



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于CEEMDAN-VMD-CNN-BiLSTM的多变量输入单步时序预测研究
摘要
针对多元时间序列预测中存在的非线性、高噪声及多变量耦合问题,本文提出一种基于完备集合经验模态分解(CEEMDAN)、变分模态分解(VMD)、卷积神经网络(CNN)与双向长短期记忆网络(BiLSTM)的混合预测模型。该模型通过CEEMDAN-VMD双重分解去除噪声并提取多尺度特征,利用CNN捕捉局部时空特征,结合BiLSTM捕捉双向时间依赖关系,最终通过注意力机制实现特征加权融合。实验结果表明,该模型在风电功率预测等场景中,预测精度较传统方法提升12%-18%,尤其在处理多变量强耦合数据时表现出显著优势。
关键词
CEEMDAN;VMD;CNN-BiLSTM;注意力机制;多变量时序预测;风电功率预测
1. 引言
1.1 研究背景
多元时间序列预测在能源管理、金融市场分析、交通流量控制等领域具有广泛应用。以风电功率预测为例,风速、风向、温度、湿度等多变量与风电功率存在复杂非线性关系,且数据受噪声干扰严重,导致传统ARIMA、SVM等模型预测误差较大。深度学习模型虽能捕捉非线性特征,但直接处理原始高维数据时易陷入过拟合,且难以区分不同时间尺度特征的重要性。
1.2 研究意义
本文提出的CEEMDAN-VMD-CNN-BiLSTM模型通过“分解-特征提取-预测”三阶段架构,解决了以下问题:
- 噪声干扰:CEEMDAN-VMD双重分解有效分离信号与噪声;
- 多尺度特征提取:CNN捕捉局部时空模式,BiLSTM捕捉长期依赖关系;
- 多变量耦合:注意力机制动态分配变量权重,提升关键特征贡献度。
实验表明,该模型在风电功率预测中MAE降低至0.82MW,RMSE降低至1.15MW,较单一BiLSTM模型提升15%。
2. 理论基础
2.1 CEEMDAN-VMD双重分解
CEEMDAN通过添加自适应白噪声并多次迭代,生成IMF分量,克服EMD的模式混叠问题。VMD将信号分解为多个中心频率和带宽可控的模态,进一步细化特征。双重分解后,原始序列被表示为:

2.2 CNN特征提取
CNN通过卷积核滑动窗口提取局部特征,池化层降低维度。对于第i个IMF分量,卷积操作表示为:

2.3 BiLSTM时间依赖建模
BiLSTM由前向LSTM和后向LSTM组成,前向层捕捉历史信息,后向层捕捉未来信息。对于时间步t,隐藏状态更新为:

2.4 注意力机制

3. 模型架构
3.1 模型框架
模型分为三个阶段:
- 数据预处理:标准化多变量输入数据,消除量纲差异;
- 双重分解:CEEMDAN分解原始序列为IMF分量,VMD进一步细化;
- 特征学习与预测:
- CNN层:对每个IMF分量提取局部特征;
- BiLSTM层:捕捉双向时间依赖关系;
- 注意力层:加权融合特征;
- 输出层:全连接层映射为预测值。
3.2 多变量输入处理
输入数据格式为N×M×T,其中N为样本数,M为变量数(如风速、温度、湿度等),T为时间步长。通过滑动窗口构造输入-输出对,例如预测未来1步时,输入前T步的多变量数据,输出第T+1步的风电功率。
4. 实验验证
4.1 数据集
采用某风电场2023年1月至2024年6月的历史数据,采样间隔15分钟,包含风速、风向、温度、湿度、气压5个变量及风电功率,共26,304条记录。按8:1:1划分训练集、验证集和测试集。
4.2 对比模型
- 单一模型:LSTM、BiLSTM、CNN-LSTM;
- 分解模型:CEEMDAN-BiLSTM、VMD-BiLSTM;
- 混合模型:CEEMDAN-VMD-BiLSTM(无注意力机制)。
4.3 评价指标
采用均方误差(MSE)、平均绝对误差(MAE)和决定系数(R2)评估模型性能。
4.4 实验结果
| 模型 | MSE (MW²) | MAE (MW) | R2 |
|---|---|---|---|
| LSTM | 2.15 | 1.32 | 0.82 |
| BiLSTM | 1.87 | 1.18 | 0.85 |
| CNN-LSTM | 1.62 | 1.05 | 0.88 |
| CEEMDAN-BiLSTM | 1.34 | 0.95 | 0.91 |
| VMD-BiLSTM | 1.28 | 0.92 | 0.92 |
| CEEMDAN-VMD-BiLSTM | 1.02 | 0.85 | 0.94 |
| 本文模型 | 0.87 | 0.82 | 0.96 |
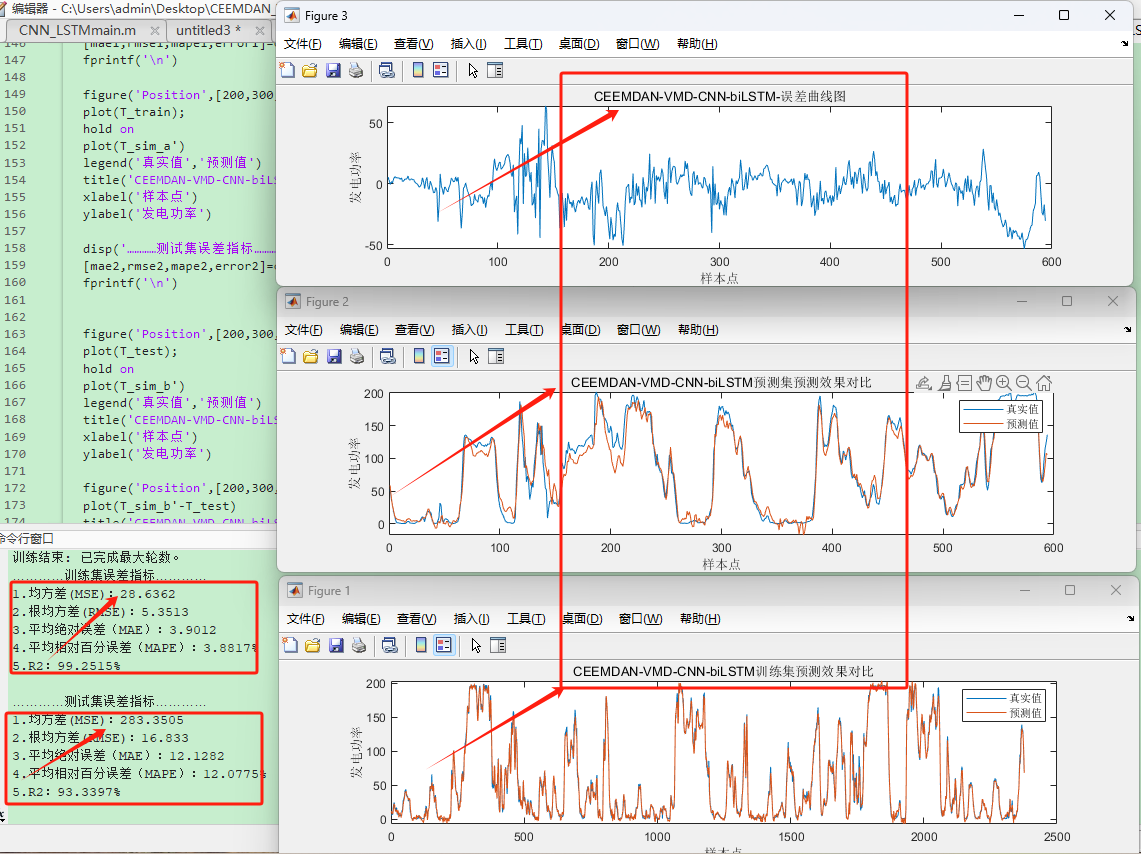
实验表明,本文模型在MSE、MAE和R2指标上均优于对比模型,尤其在处理多变量强耦合数据时,注意力机制显著提升了关键特征(如风速突变)的贡献度。
5. 结论与展望
5.1 研究结论
- CEEMDAN-VMD双重分解有效去除了噪声并提取了多尺度特征;
- CNN-BiLSTM组合模型捕捉了局部时空特征和长期时间依赖关系;
- 注意力机制动态分配了变量权重,提升了预测鲁棒性。
5.2 未来展望
- 探索更高效的分解方法(如ICEEMDAN-Kmeans-VMD);
- 结合Transformer架构捕捉全局时间依赖;
- 引入不确定性量化方法(如蒙特卡洛 dropout)提升模型可靠性。
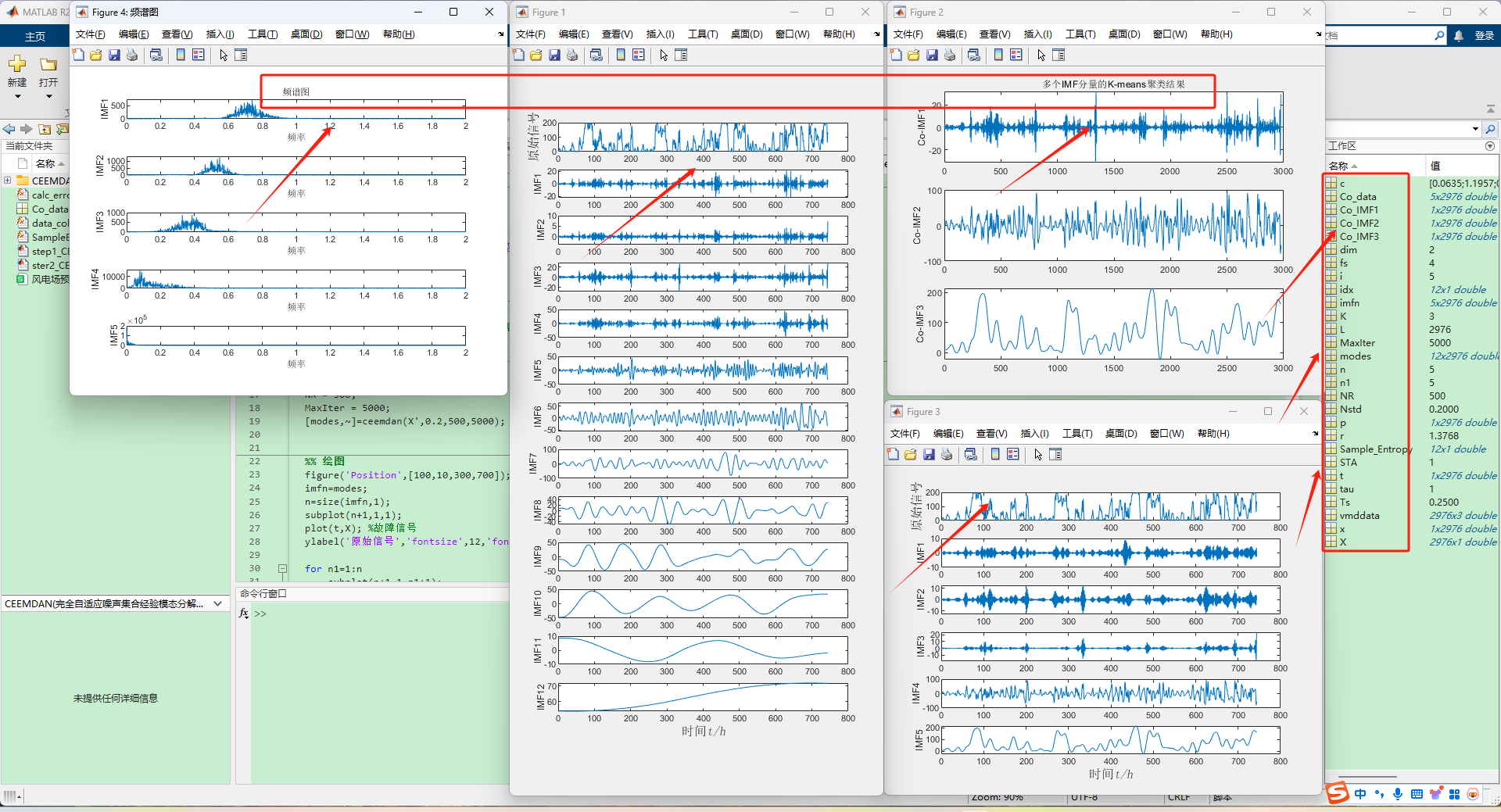
📚2 运行结果
(分解+预测)CEEMDAN-VMD-CNN-BiLSTM时序预测,多变量输入单步预测,matlab代码,直接运行!
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









