









文章目录
DUT的基本功能:采集输入端口的RX和RX_EN,打一拍后输出到TX和TX_EN。
2.3.1、加入transaction
在2.2节中, 所有的操作都是基于信号级的。 从本节开始将引入reference model、 monitor、 scoreboard等验证平台的其他组件。在这些组件之间, 信息的传递是基于transaction的, 因此, 本节将先引入transaction的概念。
transaction是一个抽象的概念。 一般来说, 物理协议中的数据交换都是以帧或者包为单位的, 通常在一帧或者一个包中要定义好各项参数, 每个包的大小不一样。 很少会有协议是以bit或者byte为单位来进行数据交换的。 以以太网为例, 每个包的大小至少是64byte。 这个包中要包括源地址、 目的地址、 包的类型、 整个包的CRC校验数据等。 transaction就是用于模拟这种实际情况, 一笔transaction就是一个包。 在不同的验证平台中, 会有不同的transaction。 一个简单的transaction的定义如下:
代码清单 2-23
文件: src/ch2/section2.3/2.3.1/my_transaction.sv
`ifndef MY_TRANSACTION__SV
`define MY_TRANSACTION__SV
class my_transaction extends uvm_sequence_item;
rand bit[47:0] dmac;
rand bit[47:0] smac;
rand bit[15:0] ether_type;
rand byte pload[];
rand bit[31:0] crc;
constraint pload_cons{
pload.size >= 46;
pload.size <= 1500;
}
function bit[31:0] calc_crc();
return 32'h0;
endfunction
function void post_randomize();
crc = calc_crc;
endfunction
`uvm_object_utils(my_transaction)
function new(string name = "my_transaction");
super.new();
endfunction
endclass
`endif
其中dmac是48bit的以太网目的地址, smac是48bit的以太网源地址, ether_type是以太网类型, pload是其携带数据的大小, 通过pload_cons约束可以看到, 其大小被限制在46~1500byte, CRC是前面所有数据的校验值。 由于CRC的计算方法稍显复杂, 且其代码在网络上随处可见, 因此这里只是在post_randomize中加了一个空函数calc_crc, 有兴趣的读者可以将其补充完整。
post_randomize是SystemVerilog中提供的一个函数, 当某个类的实例的randomize函数被调用后, post_randomize会紧随其后无条件地被调用。
在transaction定义中, 有两点值得引起注意:
- 一是my_transaction的基类是
uvm_sequence_item。 在UVM中, 所有的transaction都要从uvm_sequence_item派生, 只有从uvm_sequence_item派生的transaction才可以使用后文讲述的UVM中强大的sequence机制。 - 二是这里没有使用uvm_component_utils宏来实现factory机制, 而是使用了uvm_object_utils。 从本质上来说, my_transaction与my_driver是有区别的, 在整个仿真期间, my_driver是一直存在的, my_transaction不同, 它有生命周期。 它在仿真的某一时间产生, 经过driver驱动, 再经过reference model处理, 最终由scoreboard比较完成后, 其生命周期就结束了。 一般来说, 这种类都是派生自uvm_object或者uvm_object的派生类, uvm_sequence_item的祖先就是uvm_object。 UVM中具有这种特征的类都要使用uvm_object_utils宏来实现。
当完成transaction的定义后, 就可以在my_driver中实现基于transaction的驱动:
代码清单 2-24
文件: src/ch2/section2.3/2.3.1/my_driver.sv
`ifndef MY_DRIVER__SV
`define MY_DRIVER__SV
class my_driver extends uvm_driver;
virtual my_if vif;
`uvm_component_utils(my_driver)
function new(string name = "my_driver", uvm_component parent = null);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(!uvm_config_db#(virtual my_if)::get(this, "", "vif", vif))
`uvm_fatal("my_driver", "virtual interface must be set for vif!!!")
endfunction
extern task main_phase(uvm_phase phase);
extern task drive_one_pkt(my_transaction tr);
endclass
task my_driver::main_phase(uvm_phase phase);
my_transaction tr;
phase.raise_objection(this);
vif.data <= 8'b0;
vif.valid <= 1'b0;
while(!vif.rst_n)
@(posedge vif.clk);
for(int i = 0; i < 2; i++) begin
tr = new("tr");
assert(tr.randomize() with {pload.size == 200;});
drive_one_pkt(tr);
end
repeat(5) @(posedge vif.clk);
phase.drop_objection(this);
endtask
task my_driver::drive_one_pkt(my_transaction tr);
bit [47:0] tmp_data;
bit [7:0] data_q[$];
//push dmac to data_q
tmp_data = tr.dmac;
for(int i = 0; i < 6; i++) begin
data_q.push_back(tmp_data[7:0]);
tmp_data = (tmp_data >> 8);
end
//push smac to data_q
tmp_data = tr.smac;
for(int i = 0; i < 6; i++) begin
data_q.push_back(tmp_data[7:0]);
tmp_data = (tmp_data >> 8);
end
//push ether_type to data_q
tmp_data = tr.ether_type;
for(int i = 0; i < 2; i++) begin
data_q.push_back(tmp_data[7:0]);
tmp_data = (tmp_data >> 8);
end
//push payload to data_q
for(int i = 0; i < tr.pload.size; i++) begin
data_q.push_back(tr.pload[i]);
end
//push crc to data_q
tmp_data = tr.crc;
for(int i = 0; i < 4; i++) begin
data_q.push_back(tmp_data[7:0]);
tmp_data = (tmp_data >> 8);
end
`uvm_info("my_driver", "begin to drive one pkt", UVM_LOW);
repeat(3) @(posedge vif.clk);
while(data_q.size() > 0) begin
@(posedge vif.clk);
vif.valid <= 1'b1;
vif.data <= data_q.pop_front();
end
@(posedge vif.clk);
vif.valid <= 1'b0;
`uvm_info("my_driver", "end drive one pkt", UVM_LOW);
endtask
`endif
在main_phase中, 先使用randomize将tr随机化, 之后通过drive_one_pkt任务将tr的内容驱动到DUT的端口上。 在drive_one_pkt中, 先将tr中所有的数据压入队列data_q中, 之后再将data_q中所有的数据弹出并驱动。 将tr中的数据压入队列data_q中的过程相当于打包成一个byte流的过程。 这个过程还可以使用SystemVerlog提供的流操作符实现。 具体请参照SystemVerilog语言标准IEEE Std1800 TM—2012( IEEE Standard for SystemVerilog—Unified Hardware Design, Specification, and Verification Language) 的11.4.14节。
流操作符的实现数据解包方法
将代码清单2-24的43-70行,替换为如下几行代码:
bit [7:0] data_q1[$];
bit [7:0] data_q2[$];
bit [7:0] data_q3[$];
bit [7:0] data_q4[$];
bit [7:0] data_q5[$];
//流操作符
data_q1 = {<<8{tr.dmac}};
data_q2 = {<<8{tr.smac}};
data_q3 = {<<8{tr.ether_type}};
data_q4 = {<<8{tr.pload}};
data_q5 = {<<8{tr.crc}};
data_q = {data_q1, data_q2, data_q3, data_q4, data_q5};
2.3.2、加入env
在验证平台中加入reference model、 scoreboard等之前, 思考一个问题: 假设这些组件已经定义好了, 那么在验证平台的什么位置对它们进行实例化呢? 在top_tb中使用run_test进行实例化显然是不行的, 因为run_test函数虽然强大, 但也只能实例化一个实例; 如果在top_tb中使用2.2.1节中实例化driver的方式显然也不可行, 因为run_test相当于在top_tb结构层次之外建立一个新的结构层次, 而2.2.1节的方式则是基于top_tb的层次结构, 如果基于此进行实例化, 那么run_test的引用也就没有太大的意义了; 如果在driver中进行实例化则更加不合理。
这个问题的解决方案是引入一个容器类, 在这个容器类中实例化driver、 monitor、 reference model和scoreboard等。 在调用run_test时, 传递的参数不再是my_driver, 而是这个容器类, 即让UVM自动创建这个容器类的实例。 在UVM中, 这个容器类称为uvm_env:
代码清单 2-25
文件: src/ch2/section2.3/2.3.2/my_env.sv
`ifndef MY_ENV__SV
`define MY_ENV__SV
class my_env extends uvm_env;
my_driver drv;
function new(string name = "my_env", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
drv = my_driver::type_id::create("drv", this);
endfunction
`uvm_component_utils(my_env)
endclass
`endif
所有的env应该派生自uvm_env, 且与my_driver一样, 容器类在仿真中也是一直存在的, 使用uvm_component_utils宏来实现factory的注册。
在my_env的定义中, 最让人难以理解的是第14行drv的实例化。 这里没有直接调用my_driver的new函数, 而是使用了一种古怪的方式。 这种方式就是factory机制带来的独特的实例化方式。 只有使用factory机制注册过的类才能使用这种方式实例化; 只有使用这种方式实例化的实例, 才能使用后文要讲述的factory机制中最为强大的重载功能。 验证平台中的组件在实例化时都应该使用type_name::type_id::create的方式。
在drv实例化时, 传递了两个参数, 一个是名字drv, 另外一个是this指针, 表示my_env。 回顾一下my_driver的new函数:
代码清单 2-26
function new(string name = "my_driver", uvm_component parent = null);
super.new(name, parent);
endfuncti
这个new函数有两个参数, 第一个参数是实例的名字, 第二个则是parent。 由于my_driver在uvm_env中实例化, 所以my_driver的父结点( parent) 就是my_env。 通过parent的形式, UVM建立起了树形的组织结构。 在这种树形的组织结构中, 由run_test创建的实例是树根( 这里是my_env) , 并且树根的名字是固定的, 为uvm_test_top, 这在前文中已经讲述过; 在树根之后会生长出枝叶( 这里只有my_driver) , 长出枝叶的过程需要在my_env的build_phase中手动实现。 无论是树根还是树叶, 都必须由uvm_component或者其派生类继承而来。 整棵UVM树的结构如图2-3所示。
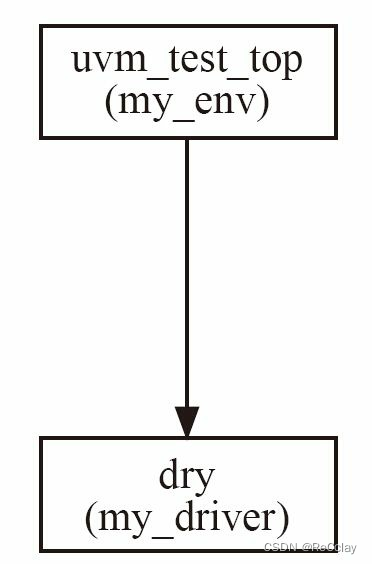
图2-3 UVM树的生长: 加入env
当加入了my_env后, 整个验证平台中存在两个build_phase, 一个是my_env的, 一个是my_driver的。 那么这两个build_phase按照何种顺序执行呢? 在UVM的树形结构中, build_phase的执行遵照从树根到树叶的顺序, 即先执行my_env的build_phase, 再执行my_driver的build_phase。 当把整棵树的build_phase都执行完毕后, 再执行后面的phase。
my_driver在验证平台中的层次结构发生了变化, 它一跃从树根变成了树叶, 所以在top_tb中使用config_db机制传递virtual my_if时, 要改变相应的路径; 同时, run_test的参数也从my_driver变为了my_env:
代码清单 2-27
文件: src/ch2/section2.3/2.3.2/top_tb.sv
...
initial begin
run_test("my_env");
end
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.drv", "vif", input_if);
end
...
set函数的第二个参数从uvm_test_top变为了uvm_test_top.drv, 其中uvm_test_top是UVM自动创建的树根的名字, 而drv则是在my_env的build_phase中实例化drv时传递过去的名字。 如果在实例化drv时传递的名字是my_drv, 那么set函数的第二个参数中也应该是my_drv:
代码清单 2-28
class my_env extends uvm_env
...
drv = my_driver::type_id::create("my_drv", this);
...
endclass
module top_tb;
...
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.my_drv", "vif", inpu t_if);
end
endmodule
2.3.3、加入monitor
验证平台必须监测DUT的行为, 只有知道DUT的输入输出信号变化之后, 才能根据这些信号变化来判定DUT的行为是否正确。
验证平台中实现监测DUT行为的组件是monitor。 driver负责把transaction级别的数据转变成DUT的端口级别, 并驱动给DUT,monitor的行为与其相对, 用于收集DUT的端口数据, 并将其转换成transaction交给后续的组件如reference model、 scoreboard等处理。
一个monitor的定义如下:
代码清单 2-29
文件: src/ch2/section2.3/2.3.3/my_monitor.sv
`ifndef MY_MONITOR__SV
`define MY_MONITOR__SV
class my_monitor extends uvm_monitor;
virtual my_if vif;
`uvm_component_utils(my_monitor)
function new(string name = "my_monitor", uvm_component parent = null);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(!uvm_config_db#(virtual my_if)::get(this, "", "vif", vif))
`uvm_fatal("my_monitor", "virtual interface must be set for vif!!!")
endfunction
extern task main_phase(uvm_phase phase);
extern task collect_one_pkt(my_transaction tr);
endclass
task my_monitor::main_phase(uvm_phase phase);
my_transaction tr;
while(1) begin
tr = new("tr");
collect_one_pkt(tr);
end
endtask
task my_monitor::collect_one_pkt(my_transaction tr);
bit[7:0] data_q[$];
int psize;
while(1) begin
@(posedge vif.clk);
if(vif.valid) break;
end
`uvm_info("my_monitor", "begin to collect one pkt", UVM_LOW);
while(vif.valid) begin
data_q.push_back(vif.data);
@(posedge vif.clk);
end
//pop dmac
for(int i = 0; i < 6; i++) begin
tr.dmac = {tr.dmac[39:0], data_q.pop_front()};
end
//pop smac
for(int i = 0; i < 6; i++) begin
tr.smac = {tr.smac[39:0], data_q.pop_front()};
end
//pop ether_type
for(int i = 0; i < 2; i++) begin
tr.ether_type = {tr.ether_type[7:0], data_q.pop_front()};
end
psize = data_q.size() - 4;
tr.pload = new[psize];
//pop payload
for(int i = 0; i < psize; i++) begin
tr.pload[i] = data_q.pop_front();
end
//pop crc
for(int i = 0; i < 4; i++) begin
tr.crc = {tr.crc[23:0], data_q.pop_front()};
end
`uvm_info("my_monitor", "end collect one pkt, print it:", UVM_LOW);
tr.my_print();
endtask
`endif
有几点需要注意的是:
- 第一, 所有的monitor类应该派生自
uvm_monitor; - 第二, 与driver类似, 在my_monitor中也需要有一个
virtual my_if; - 第三, uvm_monitor在整个仿真中是一直存在的, 所以它是一个component, 要使用uvm_component_utils宏注册;
- 第四, 由于monitor需要时刻收集数据, 永不停歇, 所以在main_phase中使用
while(1)循环来实现这一目的。
在查阅collect_one_pkt的代码时, 可以与my_driver的drv_one_pkt对比来看, 两者代码非常相似。 当收集完一个transaction后,通过my_print函数将其打印出来。 my_print在my_transaction中定义如下:
代码清单 2-30
文件: src/ch2/section2.3/2.3.3/my_transaction.sv
function void my_print();
$display("dmac = %0h", dmac);
$display("smac = %0h", smac);
$display("ether_type = %0h", ether_type);
for(int i = 0; i < pload.size; i++) begin
$display("pload[%0d] = %0h", i, pload[i]);
end
$display("crc = %0h", crc);
endfunction
当完成monitor的定义后, 可以在env中对其进行实例化:
代码清单 2-31
文件: src/ch2/section2.3/2.3.3/my_env.sv
class my_env extends uvm_env;
my_driver drv;
my_monitor i_mon;
my_monitor o_mon;
function new(string name = "my_env", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
drv = my_driver::type_id::create("drv", this);
i_mon = my_monitor::type_id::create("i_mon", this);
o_mon = my_monitor::type_id::create("o_mon", this);
endfunction
`uvm_component_utils(my_env)
endclass
需要引起注意的是这里实例化了两个monitor, 一个用于监测DUT的输入口, 一个用于监测DUT的输出口。 DUT的输出口设置一个monitor没有任何疑问, 但是在DUT的输入口设置一个monitor有必要吗? 由于transaction是由driver产生并输出到DUT的端口上, 所以driver可以直接将其交给后面的reference model。 在2.1节所示的框图中, 也是使用这样的策略。 所以是否使用monitor, 这个答案仁者见仁, 智者见智。
这里还是推荐使用monitor, 原因是:
- 第一, 在一个大型的项目中, driver根据某一协议发送数据, 而monitor根据这种协议收集数据, 如果driver和monitor由不同人员实现, 那么可以大大减少其中任何一方对协议理解的错误;
- 第二, 在后文将会看到, 在实现代码重用时, 使用monitor是非常有必要的。现在, 整棵UVM树的结构如图2-4所示。
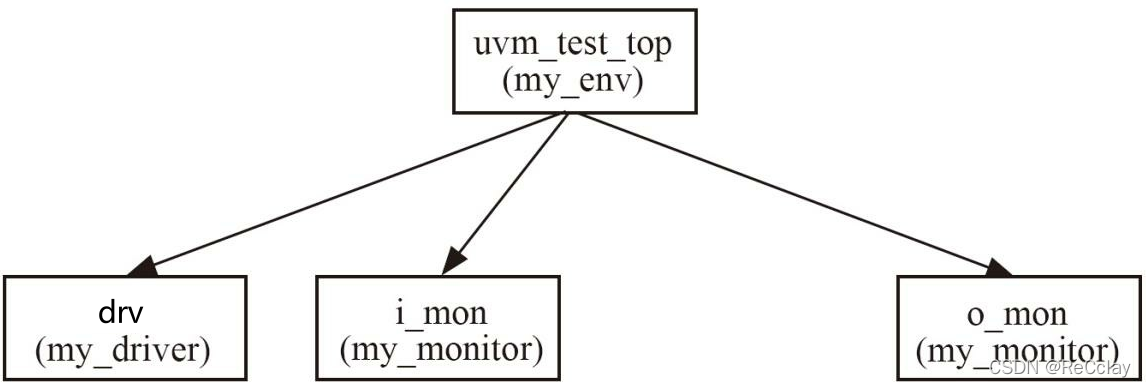
图2-4 UVM树的生长: 加入monitor
在env中实例化monitor后, 要在top_tb中使用config_db将input_if和output_if传递给两个monitor:
代码清单 2-32
文件: src/ch2/section2.3/2.3.3/top_tb.sv
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.drv", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.i_mon", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.o_mon", "vif", output_if);
end
修正原书monitor数据的拼包错误
原书中的monitor数据拼包主要错在了移位上。
搞清楚这个问题,先来回顾下数据解包方式:transaction分为5个数据,依次为48bit的dmac、48bit的smac、16bit的ether_type、动态数组pload、32bit的crc。在driver发包时,每次只能发送8bit。driver选择是按照顺序依次发送这5个数据:dmac -> smac -> ehter_type -> pload -> crc,对于每个数据是从低位开始,8bit为一个整体发送的。
但数据在monitor拼包时,原书程序是先将实时采集到的8bit数据,先push_back到了一个队列中,然后通过pop_front弹出数据,然后向左移位的方式放到各个数据中(dmac/smac/ehter_type/pload/crc)。但是注意,dmac的低八位最先通过push_back压入队列,所以pop_front最先弹出的是dmac的低八位。这个低八位也应该放到monitor拼包后的低八位。但原书中的tr.dmac = {tr.dmac[39:0], data_q.pop_front()};写法是将它放到了dmac的高八位处,显然是不对的,我们也可以从打印结果看到这一点,如下图:

正确的学法是: tr.dmac = {data_q.pop_front(), tr.dmac[47:8]};,打印结果如下图:

UVM_INFO my_driver.sv(33) @ 1100000: uvm_test_top.drv [my_driver_data] tr.dmac = d19a334456b0, tr.smac = fa4a5778d7f9, tr.ether_type = 7063, tr.crc = 0
UVM_INFO my_driver.sv(33) @ 45300000: uvm_test_top.drv [my_driver_data] tr.dmac = d39113885dfc, tr.smac = eb94d9eb3e9b, tr.ether_type = 6cb6, tr.crc = 0
UVM_INFO my_monitor.sv(85) @ 45500000: uvm_test_top.i_mon [my_monitor_data] tr.dmac = d19a334456b0, tr.smac = fa4a5778d7f9, tr.ether_type = 7063, tr.crc = 0
UVM_INFO my_monitor.sv(85) @ 45700000: uvm_test_top.o_mon [my_monitor_data] tr.dmac = d19a334456b0, tr.smac = fa4a5778d7f9, tr.ether_type = 7063, tr.crc = 0
UVM_INFO my_monitor.sv(85) @ 89700000: uvm_test_top.i_mon [my_monitor_data] tr.dmac = d39113885dfc, tr.smac = eb94d9eb3e9b, tr.ether_type = 6cb6, tr.crc = 0
UVM_INFO my_monitor.sv(85) @ 89900000: uvm_test_top.o_mon [my_monitor_data] tr.dmac = d39113885dfc, tr.smac = eb94d9eb3e9b, tr.ether_type = 6cb6, tr.crc = 0
更改完毕后的核心程序如下:
for(int i = 0; i < 6; i++) begin
tr.dmac = {data_q.pop_front(), tr.dmac[47:8]}; //这种写法相当于把低八位放到了低八位(右移),顺序是对的
end
//pop smac
for(int i = 0; i < 6; i++) begin
tr.smac = {data_q.pop_front(), tr.smac[47:8]};
end
//pop ether_type
for(int i = 0; i < 2; i++) begin
tr.ether_type = {data_q.pop_front(), tr.ether_type[15:8]};
end
psize = data_q.size() - 4;
tr.pload = new[psize];
//pop payload
for(int i = 0; i < psize; i++) begin
tr.pload[i] = data_q.pop_front();
end
//pop crc
for(int i = 0; i < 4; i++) begin
tr.crc = {data_q.pop_front(), tr.crc[31:8]};
end
分析完这个问题,我们稍稍在修正后的打印信息上再做一点探究,为什么会有两个monitor拼包后的数据?以及为什么两者相差一拍?
数据全览如下图,可以看到发送了两帧数据:
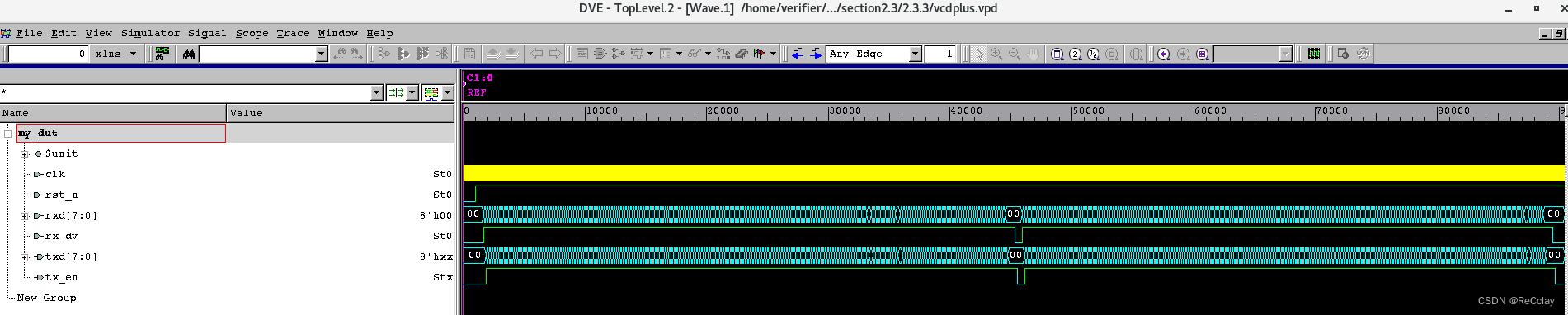
在第一帧和第二帧中间位置处放大,可以看到在UVM_INFO my_monitor.sv(85) @ 45500000: uvm_test_top.i_mon [my_monitor_data] tr.dmac = d19a334456b0, tr.smac = fa4a5778d7f9, tr.ether_type = 7063, tr.crc = 0的打印时间处,是rx_en刚刚拉低了一个时钟周期后的上升沿处,此处是i_monitor采集到的输入接口数据。
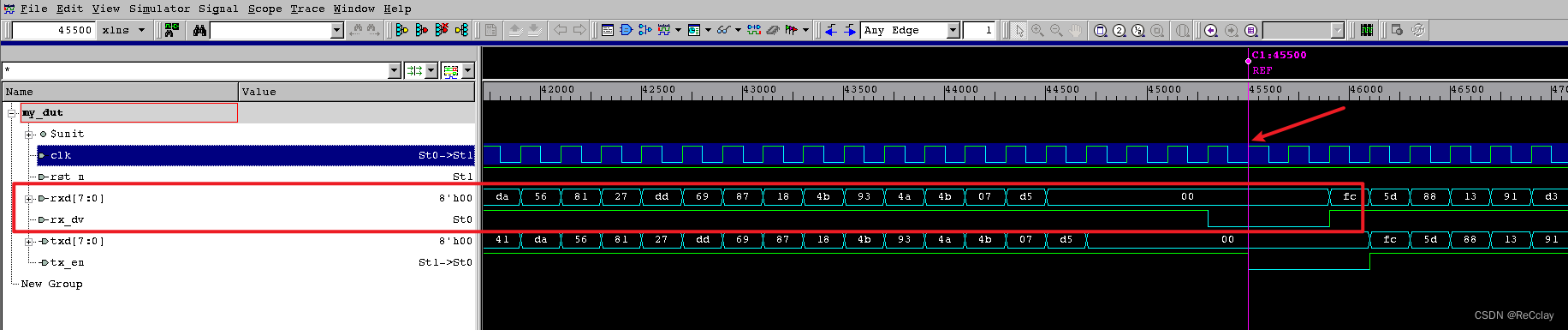
而在UVM_INFO my_monitor.sv(85) @ 45700000: uvm_test_top.o_mon [my_monitor_data] tr.dmac = d19a334456b0, tr.smac = fa4a5778d7f9, tr.ether_type = 7063, tr.crc = 0打印时间处,是dx_en刚刚拉低一个时钟周期后的上升沿处,o_monitor采集到的输出接口数据。
这两个数据自然都是第一帧driver发送的数据,只是时序上差了一拍!
温馨提示:调试建议使用uvm_info,如:
uvm_info("my_monitor_data", $sformatf("tr.dmac = %0h, tr.smac = %0h, tr.ether_type = %0h, tr.crc = %0h", tr.dmac, tr.smac, tr.ether_type, tr.crc), UVM_NONE);(别忘了uvm_info加前面的点)uvm_info("my_driver_data", $sformatf("tr.dmac = %0h, tr.smac = %0h, tr.ether_type = %0h, tr.crc = %0h", tr.dmac, tr.smac, tr.ether_type, tr.crc), UVM_NONE);(别忘了uvm_info加前面的点)
2.3.4、封装成agent
上一节在验证平台中加入monitor时, 读者看到了driver和monitor之间的联系: 两者之间的代码高度相似。 其本质是因为二者处理的是同一种协议, 在同样一套既定的规则下做着不同的事情。 由于二者的这种相似性, UVM中通常将二者封装在一起, 成为一个agent。 因此, 不同的agent就代表了不同的协议。
代码清单 2-33
文件: src/ch2/section2.3/2.3.4/my_agent.sv
`ifndef MY_AGENT__SV
`define MY_AGENT__SV
class my_agent extends uvm_agent ;
my_driver drv;
my_monitor mon;
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
extern virtual function void build_phase(uvm_phase phase);
extern virtual function void connect_phase(uvm_phase phase);
`uvm_component_utils(my_agent)
endclass
function void my_agent::build_phase(uvm_phase phase);
super.build_phase(phase);
if (is_active == UVM_ACTIVE) begin
drv = my_driver::type_id::create("drv", this);
end
mon = my_monitor::type_id::create("mon", this);
endfunction
function void my_agent::connect_phase(uvm_phase phase);
super.connect_phase(phase);
endfunction
`endif
所有的agent都要派生自uvm_agent类, 且其本身是一个component, 应该使用uvm_component_utils宏来实现factory注册。
这里最令人困惑的可能是build_phase中为何根据is_active这个变量的值来决定是否创建driver的实例。 is_active是uvm_agent的一个成员变量, 从UVM的源代码中可以找到它的原型如下:
代码清单 2-34
来源: UVM 源代码
uvm_active_passive_enum is_active = UVM_ACTIVE;
而uvm_active_passive_enum是一个枚举类型变量, 其定义为:
代码清单 2-35
来源: UVM 源代码
typedef enum bit { UVM_PASSIVE=0, UVM_ACTIVE=1 } uvm_active_passive_enum;
这个枚举变量仅有两个值: UVM_PASSIVE和UVM_ACTIVE。 在uvm_agent中, is_active的值默认为UVM_ACTIVE, 在这种模式下, 是需要实例化driver的。 那么什么是UVM_PASSIVE模式呢? 以本章的DUT为例, 如图2-5所示, 在输出端口上不需要驱动任何信号, 只需要监测信号。 在这种情况下, 端口上是只需要monitor的, 所以driver可以不用实例化。
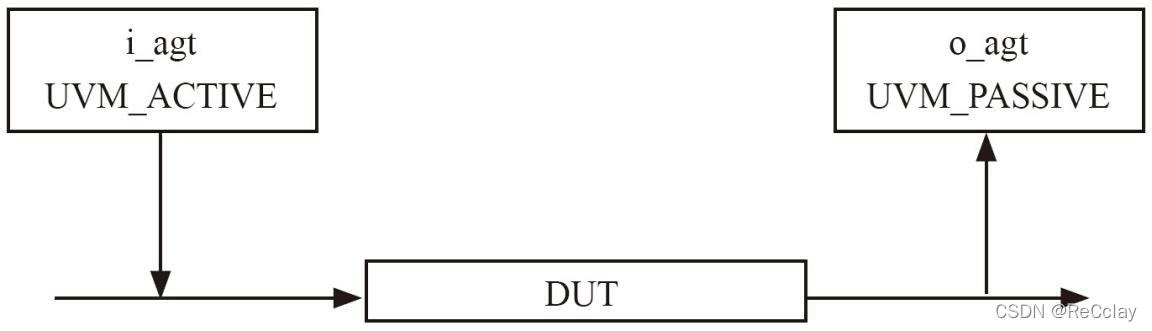
图2-5 DUT输入和输出端的agent
在把driver和monitor封装成agent后, 在env中需要实例化agent, 而不需要直接实例化driver和monitor了:
代码清单 2-36
文件: src/ch2/section2.3/2.3.4/my_env.sv
...
class my_env extends uvm_env;
my_agent i_agt;
my_agent o_agt;
function new(string name = "my_env", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
i_agt = my_agent::type_id::create("i_agt", this);
o_agt = my_agent::type_id::create("o_agt", this);
i_agt.is_active = UVM_ACTIVE;
o_agt.is_active = UVM_PASSIVE;
endfunction
`uvm_component_utils(my_env)
endclass
...
完成i_agt和o_agt的声明后, 在my_env的build_phase中对它们进行实例化后, 需要指定各自的工作模式是active模式还是passive模式。 现在, 整棵UVM树变为了如图2-6所示形式。
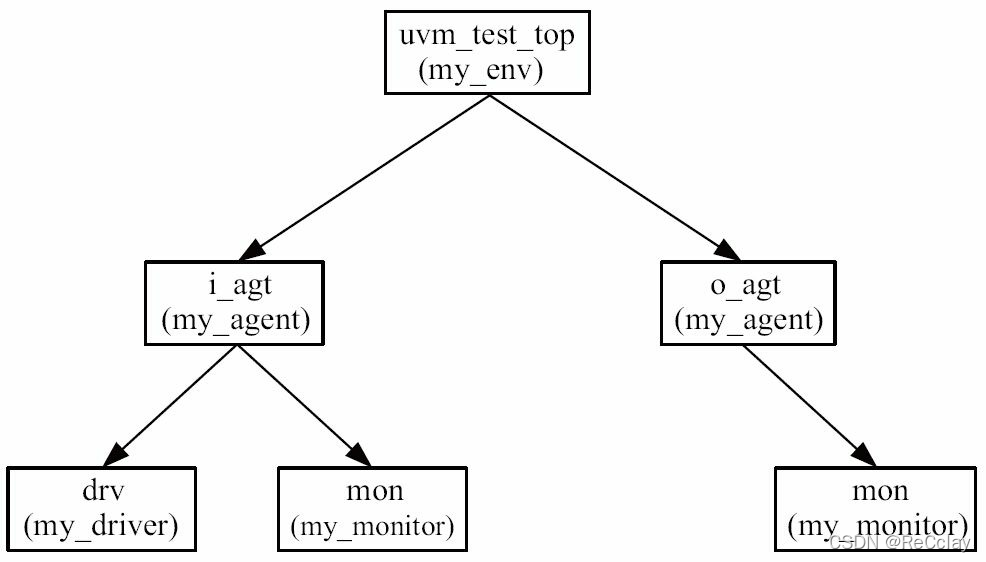
图2-6 UVM树的生长: 加入agent
由于agent的加入, driver和monitor的层次结构改变了, 在top_tb中使用config_db设置virtual my_if时要注意改变路径:
代码清单 2-37
文件: src/ch2/section2.3/2.3.4/top_tb.sv
...
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.i_agt.drv", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.i_agt.mon", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.o_agt.mon", "vif", output_if);
end
...
在加入了my_agent后, UVM的树形结构越来越清晰。 首先, 只有uvm_component才能作为树的结点, 像my_transaction这种使用uvm_object_utils宏实现的类是不能作为UVM树的结点的。 其次, 在my_env的build_phase中, 创建i_agt和o_agt的实例是在build_phase中; 在agent中, 创建driver和monitor的实例也是在build_phase中。 按照前文所述的build_phase的从树根到树叶的执行顺序, 可以建立一棵完整的UVM树。 UVM要求UVM树最晚在build_phase时段完成, 如果在build_phase后的某个phase实例化一个component:
代码清单 2-38
class my_env extends uvm_env;
...
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
endfunction
virtual task main_phase(uvm_phase phase);
i_agt = my_agent::type_id::create("i_agt", this);
o_agt = my_agent::type_id::create("o_agt", this);
i_agt.is_active = UVM_ACTIVE;
o_agt.is_active = UVM_PASSIVE;
endtask
endclass
...
如上所示, 将在my_env的build_phase中的实例化工作移动到main_phase中, UVM会给出如下错误提示:
UVM_FATAL @ 0: i_agt [ILLCRT] It is illegal to create a component ('i_agt' under 'uvm_test_top') after the build phase has ended.
那么是不是只能在build_phase中执行实例化的动作呢? 答案是否定的。 其实还可以在new函数中执行实例化的动作。 如可以在my_agent的new函数中实例化driver和monitor:
代码清单 2-39
function new(string name, uvm_component parent);
super.new(name, parent);
if (is_active == UVM_ACTIVE) begin
drv = my_driver::type_id::create("drv", this);
end
mon = my_monitor::type_id::create("mon", this);
endfunction
这样引起的一个问题是无法通过直接赋值的方式向uvm_agent传递is_active的值。 在my_env的build_phase( 或者new函数) 中,向i_agt和o_agt的is_active赋值, 根本不会产生效果。 因此i_agt和o_agt都工作在active模式( is_active的默认值是UVM_ACTIVE) ,这与预想差距甚远。 要解决这个问题, 可以在my_agent实例化之前使用config_db语句传递is_active的值:
代码清单 2-40
class my_env extends uvm_env;
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_active_passive_enum)::set(this, "i_agt", "is_active", UVM_ACTIVE);
uvm_config_db#(uvm_active_passive_enum)::set(this, "o_agt", "is_active", UVM_PASSIVE);
i_agt = my_agent::type_id::create("i_agt", this);
o_agt = my_agent::type_id::create("o_agt", this);
endfunction
endclass
class my_agent extends uvm_agent ;
function new(string name, uvm_component parent);
super.new(name, parent);
uvm_config_db#(uvm_active_passive_enum)::get(this, "", "is_active", is_active);
if (is_active == UVM_ACTIVE) begin
drv = my_driver::type_id::create("drv", this);
end
mon = my_monitor::type_id::create("mon", this);
endfunction
endclass
只是UVM中约定俗成的还是在build_phase中完成实例化工作。 因此, 强烈建议仅在build_phase中完成实例化。
2.3.5、加入reference model
在2.1节中讲述验证平台的框图时曾经说过, reference model用于完成和DUT相同的功能。 reference model的输出被scoreboard接收, 用于和DUT的输出相比较。 DUT如果很复杂, 那么reference model也会相当复杂。 本章的DUT很简单, 所以reference model也相当简单:
代码清单 2-41
文件: src/ch2/section2.3/2.3.5/my_model.sv
class my_model extends uvm_component;
uvm_blocking_get_port #(my_transaction) port;
uvm_analysis_port #(my_transaction) ap;
extern function new(string name, uvm_component parent);
extern function void build_phase(uvm_phase phase);
extern virtual task main_phase(uvm_phase phase);
`uvm_component_utils(my_model)
endclass
function my_model::new(string name, uvm_component parent);
super.new(name, parent);
endfunction
function void my_model::build_phase(uvm_phase phase);
super.build_phase(phase);
port = new("port", this);
ap = new("ap", this);
endfunction
task my_model::main_phase(uvm_phase phase);
my_transaction tr;
my_transaction new_tr;
super.main_phase(phase);
while(1) begin
port.get(tr);
new_tr = new("new_tr");
new_tr.my_copy(tr);
`uvm_info("my_model", "get one transaction, copy and print it:", UVM_LOW)
new_tr.my_print();
ap.write(new_tr);
end
endtask
在my_model的main_phase中, 只是单纯地复制一份从i_agt得到的tr, 并传递给后级的scoreboard中。 my_copy是一个在my_transaction中定义的函数, 其代码为:
代码清单 2-42
文件: src/ch2/section2.3/2.3.5/my_transaction.sv
function void my_copy(my_transaction tr);
if(tr == null)
`uvm_fatal("my_transaction", "tr is null!!!!")
dmac = tr.dmac;
smac = tr.smac;
ether_type = tr.ether_type;
pload = new[tr.pload.size()];
for(int i = 0; i < pload.size(); i++) begin
pload[i] = tr.pload[i];
end
crc = tr.crc;
endfunction
这里实现了两个my_transaction的复制。
完成my_model的定义后, 需要将其在my_env中实例化。 其实例化方式与agent、 driver相似, 这里不具体列出代码。 在加入my_model后, 整棵UVM树变成了如图2-7所示的形式。

图2-7 UVM树的生长: 加入reference model
my_model并不复杂, 这其中令人感兴趣的是my_transaction的传递方式。 my_model是从i_agt中得到my_transaction, 并把my_transaction传递给my_scoreboard。 在UVM中, 通常使用TLM( Transaction Level Modeling) 实现component之间transaction级别的通信。
要实现通信, 有两点是值得考虑的:
- 第一, 数据是如何发送的?
- 第二, 数据是如何接收的?
在UVM的transaction级别的通信中, 数据的发送有多种方式, 其中一种是使用uvm_analysis_port。 在my_monitor中定义如下变量:
代码清单 2-43
文件: src/ch2/section2.3/2.3.5/my_monitor.sv
uvm_analysis_port #(my_transaction) ap;
uvm_analysis_port是一个参数化的类, 其参数就是这个analysis_port需要传递的数据的类型, 在本节中是my_transaction。
声明了ap后, 需要在monitor的build_phase中将其实例化:
代码清单 2-44
文件: src/ch2/section2.3/2.3.5/my_monitor.sv
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
...
ap = new("ap", this);
endfunction
在main_phase中, 当收集完一个transaction后, 需要将其写入ap中:
代码清单 2-45
task my_monitor::main_phase(uvm_phase phase);
my_transaction tr;
while(1) begin
tr = new("tr");
collect_one_pkt(tr);
ap.write(tr);
end
endtask
write是uvm_analysis_port的一个内建函数。 到此, 在my_monitor中需要为transaction通信准备的工作已经全部完成。
UVM的transaction级别通信的数据接收方式也有多种, 其中一种就是使用uvm_blocking_get_port。 这也是一个参数化的类, 其参数是要在其中传递的transaction的类型。
在my_model的第6行中, 定义了一个端口, 并在build_phase中对其进行实例化。 在main_phase中, 通过port.get任务来得到从i_agt的monitor中发出的transaction。
即:相当于从my_monitor的uvm_analysis_port端口中发送transaction,在my_model的uvm_blocking_get_port端口中接收transaction!
在my_monitor和my_model中定义并实现了各自的端口之后, 通信的功能并没有实现, 还需要在my_env中使用fifo将两个端口联系在一起。 在my_env中定义一个fifo, 并在build_phase中将其实例化:
代码清单 2-46
文件: src/ch2/section2.3/2.3.5/my_env.sv
class my_env extends uvm_env;
my_agent i_agt;
my_agent o_agt;
my_model mdl;
uvm_tlm_analysis_fifo #(my_transaction) agt_mdl_fifo;
function new(string name = "my_env", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
...
agt_mdl_fifo = new("agt_mdl_fifo", this);
endfunction
extern virtual function void connect_phase(uvm_phase phase);
`uvm_component_utils(my_env)
endclass
fifo的类型是uvm_tlm_analysis_fifo, 它本身也是一个参数化的类, 其参数是存储在其中的transaction的类型, 这里是my_transaction。
之后, 在connect_phase中将fifo分别与my_monitor中的analysis_port和my_model中的blocking_get_port相连:
代码清单 2-47
文件: src/ch2/section2.3/2.3.5/my_env.sv
function void my_env::connect_phase(uvm_phase phase);
super.connect_phase(phase);
i_agt.ap.connect(agt_mdl_fifo.analysis_export);
mdl.port.connect(agt_mdl_fifo.blocking_get_export);
endfunction
这里引入了connect_phase。 与build_phase及main_phase类似, connect_phase也是UVM内建的一个phase, 它在build_phase执行完成之后马上执行。 但是与build_phase不同的是, 它的执行顺序并不是从树根到树叶, 而是从树叶到树根——先执行driver和monitor的connect_phase, 再执行agent的connect_phase, 最后执行env的connect_phase。
为什么这里需要一个fifo呢? 不能直接把my_monitor中的analysis_port和my_model中的blocking_get_port相连吗? 由于analysis_port是非阻塞性质的, ap.write函数调用完成后马上返回, 不会等待数据被接收。 假如当write函数调用时,blocking_get_port正在忙于其他事情, 而没有准备好接收新的数据时, 此时被write函数写入的my_transaction就需要一个暂存的位置, 这就是fifo。
在如上的连接中, 用到了i_agt的一个成员变量ap, 它的定义与my_monitor中ap的定义完全一样:
代码清单 2-48
文件: src/ch2/section2.3/2.3.5/my_agent.sv
uvm_analysis_port #(my_transaction) ap;
与my_monitor中的ap不同的是, 不需要对my_agent中的ap进行实例化, 而只需要在my_agent的connect_phase中将monitor的值赋给它, 换句话说, 这相当于是一个指向my_monitor的ap的指针:
代码清单 2-49
文件: src/ch2/section2.3/2.3.5/my_agent.sv
function void my_agent::connect_phase(uvm_phase phase);
super.connect_phase(phase);
ap = mon.ap;
endfunction
根据前面介绍的connect_phase的执行顺序, my_agent的connect_phase的执行顺序早于my_env的connect_phase的执行顺序, 从而可以保证执行到i_agt.ap.connect语句时, i_agt.ap不是一个空指针。
2.3.6、加入scoreboard
在验证平台中加入了reference model和monitor之后, 最后一步是加入scoreboard。 my_scoreboard的代码如下:
代码清单 2-50
文件: src/ch2/section2.3/2.3.6/my_scoreboard.sv
class my_scoreboard extends uvm_scoreboard;
my_transaction expect_queue[$];
uvm_blocking_get_port #(my_transaction) exp_port;
uvm_blocking_get_port #(my_transaction) act_port;
`uvm_component_utils(my_scoreboard)
extern function new(string name, uvm_component parent = null);
extern virtual function void build_phase(uvm_phase phase);
extern virtual task main_phase(uvm_phase phase);
endclass
function my_scoreboard::new(string name, uvm_component parent = null);
super.new(name, parent);
endfunction
function void my_scoreboard::build_phase(uvm_phase phase);
super.build_phase(phase);
exp_port = new("exp_port", this);
act_port = new("act_port", this);
endfunction
task my_scoreboard::main_phase(uvm_phase phase);
my_transaction get_expect, get_actual, tmp_tran;
bit result;
super.main_phase(phase);
fork
while (1) begin //进程1
exp_port.get(get_expect);
expect_queue.push_back(get_expect);
end
while (1) begin //进程2
act_port.get(get_actual);
if(expect_queue.size() > 0) begin
tmp_tran = expect_queue.pop_front();
result = get_actual.my_compare(tmp_tran);
if(result) begin
`uvm_info("my_scoreboard", "Compare SUCCESSFULLY", UVM_LOW);
end
else begin
`uvm_error("my_scoreboard", "Compare FAILED");
$display("the expect pkt is");
tmp_tran.my_print();
$display("the actual pkt is");
get_actual.my_print();
end
end
else begin
`uvm_error("my_scoreboard", "Received from DUT, while Expect Queue is empty");
$display("the unexpected pkt is");
get_actual.my_print();
end
end
join
endtask
my_scoreboard要比较的数据一是来源于reference model, 二是来源于o_agt的monitor。 前者通过exp_port获取, 而后者通过act_port获取。
在main_phase中通过fork建立起了两个进程, 一个进程处理exp_port的数据, 当收到数据后, 把数据放入expect_queue中; 另外一个进程处理act_port的数据, 这是DUT的输出数据, 当收集到这些数据后, 从expect_queue中弹出之前从exp_port收到的数据, 并调用my_transaction的my_compare函数。 采用这种比较处理方式的前提是exp_port要比act_port先收到数据。 由于DUT处理数据需要延时, 而reference model是基于高级语言的处理, 一般不需要延时, 因此可以保证exp_port的数据在act_port的数据之前到来。
act_port和o_agt的ap的连接方式及exp_port和reference model的ap的连接方式与2.3.5节讲述的i_agt的ap和reference model的端口的连接方式类似, 这里不再赘述。
代码清单2-50中的第38行用到了my_compare函数, 这是一个在my_transaction中定义的函数, 其原型为:
代码清单 2-51
文件: src/ch2/section2.3/2.3.6/my_scoreboard.sv
function bit my_compare(my_transaction tr);
bit result;
if(tr == null)
`uvm_fatal("my_transaction", "tr is null!!!!")
result = ((dmac == tr.dmac) &&
(smac == tr.smac) &&
(ether_type == tr.ether_type) &&
(crc == tr.crc));
if(pload.size() != tr.pload.size())
result = 0;
else
for(int i = 0; i < pload.size(); i++) begin
if(pload[i] != tr.pload[i])
result = 0;
end
return result;
endfunction
它逐字段比较两个my_transaction, 并给出最终的比较结果。
完成my_scoreboard的定义后, 也需要在my_env中将其实例化。 此时, 整棵UVM树变为如图2-8所示的形式。
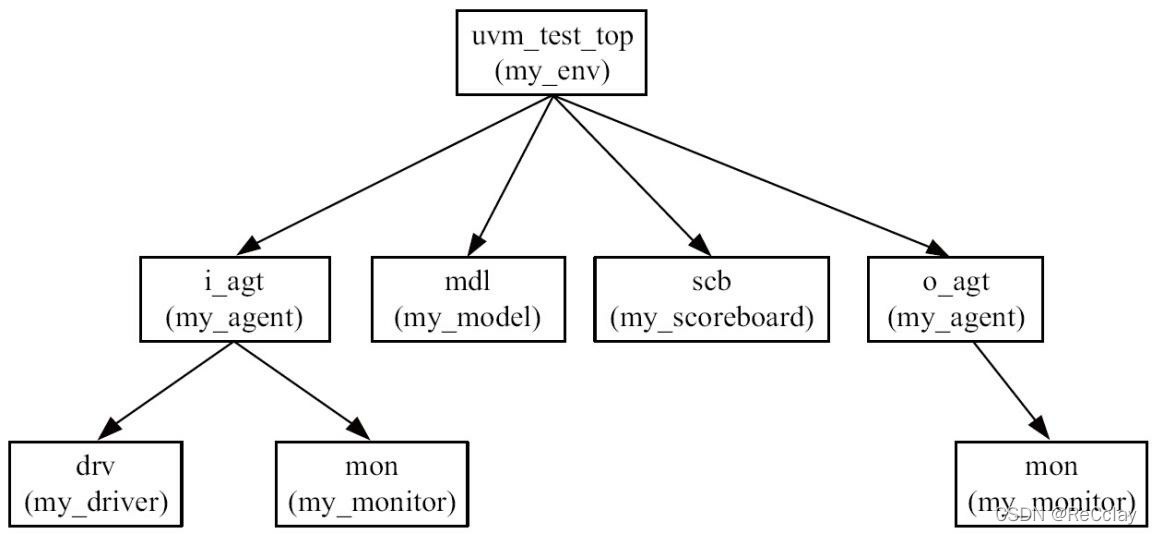
图2-8 UVM树的生长: 加入scoreboard
2.3.7、加入field_automation机制
在2.3.3节中引入my_mointor时, 在my_transaction中加入了my_print函数; 在2.3.5节中引入reference model时, 加入了my_copy函数; 在2.3.6节引入scoreboard时, 加入了my_compare函数。 上述三个函数虽然各自不同, 但是对于不同的transaction来说, 都是类似的: 它们都需要逐字段地对transaction进行某些操作。
那么有没有某种简单的方法, 可以通过定义某些规则自动实现这三个函数呢? 答案是肯定的。 这就是UVM中的field_automation机制, 使用uvm_field系列宏实现:
代码清单 2-52
文件: src/ch2/section2.3/2.3.7/my_transaction.sv
class my_transaction extends uvm_sequence_item;
rand bit[47:0] dmac;
rand bit[47:0] smac;
rand bit[15:0] ether_type;
rand byte pload[];
rand bit[31:0] crc;
...
`uvm_object_utils_begin(my_transaction)
`uvm_field_int(dmac, UVM_ALL_ON)
`uvm_field_int(smac, UVM_ALL_ON)
`uvm_field_int(ether_type, UVM_ALL_ON)
`uvm_field_array_int(pload, UVM_ALL_ON)
`uvm_field_int(crc, UVM_ALL_ON)
`uvm_object_utils_end
...
endclass
这里使用uvm_object_utils_begin和uvm_object_utils_end来实现my_transaction的factory注册, 在这两个宏中间, 使用uvm_field宏注册所有字段。 uvm_field系列宏随着transaction成员变量的不同而不同, 如上面的定义中出现了针对bit类型的uvm_field_int及针对byte类型动态数组的uvm_field_array_int。 3.3.1节列出了所有的uvm_field系列宏。
当使用上述宏注册之后, 可以直接调用copy、 compare、 print等函数, 而无需自己定义。 这极大地简化了验证平台的搭建, 提高了效率:
代码清单 2-53
文件: src/ch2/section2.3/2.3.7/my_model.sv
task my_model::main_phase(uvm_phase phase);
super.main_phase(phase);
while(1) begin
...
new_tr.copy(tr);// 自带copy函数
...
代码清单 2-54
文件: src/ch2/section2.3/2.3.7/my_scoreboard.sv
task my_scoreboard::main_phase(uvm_phase phase);
...
super.main_phase(phase);
fork
...
while (1) begin
act_port.get(get_actual);
if(expect_queue.size() > 0) begin
tmp_tran = expect_queue.pop_front();
result = get_actual.compare(tmp_tran); // 自带compare函数
...
引入field_automation机制的另外一大好处是简化了driver和monitor。 在2.3.1节及2.3.3节中, my_driver的drv_one_pkt任务和my_monitor的collect_one_pkt任务代码很长, 但是几乎都是一些重复性的代码。 使用field_automation机制后, drv_one_pkt任务可以简化为:
代码清单 2-55
文件: src/ch2/section2.3/2.3.7/my_driver.sv
task my_driver::drive_one_pkt(my_transaction tr);
byte unsigned data_q[];
int data_size;
data_size = tr.pack_bytes(data_q) / 8;
`uvm_info("my_driver", "begin to drive one pkt", UVM_LOW);
repeat(3) @(posedge vif.clk);
for ( int i = 0; i < data_size; i++ ) begin
@(posedge vif.clk);
vif.valid <= 1'b1;
vif.data <= data_q[i];
end
@(posedge vif.clk);
vif.valid <= 1'b0;
`uvm_info("my_driver", "end drive one pkt", UVM_LOW);
endtask
第42行调用pack_bytes将tr中所有的字段变成byte流放入data_q中, 在2.3.1节中是手工地将所有字段放入data_q中的。pack_bytes极大地减少了代码量。 在把所有的字段变成byte流放入data_q中时, 字段按照uvm_field系列宏书写的顺序排列。 在上述代码中是先放入dmac, 再依次放入smac、 ether_type、 pload、 crc。 假如my_transaction定义时各个字段的顺序如下:
代码清单 2-56
`uvm_object_utils_begin(my_transaction)
`uvm_field_int(smac, UVM_ALL_ON)
`uvm_field_int(dmac, UVM_ALL_ON)
`uvm_field_int(ether_type, UVM_ALL_ON)
`uvm_field_array_int(pload, UVM_ALL_ON)
`uvm_field_int(crc, UVM_ALL_ON)
`uvm_object_utils_end
那么将会先放入smac, 再依次放入dmac、 ether_type、 pload、 crc。
my_monitor的collect_one_pkt可以简化成:
代码清单 2-57
文件: src/ch2/section2.3/2.3.7/my_monitor.sv
task my_monitor::collect_one_pkt(my_transaction tr);
byte unsigned data_q[$];
byte unsigned data_array[];
logic [7:0] data;
logic valid = 0;
int data_size;
while(1) begin
@(posedge vif.clk);
if(vif.valid) break;
end
`uvm_info("my_monitor", "begin to collect one pkt", UVM_LOW);
while(vif.valid) begin
data_q.push_back(vif.data);
@(posedge vif.clk);
end
data_size = data_q.size();
data_array = new[data_size];
for ( int i = 0; i < data_size; i++ ) begin
data_array[i] = data_q[i];
end
tr.pload = new[data_size - 18]; //da sa, e_type, crc = 6 + 6 + 2 + 4 = 18
data_size = tr.unpack_bytes(data_array) / 8;
`uvm_info("my_monitor", "end collect one pkt", UVM_LOW);
endtask
这里使用unpack_bytes函数将data_q中的byte流转换成tr中的各个字段。 unpack_bytes函数的输入参数必须是一个动态数组, 所以需要先把收集到的、 放在data_q中的数据复制到一个动态数组中。 由于tr中的pload是一个动态数组, 所以需要在调用unpack_bytes之前指定其大小, 这样unpack_bytes函数才能正常工作。
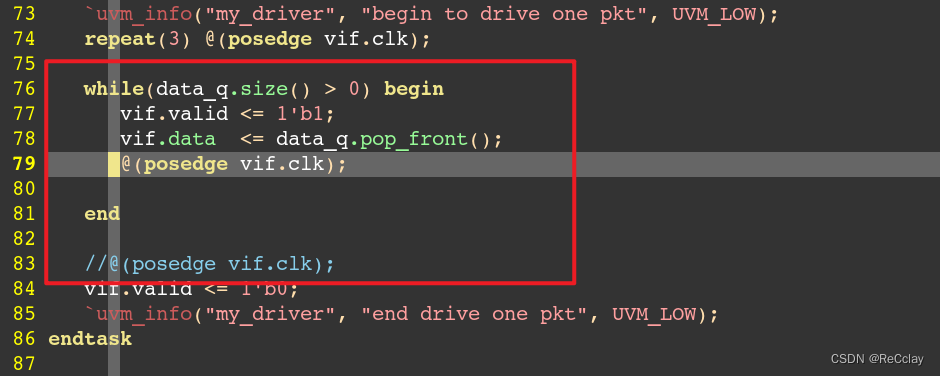
driver时序解读
driver发送数据,建议是将打拍放在发送数据后,如下图79行打拍放在77和78行后。如果放在了发送数据之前,需要对最后一拍数据再进行打拍处理,如下图需要加上83行。【这两种方式,先发数据再打拍,整体时序会比先打拍再发数据早一拍。】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











