




☁️主页 Nowl
📑君子坐而论道,少年起而行之

文章目录
介绍
强化学习是机器学习中一种独特的存在,以其独特的思想逐渐发展为一门独立的学科,强化学习适用的场景是:一个学习主体根据环境做出不同的决策,得到相应的奖励与惩罚来改进决策
它既不是监督学习也不是无监督学习,从这段描述中也可以看出,它不适合用来进行回归或者聚类等任务
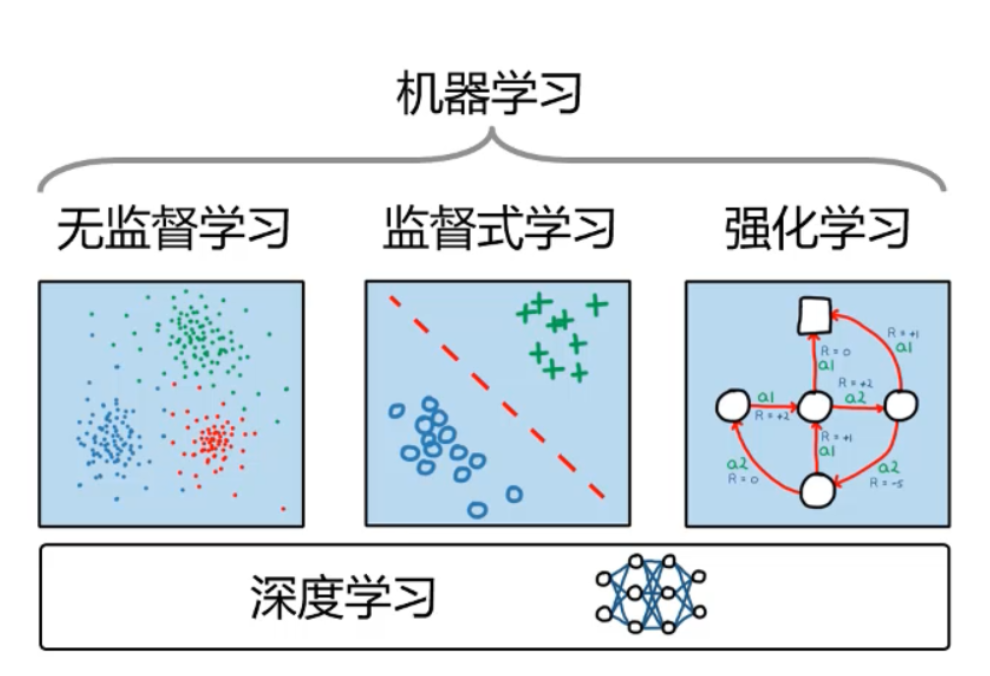
强化学习要素
强化学习中有一些重要的概念,我们接下来一一介绍他们,如果有些不理解不要着急,我们会举一个具体例子来解释
-
智能体:智能体是强化学习中的主体,它能够观测环境,做出决策,这些概念我们也将在之后说明
-
环境:环境是智能体所处的环境,能够根据智能体的状态变化给出反馈,使智能体改进策略
-
状态:即环境中智能体当前的状态
-
行动:智能体会根据当前状况做出行动
-
奖励:智能体每做出一次行动会得到一个奖励值,这也是一个导致智能体调整策略的因素
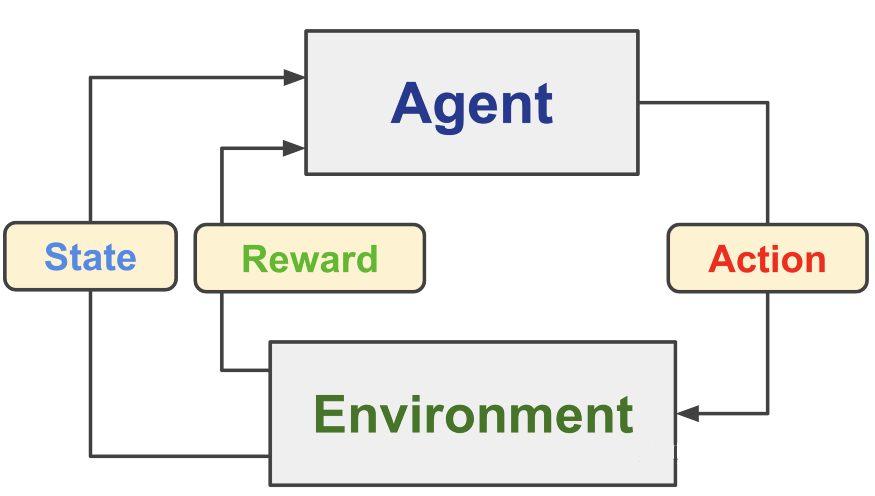
强化学习任务示例
环境搭建:gym
gym是一个集成了一些常用环境的库,我们可以通过调用这个环境库来快速入门强化学习,在python命令行中执行命令安装
!pip install gym[toy_text,classic_control,atari,accept-rom-license,other]基本用法
导入库后可以查看库中的所有环境和一些关于环境的说明
# 导入库
import gym
# 打印库中的所有环境和说明
print(gym.envs.registry)我们使用小车上山任务来进行后续教学
import gym
import matplotlib.pyplot as plt
# 选择小车上山环境,并设置渲染方式,之后我们可以获取环境的图像数组
env = gym.make('MountainCar-v0', render_mode="rgb_array")
# 初始化环境
env.reset()
# 获取环境图片数组
image = env.render()
#显示环境图片
plt.imshow(image)
plt.show()
这段代码完成了一些初始设置,具体作用见代码注释,运行结果如下图
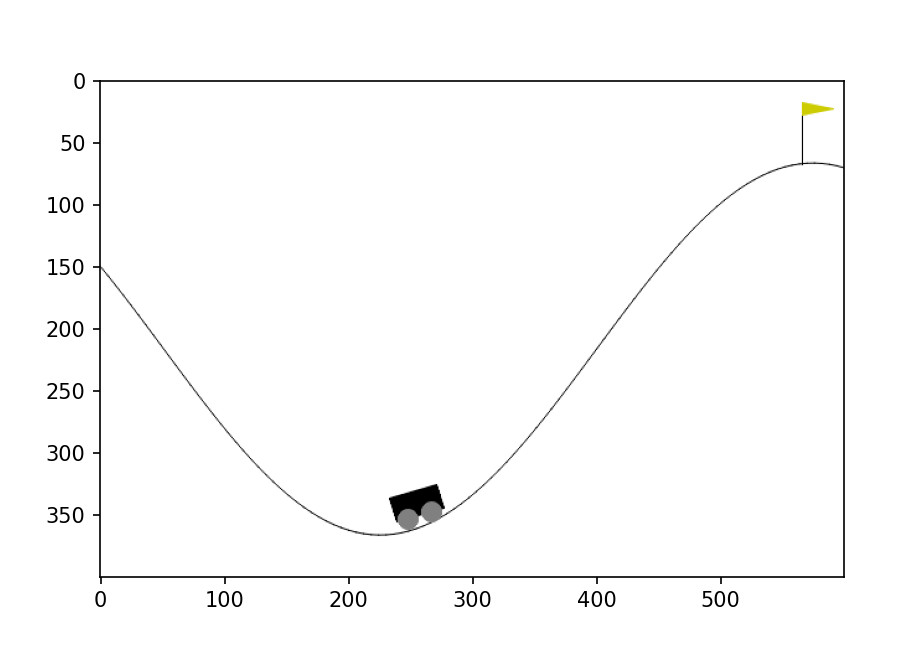
环境信息查看
我们导入环境后要查看一些环境的信息,还记得我们最开始说的强化学习要素吗,策略,行动等,我们要查看的就是这些
import gym
env = gym.make('MountainCar-v0', render_mode="rgb_array")
env.reset()
for key in vars(env.spec):
print(key, vars(env.spec)[key])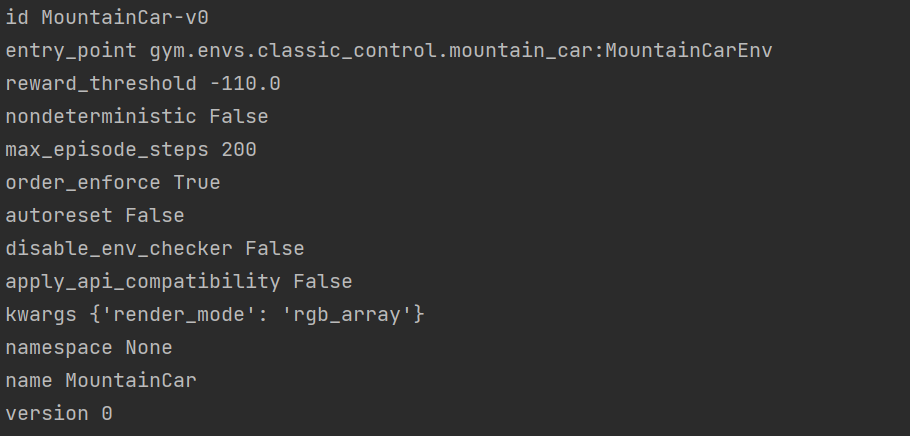
这段代码打印了一些环境的基础信息,我们解释一些重要的
id—代表当前环境的名称
reward_threshold—代表奖励阈值,即当奖励大于-110时就算任务成功
max_episode_steps—表示最大回合数,到达这个数时任务就算没完成也会停止
import gym
env = gym.make('MountainCar-v0', render_mode="rgb_array")
env.reset()
for key in vars(env.unwrapped):
print(key, vars(env.unwrapped)[key])这段代码会打印一些环境具体信息,由于结果太长,请读者自行打印,这里同样解释一些重要信息
min_position: -1.2: 车辆位置的最小值。
max_position: 0.6: 车辆位置的最大值。
max_speed: 0.07: 车辆速度的最大值。
goal_position: 0.5: 车辆成功达到的目标位置。
goal_velocity: 0: 车辆成功达到的目标速度。
force: 0.001: 施加在车辆上的力的大小。
gravity: 0.0025: 重力的大小。
low: [-1.2 -0.07]: 观察空间的最小值。
high: [0.6 0.07]: 观察空间的最大值。
action_space: Discrete(3): 动作空间,表示可用的离散动作数量为 3。
observation_space: Box([-1.2 -0.07], [0.6 0.07], (2,), float32): 观察空间,表示观察的状态空间是一个2维的Box空间,范围在 [-1.2, -0.07] 到 [0.6, 0.07] 之间。
创建智能体
接下来我们将使用类定义一个智能体
class CloseFormAgent:
def __init__(self):
pass
def step(self, observation):
position, velocity = observation
lb = min(-0.09*(position+0.25)**2+0.03, 0.3*(position+0.9)**4-0.008)
ub = -0.07*(position+0.38)**2+0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action这个类定义了一个step函数,代表智能体决策的部分,它输入一个观测环境,在这个任务中,可以观测到小车所处的位置和速度,接着,根据这两个值来做出行为,往右或者往左
我们再定义一个智能体与环境交互的函数
# 保存图片的列表
image = []
# 实例化智能体对象
agent = CloseFormAgent()
def play_episoe(env, agent, render=False):
# 获取初始化环境状态
observation, _ = env.reset()
# 初始化奖励,同时设置回合数和是否完成为False
reward, terminated, truncated = 0., False, False
# 初始化奖励与行动次数
episode_reward, elapsed_step = 0., 0
# 循环进行任务
while True:
# 获取决策
action = agent.step(observation)
# 保存当前状态图片(之后可视化要用到)
image.append(env.render())
# 如果到达了最大回合数或者完成任务就退出
if terminated or truncated:
break
# 记录做出行动后的数据
observation, reward, terminated, truncated, _ = env.step(action)
# 记录回合数与行动次数
episode_reward += reward
elapsed_step += 1
return episode_reward, elapsed_step这个函数实现了智能体与环境交互的过程,它接收行动,再返回状态,同时记录回合数,行动次数等信息,具体作用见代码注释
过程可视化
matplotlib库中有一个将图片组变成一组动画的库:FuncAnimation,我们保存每次智能体的状态图片后,用这个库就可以将整个过程显示出来了
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
image = []
# 创建一个空白的图形窗口
fig, ax = plt.subplots()
# 定义更新函数,用于在每一帧中更新图像
def update(frame):
ax.clear() # 清空当前图轴
ax.imshow(image[frame])
ax.set_title(f'Frame {frame+1}/{len(image)}')
# 创建动画对象
animation = FuncAnimation(fig, update, frames=len(image), repeat=False)
# 显示动画
plt.show()完整代码
import gym
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
env = gym.make('MountainCar-v0', render_mode="rgb_array")
env.reset()
image = []
class CloseFormAgent:
def __init__(self):
pass
def step(self, observation):
position, velocity = observation
lb = min(-0.09*(position+0.25)**2+0.03, 0.3*(position+0.9)**4-0.008)
ub = -0.07*(position+0.38)**2+0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action
agent = CloseFormAgent()
def play_episoe(env, agent, render=False):
observation, _ = env.reset()
reward, terminated, truncated = 0., False, False
episode_reward, elapsed_step = 0., 0
while True:
action = agent.step(observation)
image.append(env.render())
if terminated or truncated:
break
observation, reward, terminated, truncated, _ = env.step(action)
episode_reward += reward
elapsed_step += 1
return episode_reward, elapsed_step
episode_reward, elapsed_steps = play_episoe(env, agent, render=True)
env.close()
print("奖励:", episode_reward, "行动次数:", elapsed_steps)
# 创建一个空白的图形窗口
fig, ax = plt.subplots()
# 定义更新函数,用于在每一帧中更新图像
def update(frame):
ax.clear() # 清空当前图轴
ax.imshow(image[frame])
ax.set_title(f'Frame {frame+1}/{len(image)}')
# 创建动画对象
animation = FuncAnimation(fig, update, frames=len(image), repeat=False)
# 显示动画
plt.show()运行后代码将打印最终奖励与行动次数,以及显示一个智能体与环境交互的动画,效果如下
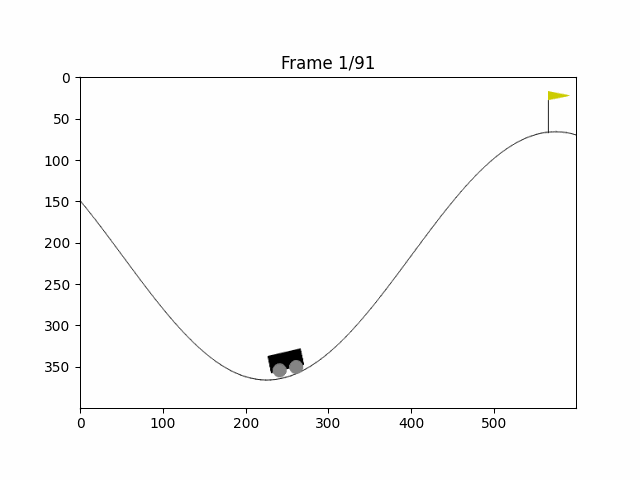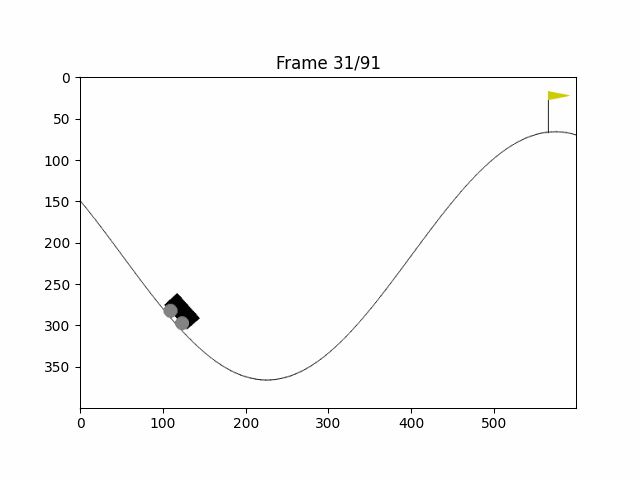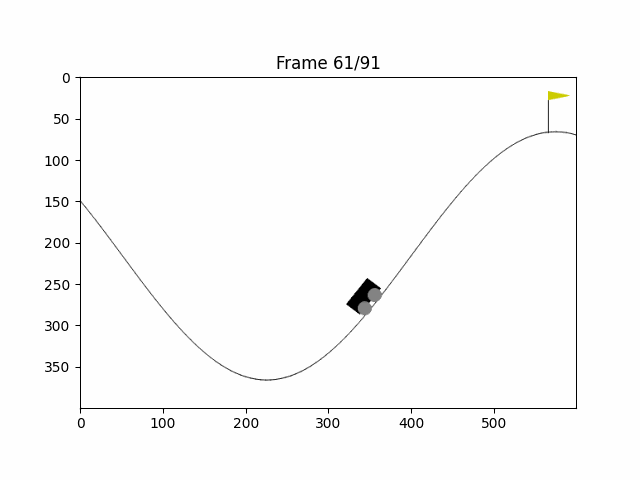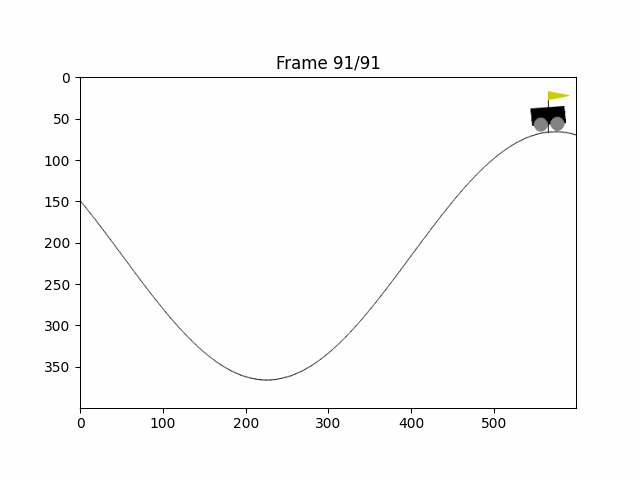
结语
- 了解了什么是强化学习
- 学习了强化学习的基本概念
- 通过一个简单示例直观感受了强化学习的基本流程
- 学习了将图片动画化的技术
感谢阅读,觉得有用的话就订阅下本专栏吧,有错误也欢迎指出


















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











