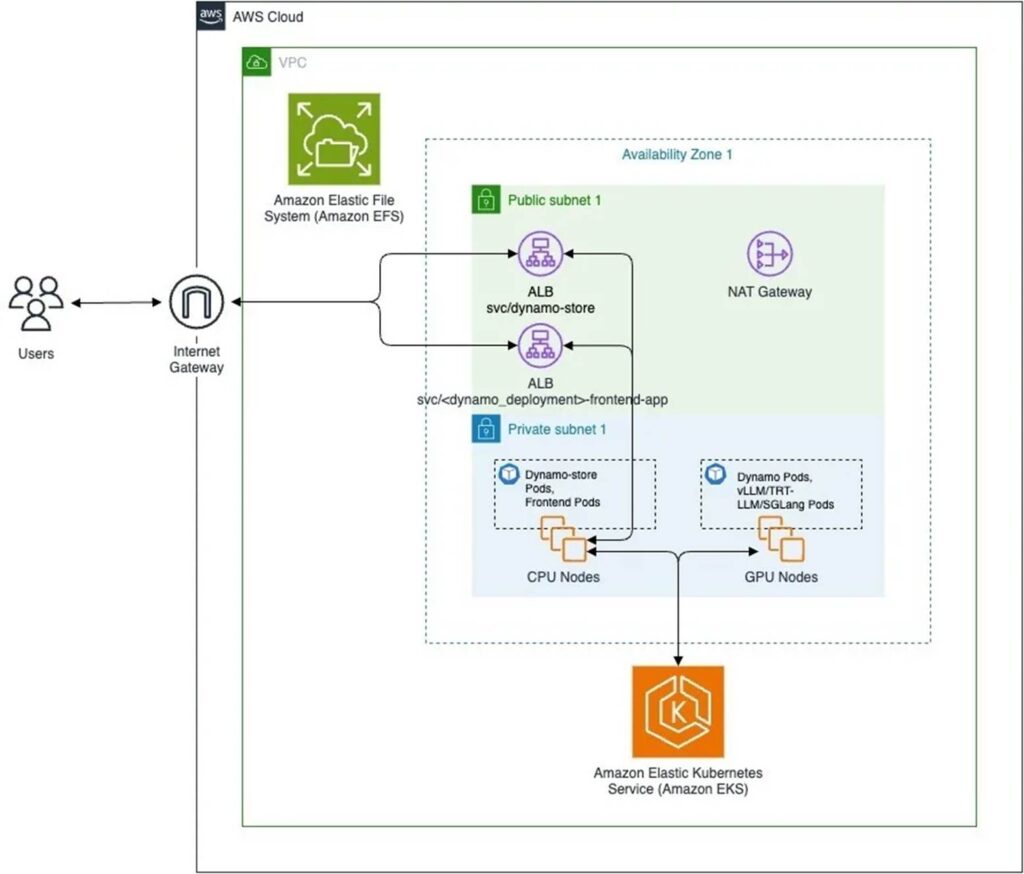
图 1:使用 Amazon EKS 的 AWS 部署架构上的 Dynamo
- AWS Elastic Fabric Adapter (EFA): Dynamo 的 NIXL 数据传输库支持 Amazon 的 EFA,这是一个在 Amazon EC2 实例之间提供低延迟节点间通信的网络接口。
随着 LLM 规模的扩大并采用稀疏混合专家模型架构,跨多个 GPU 进行分片可在保持低延迟的同时提高吞吐量。在这些部署中,针对在 AWS 上运行的工作负载,使用 EFA 跨 GPU 节点传输推理数据。借助 Dynamo 的 EFA 支持,开发者可以通过 NIXL 的前端 API 使用简单的 get、push 和 delete 命令,在节点之间轻松移动 KV 缓存。这样一来,无需自定义插件即可访问 Dynamo 的高级功能(如分离服务),加速 AI 应用的生产时间。
在 Blackwell 驱动的 Amazon P6 实例上使用 Dynamo 优化推理
Dynamo 与任何 NVIDIA GPU 加速的亚马逊云科技实例兼容,但与由 Blackwell 提供支持的 Amazon EC2 P6 实例搭配使用时,可显著提升部署 DeepSeek R1 和最新 Llama 4 等高级逻辑推理模型时的性能。Dynamo 通过管理预填充和解码自动缩放以及速率匹配等关键任务,简化并自动处理分离 MoE 模型的复杂部署流程。
同时,Amazon P6-B200 实例具有第五代 Tensor Core、FP4 加速和 2 倍于上一代的 NVIDIA NVLink 带宽,而由 NVIDIA GB200 NVL72 提供支持的 P6e-GB200 Ultra 服务器具有独特的扩展架构,可提供 130 TBps 的聚合全互联带宽,旨在加速混合专家模型 (MoE) 部署中广泛采用的专家并行解码操作所需的密集型通信模式。Dynamo 和 P6 驱动的 Blackwell 实例相结合,可提高 GPU 利用率,提高每美元的请求吞吐量,并推动生产级 AI 工作负载的利润可持续增长。
开始使用 NVIDIA Dynamo
深化 Dynamo 与亚马逊云科技的集成可帮助开发者无缝扩展其推理工作负载。
NVIDIA Dynamo 可在任何 NVIDIA GPU 加速的亚马逊云科技实例上运行。部署 NVIDIA Dynamo,即刻开始优化推理堆栈。


















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









