






6、提取父节点
如果知道子节点,可以通过".."选取父节点,使用方法如下:
from lxml import etree
html = etree.parse('xpath_sample.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/../@class')
print(result)运行输出结果:
['item-3']也可以通过 "parent::" 获取父节点,使用方法如下:
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')7、属性匹配
在选取节点的时候,可以使用"@属性" 进行属性过滤,使用方法如下:
from lxml import etree
html = etree.parse('xpath_sample.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-3"]')
print(result)运行输出如下:
[<Element li at 0x1da1e7a9ec8>]8、文本获取
from lxml import etree
html = etree.parse('xpath_sample.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-3"]/a/text()')
print(result)运行输出如下:
['Item-3']9、属性获取
中括号加属性名和值"[@href="link3.html"]"可以进行限定来进行属性匹配,而直接"@属性" 可以获取节点的属性值,使用方法如下:
from lxml import etree
html = etree.parse('xpath_sample.html', etree.HTMLParser())
results = html.xpath('//li/a/@href')
for result in results:
print(result)运行输出结果如下:
link1.html
link2.html
link3.html
link4.html
link5.html10、属性多值匹配
有时,HTML 节点的属性具有多个值,此时需要对节点匹配,可以使用 contains 方法,如下:
from lxml import etree
text = '''
<div class="main main-left"><a href="left_bar.html">Left Bar</a><div>
'''
html = etree.HTML(text)
results = html.xpath('//div[contains(@class, "main")]/a/text()')
for result in results:
print(result)运行输出结果如下:
Left Bar11、多属性匹配
有时,HTML 节点具有多个属性,此时需要对节点匹配,可以使用 运算符 and 连接多个属性进行匹配,使用如下:
from lxml import etree
text = '''
<div class="main main-left" name="left-menu"><a href="left_bar.html">Left Bar</a><div>
'''
html = etree.HTML(text)
results = html.xpath('//div[contains(@class, "main") and @name="left-menu"]/a/text()')
for result in results:
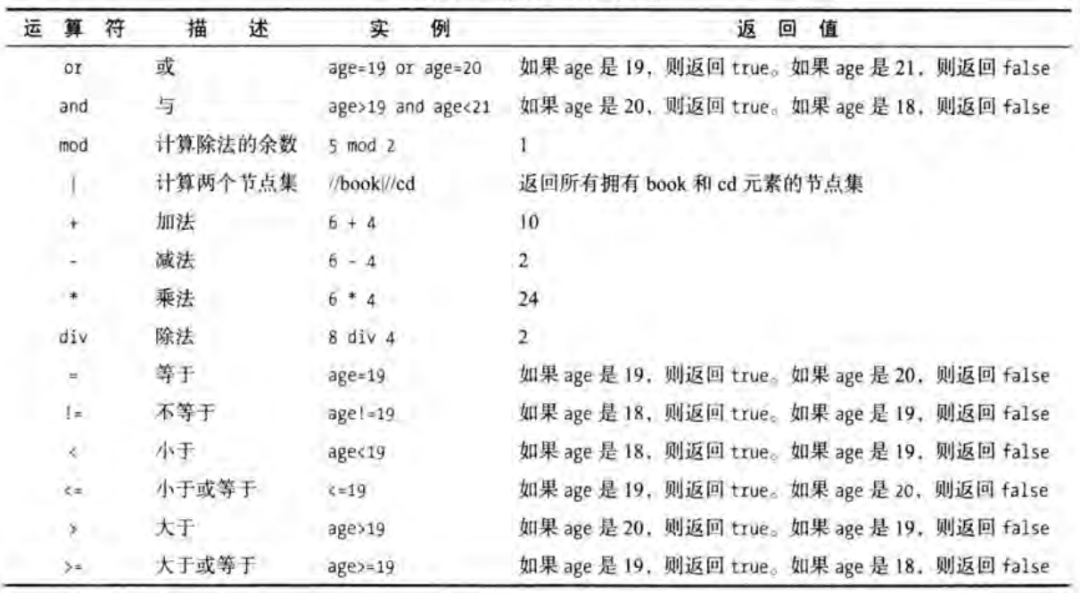
print(result)运算符及其介绍如下:
后续公众号会发布系列教程,更多内容请关注公众号:程序猿学习日记


















 2190
2190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











