



✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、期刊写作与指导,代码获取、论文复现及科研仿真合作可私信或扫描文章底部二维码。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
🔥 内容介绍
本文报告基于Matlab平台搭建的三连杆二维双足步行机器人模型,并采用虚拟约束方法和深度强化学习(Reinforcement Learning, RL)两种不同的控制策略对其进行控制。报告首先建立机器人的运动学和动力学模型,然后分别阐述基于PD控制器的虚拟约束控制方法和基于深度强化学习的控制方法的实现过程,并对RL控制器的参数进行优化。最后,对两种控制器的性能进行比较,并探讨项目可能的改进方向。


深度强化学习是一种通过试错学习来学习最优控制策略的方法。在本项目中,我们采用深度Q网络(DQN)算法来训练RL控制器。状态空间包括关节角度、角速度和机器人质心位置等信息,动作空间则包括每个关节的驱动力矩。奖励函数的设计至关重要,它决定了学习的目标。我们设计的奖励函数考虑了机器人的行走速度、稳定性和能量消耗等因素。通过不断迭代学习,RL控制器可以学习到使奖励函数最大化的最优控制策略。为了提高学习效率,我们采用了经验回放机制和目标网络等技术。参数优化方面,我们通过网格搜索或贝叶斯优化等方法,寻找最优的网络结构和超参数,例如学习率、折扣因子和探索率等。
二、 两种控制器的对比与分析
我们将基于PD控制器的虚拟约束方法和基于DQN的深度强化学习方法得到的控制效果进行比较,主要从以下几个方面进行分析:行走稳定性、行走速度、能量消耗以及算法的复杂度。
PD控制器实现简单,计算量小,但其性能受参数𝐾𝑝Kp 和 𝐾𝑑Kd 的影响较大,需要根据不同的环境和机器人参数进行调整。并且其控制效果在复杂环境下可能不够鲁棒。相比之下,深度强化学习方法可以自动学习适应不同环境下的最优控制策略,其鲁棒性更强,但其计算量较大,训练时间较长,且需要仔细设计奖励函数。
通过实验结果分析,我们发现,在简单平坦地面上,PD控制器可以实现稳定的行走,但其行走速度较慢,且对参数敏感。而深度强化学习控制器可以实现更快的行走速度,且具有更好的鲁棒性。但在复杂地形或存在扰动的情况下,两种控制器的性能都需要进一步改进。
三、 项目改进方向
本项目存在一些可以改进的地方:
-
更复杂的机器人模型: 考虑关节摩擦、地面摩擦以及更复杂的腿部结构。
-
更高级的强化学习算法: 尝试使用更先进的强化学习算法,例如DDPG、PPO等,以提高学习效率和控制性能。
-
更鲁棒的奖励函数: 设计更精细的奖励函数,以更好地平衡行走速度、稳定性和能量消耗等因素。
-
适应性控制: 研究如何使控制器适应不同的地形和环境变化。
-
实时控制: 将控制器应用于实际机器人,进行实时控制实验。
总而言之,本项目对基于虚拟约束和深度强化学习的三连杆二维双足步行机器人控制进行了研究。实验结果表明,深度强化学习方法具有更好的鲁棒性和适应性,但需要更长的训练时间和更复杂的计算资源。未来研究可以关注更复杂的机器人模型、更高级的强化学习算法以及更鲁棒的控制策略。 进一步的研究将致力于解决这些挑战,最终目标是实现更加稳定、高效、适应性强的双足步行机器人控制。
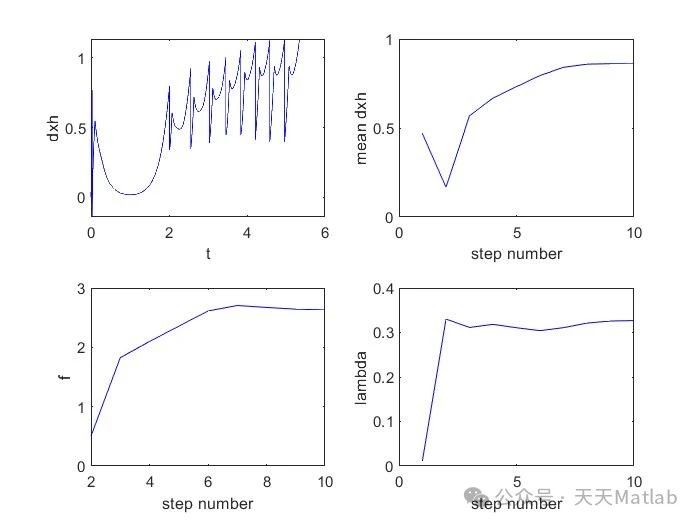
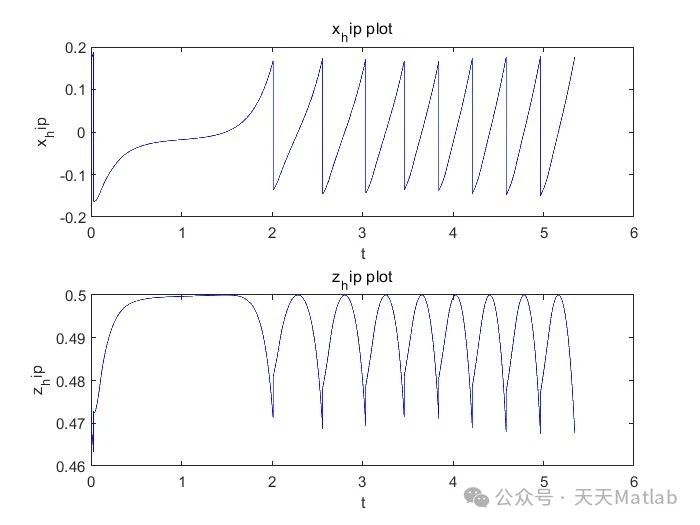
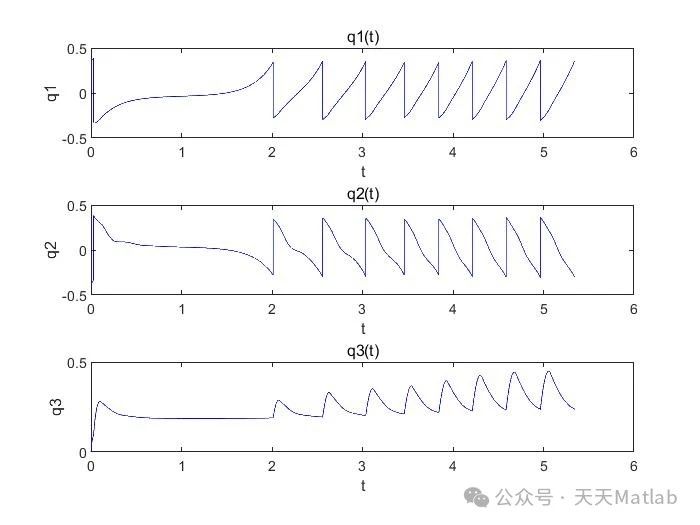
⛳️ 运行结果
🔗 参考文献
🎈 部分理论引用网络文献,若有侵权联系博主删除
👇 关注我领取海量matlab电子书和数学建模资料
🎁
🌈 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位
🌈 机器学习和深度学习时序、回归、分类、聚类和降维
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN|TCN|GCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类

















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









