




 本文探讨了参数剪枝与滤波器剪枝的区别,指出了参数剪枝的缺点,并提出SPF方法,允许在训练过程中更新被剪枝的卷积核,同时减少了对预训练模型的依赖。实验表明,SPF能有效提高模型容量,且在剪枝率较高的情况下仍保持高识别率。然而,该方法在数据量小且无预训练模型的情况下可能面临挑战。
本文探讨了参数剪枝与滤波器剪枝的区别,指出了参数剪枝的缺点,并提出SPF方法,允许在训练过程中更新被剪枝的卷积核,同时减少了对预训练模型的依赖。实验表明,SPF能有效提高模型容量,且在剪枝率较高的情况下仍保持高识别率。然而,该方法在数据量小且无预训练模型的情况下可能面临挑战。
文章目录
摘要
两大特点
- 更大的模型容量-可以更新之前修剪的参数,而不是固定为0
- 更少的依赖于之前训练好的模型,可以一边从头开始训练一边做剪枝
1.介绍
1.1参数剪枝与滤波器剪枝的区别
滤波器剪枝才可以真正的提高速率
1.2参数剪枝的两大缺点:
- a.模型容量降低
- b.需要之间训练好的模型
1.3基本训练过程:
在每一轮的迭代中都将L2正则化参数小的卷积核置0
1.4模型的贡献:
- a.让卷积核可以在训练过程中更新
- b.可以让模型从0开始训练
- c.识别率很nb
2.相关工作
之前的模型压缩算法有张量分解,低精度权重,和剪枝。其中张量分解和低精度权重与我们的研究是正交的,在未来的工作中可以将这两个方法与我们的模型融合。
2.1权重剪枝
权剪枝总是带来非结构性的调整。所以很难取得真正加速
2.2滤波器剪枝
各种滤波器剪枝方法都会使模型容量减小
2.3讨论:与现有的软剪枝方法的区别
- a.我们关注对滤波器的剪枝,而郭的是对权重的剪枝
- b.郭更注重的是模型的压缩,而我们模型还考虑了识别的精度
- c.郭的实验只在AlexNet进行,这个网络相比更前沿的网路有更多的冗余
3.研究方法(Methodology )
3.1准备工作(Preliminaries)
介绍了符号和注释
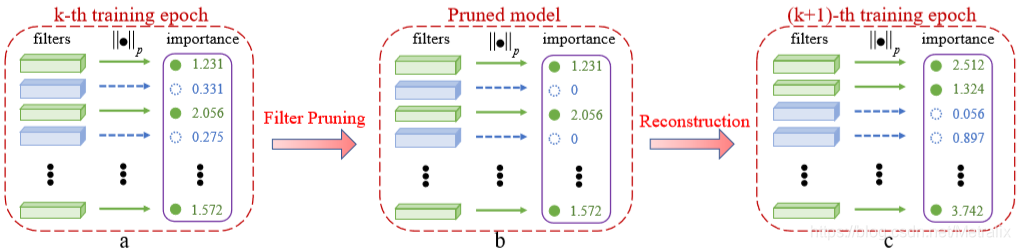
3.2 SPF
提到另外一个优点是可以全局一起修剪
- a.滤波器选择:L范数越小的被删减的优先级越高
- b.滤波器剪枝:以一定的比例使滤波器置0,这样的时间效率很高
- c.重构:进入下一轮迭代,不需要fine-tuning
- d.得到模型:算法收敛,删除置0项,得到Compact的模型

4.评估和结果(EvaluationandResults)
可调的超参数:
- 评价准则L2>L1
- 剪枝率
- 一个epoch所含的interval
- 不同层的剪枝率
这些都可以后续进行研究
5.总结和未来工作
6.致谢(Acknowledgments)
-----------------------------------------------------------
观后感:缺点
- 模型需要迭代至算法收敛,如股数据量很小且没有原始模型怎么整
- 还是基于L1/L2范数的评价指标,没有考虑如果基于其他评价体系是否会有更好的效果呢
- 无法对网络架构进行修剪
- 感觉论文中有很多废话
观后感:疑问
- 这个文章的创新点看起来并不是很复杂,数学原理比较简单,为什么可以
中顶会IJCAI?难道是因为实验效果好吗?
---------------------------------------------------------
实验
代码技巧
- 获取filter中的weight
通过如下代码可以看到模型中各个参数的名称
reader=pywrap_tensorflow.NewCheckpointReader(checkpoint_path)
var_to_shape_map=reader.get_variable_to_shape_map()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4373
4373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









