



2025年 10月 13日
By 郭凯瑞, 黄俊毓, 雷一鸣, 程迪, 申意 and 卢翔龙
在生产环境部署大模型推理服务时,技术团队往往会遇到诸多挑战,例如缺乏成熟的 PD 分离方案、自动扩缩容机制不够灵活、缺乏动态路由,以及难以实现多级分布式 KV 缓存的多级管理难以实现等。在实际工作中我们发现,通过利用 NVIDIA Dynamo 提供的一整套组件和功能,能够帮助团队很好的解决和应对这些问题。
简单介绍一下 NVIDIA Dynamo,它是由 NVIDIA 发布的一个开源、低延迟的模块化推理框架,用于在分布式环境中服务生成式 AI 模型。Dynamo 原生支持 NVIDIA TensorRT-LLM、vLLM、SGLang 三大主流推理引擎的 Agg/Disagg 实现。开发者无需担心框架适配的复杂性,只需在 Dynamo 生态中选择合适的后端,即可获得性能与功能的增强。当团队需并行维护多种框架时,Dynamo 提供的多引擎并行能力,既能帮助快速评估不同技术路线,也能让产品灵活匹配多样化的业务需求。
除了对三大引擎的支持,Dynamo 同时提供了 KV Cache Aware Router、KVBM (KV Block Manager)、NIXL 等特性,具体如下:
- KV Router 可以根据每个实例的 KV Cache 命中和负载情况,将请求路由到最合适的实例上,从而降低 TTFT;
- KVBM 提供 G1-G4 (GPU memory、CPU host memory、SSD、远端存储) 的 KV Cache 卸载,避免大量 KV Cache 重计算;
- 而 NIXL 支持 UCX 等后端,提供高效的 KV Cache 传输支持。
随着 Dynamo 0.4.0 的发布,新增的 AIConfigurator 这一新工具可根据用户的 SLO 和 可用 GPU 资源,自动推荐 prefill-decode 自动推荐合适的 PD 分离配置和并行策略,并生成一键部署的脚本,简化部署难题;而 SLO-based Planner 则可与 Kubernetes 联动,自动调节 Prefill 和 Decode worker 数量,确保性能与资源使用率达成最佳水平。
使用 Dynamo 部署
实际上在 Dynamo 发布之前,我们与 NVIDIA 的技术团队围绕 PD 分离已经进行了多次深入探讨和交流,在 2025 年 3 月下旬 Dynamo 正式发布后即开始部署,并于 2025 年 4 月正式开始使用。作为 Dynamo 开源初期的用户之一,我们在 72B 模型场景下取得了显著的性能提升并降低了成本。
我们使用 Dynamo 提供的 vLLM v0 workflow(Dynamo 目前原生支持 vLLM v1),将 原本采用 TP2 混合部署策略的 72B 模型,调整为 PD 分离部署,在业务场景的流量特点下(大部分为短上下文,少数为长上下文,最长达 32K),我们研究了其 P、D 并行策略及数量配比对系统整体吞吐的影响,最终采用了如下异构策略:
- P (Prefill):采用 TP1 高算力 GPU
- D (Decode):采用 TP2 高带宽 GPU
- P/D 配比:约 1 比 3
同时,利用了 Dynamo 提供的 KV Router 特性,提升请求间的 KV Cache 命中率。
最终的结果为:响应耗时减半的同时成本节约 50%。
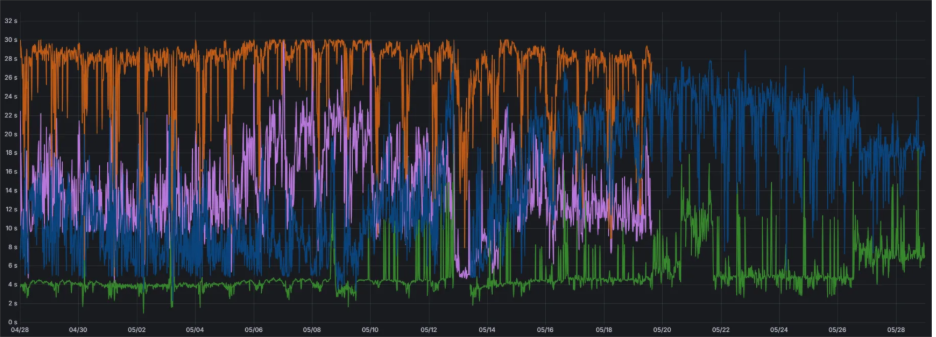
图片 1. Dynamo PD 分离与 TP2 PD 混合部署的推理效率对比 (横坐标: 时间, 纵坐标: 端到端响应耗时)
- 橙色:混合部署 P99
- 紫色:混合部署 P90
- 蓝色:PD 分离 P99
- 绿色:PD 分离 P90
在使用过程中,我们也为 Dynamo 提交了多个 Pull Requests,用于修复遇到的问题,或根据我们的经验提供一些改进:
- [nats related] https://github.com/ai-dynamo/dynamo/pull/1053 merged
- [etcd related] https://github.com/ai-dynamo/dynamo/pull/980 merged
- [nixl related] https://github.com/ai-dynamo/dynamo/pull/852 merged
- [llm examples related] https://github.com/ai-dynamo/dynamo/pull/855
- [llm examples related] https://github.com/ai-dynamo/dynamo/pull/853
基于 Dynamo 的改进
Dynamo 的开源发布 也推动了 vLLM 社区、SGLang 社区做出了很多积极的改进。比如,在 vLLM v1 引擎上添加了 KV Events、Metrics Events,集成了 NIXL Connector 等,这使得用户能够更方便地搭建专属的 PD 分离推理系统。
在上述 Dynamo vLLM v0 版本的基础上,我们也基于以上 API 实现了我们自己的 PD 分离系统:
- 保留了 Dynamo 的主要架构优势,如 KV Router、Conditional PD、NIXL 等
- 将 vLLM 升级到了 v1 engine
- 改进了 Prefill worker 的工作方式,以支持 Batch prefill,提升 Prefill GPU 利用率
- 基于我们的业务场景特色,优化了 KVRouter 的条件判断公式,加入了更多判断因子(如 running_requests、offload_score),使算力分配更均衡
- 基于开源社区的 LMCache 工具实现了 KVCache 的多级卸载,并且针对 LMCache 的读写效率进行了多项优化
- 实现了基于 HF3FS 的全局 KVCache 缓存池
- 针对远端缓存池读取慢的问题,提出了基于 Router 与 LMCache Cache Manager 直接协作的 Prefetch 机制,绕过推理引擎实现 KV Cache 的预加载
上述改进版本,在 4 月份 Dynamo v0 版本的基础上再次实现了 50% 的性能提升。同时基于 Dynamo + SGLang 实现了对 Deepseek V3 的分布式多机部署改造。感谢 Dynamo 以及 NIXL 项目为开源社区做出的贡献。
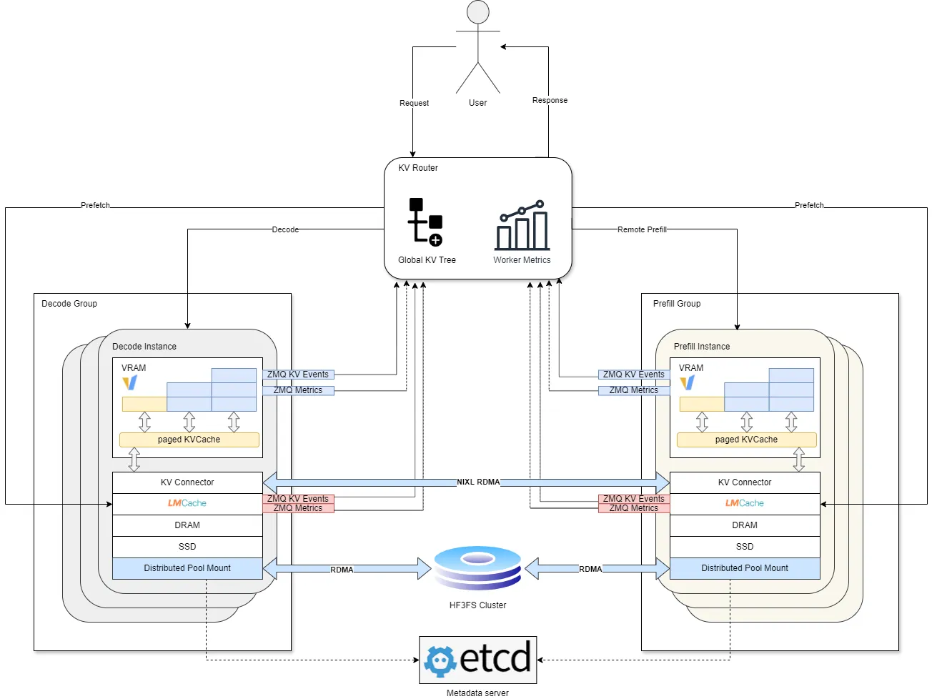
图片 2. 金山办公现有线上业务基于 Dynamo 的架构示意图
未来展望
未来,我们计划继续完善现有架构,包括支持更多的推理框架、支持更多类型的 KV 卸载池(如S3)、完善 DeepSeek 等超大模型场景下的相关功能。同时, 我们也将围绕新发布的 AIConfigurator 和 SLO-based Planner 等工具深入合作。我们也希望 Dynamo、NIXL 等项目可以继续在推理系统领域上引领社区共同进步,使更多用户能够快速地接入或在此基础上进行扩展,成为支撑下一代 AI 推理基础设施的核心引擎。



















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









