






OCR(Option Character Recognition) 技术,可以对图片文字进行识别。爬虫时,可以实现对常规验证码进行识别。
1、安装 tesserocr 库
安装说明参照同期公众号文章:OCR文字识别 之 Tesseract及tesserocr 安装说明
安装包下载地址:https://download.youkuaiyun.com/download/Mountain_tai_li/88222237
另外,还需用到的库有:Selenium、Pillow、NumPy等,根据自己开发环境库安装情况进行补充。
2、识别测试
将网站待识别的验证码图片保存至本地,通过如下代码进行测试:

import tesserocr
from PIL import Image
image = Image.open("test_ocr.png")
result = tesserocr.image_to_text(image, lang='chi_sim')
print(result)运行输出结果:
PERT.3、验证码处理
上面测试发现,输出结果与图片内容不完全一致,后面多了一个"."。所以,常规情况下,需要对验证码图片进行一些处理,排除干扰信息。
import tesserocr
from PIL import Image
import numpy as np
image = Image.open("ocr_test.png")
image = image.convert("L") # 转为灰度图像
array = np.array(image)
array = np.where(array > 150, 255, 0) # 转为二值图像
image = Image.fromarray(array.astype('uint8'))
image.show()
result = tesserocr.image_to_text(image)
print(result)处理后的图片为二值图像,如下:
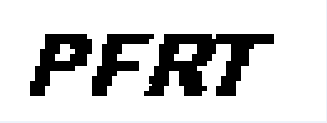
运行输出结果:
PERT后续公众号会发布系列教程,更多内容请关注公众号:程序猿学习日记


















 4842
4842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











