




 文章探讨了GPU的渲染管线,重点介绍了SIMD指令和SIMT技术如何实现指令级并行运算,提高坐标和矩阵运算效率。现代显卡利用大量小核心进行并行处理,建议在绘制算法中使用相同代码并减少CPU-GPU间的数据交互以避免帧数延迟。游戏引擎通过将对象切分成子mesh,存储在缓冲区中,并使用包围盒(BVH)优化碰撞检测,实现了资源的有效管理和性能提升。
文章探讨了GPU的渲染管线,重点介绍了SIMD指令和SIMT技术如何实现指令级并行运算,提高坐标和矩阵运算效率。现代显卡利用大量小核心进行并行处理,建议在绘制算法中使用相同代码并减少CPU-GPU间的数据交互以避免帧数延迟。游戏引擎通过将对象切分成子mesh,存储在缓冲区中,并使用包围盒(BVH)优化碰撞检测,实现了资源的有效管理和性能提升。
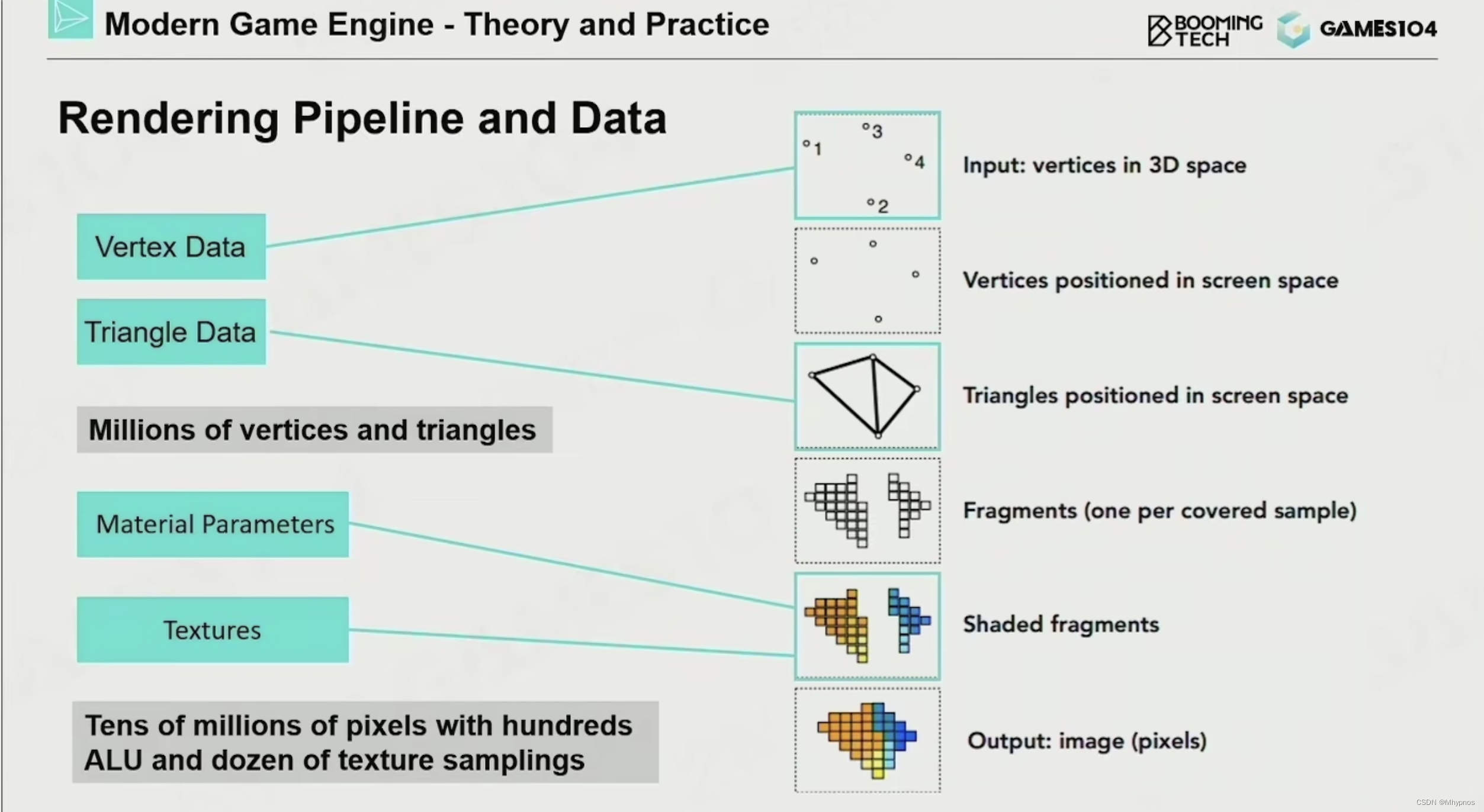
渲染管线
显卡:
SIMD指令:指令级并行运算。一个指令,4次运算。处理坐标运算,矩阵运算
SIMT:一个指令在多核上,同时做同样的指令操作。
现代显卡放了无数个小小的核。
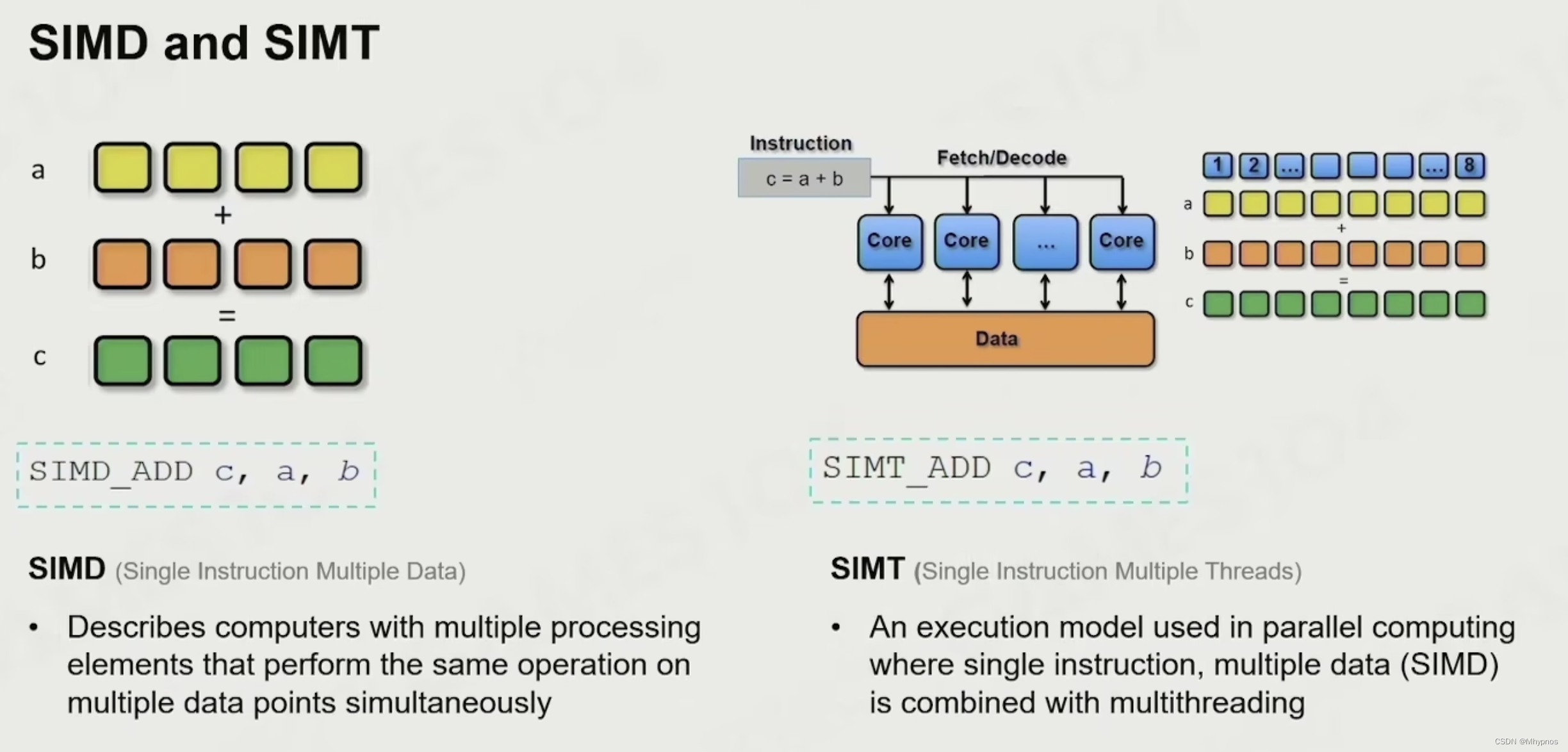
因此,在做所有的绘制算法,绘制运算时,尽可能用同样的代码,各自访问各自的数据,效率会远高于CPU上的运算
数据尽量只从cpu送到gpu计算结束了,不要从gpu读数据。因为逻辑和渲染是不同步的,来回的数据交互会导致帧数的延迟
现代引擎,对于一个GO,会将其mesh,根据材质应用的不同切分成各个子mesh。
每个submesh的顶点数据,索引,纹理等会存在一个大的buffer里,通过不同的offset获取。
将所有的mesh存在一个pool,
texture存在一个pool,
shader存在一个pool
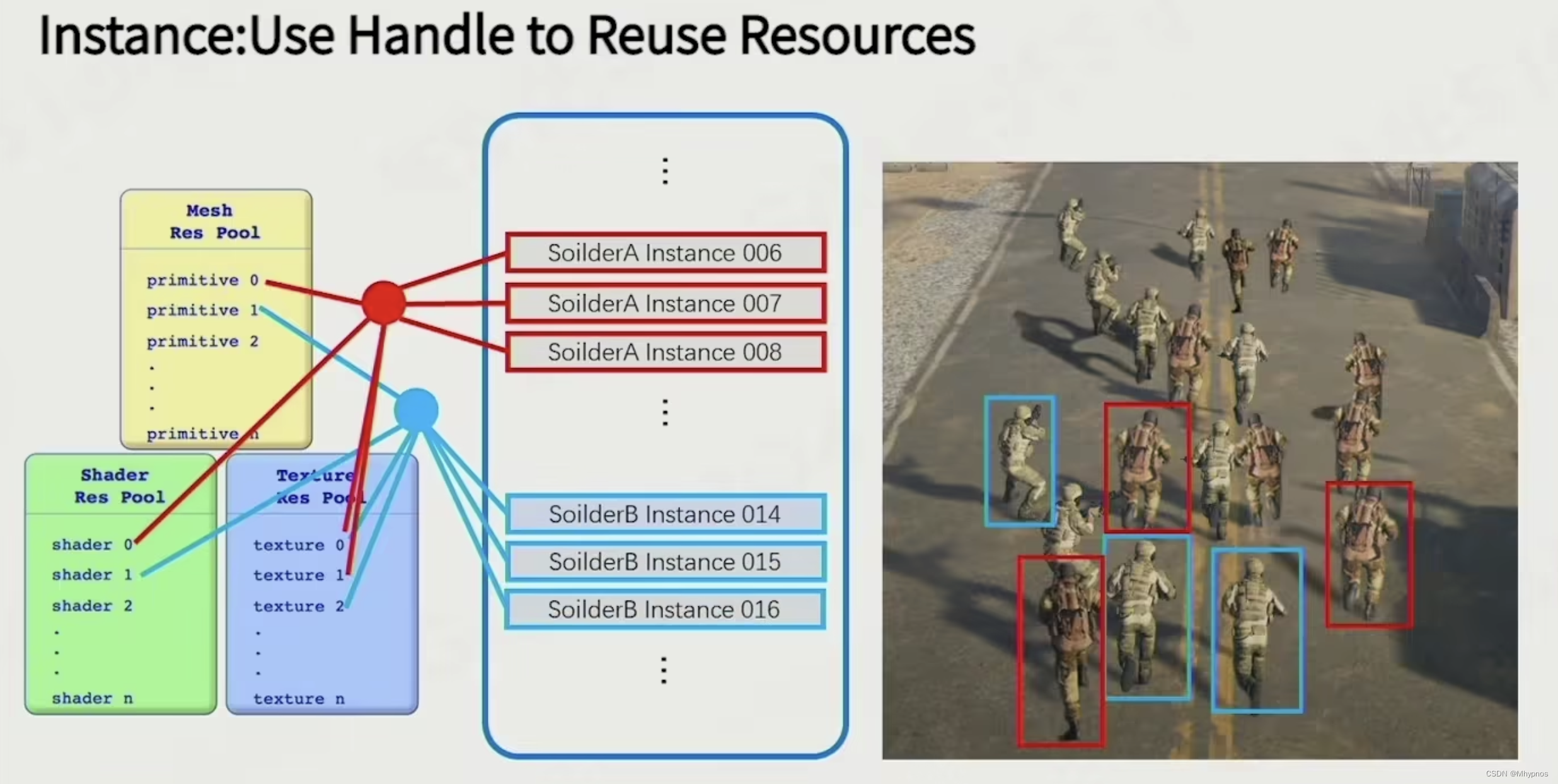
注意区分定义(GO)和实例(prefab/instance)。即类和对象
包围盒
BVH

















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









