



 本文探讨了双曲线欠采样滤波器在去除关键绩效指标(KPIs)噪声中的应用,以及如何结合相关向量机估计概率基准,以识别改进机会。通过纳米金融数据集的实例展示了这种方法的有效性。同时提供了Matlab代码实现的BayesianLogisticRegressionwithRVM算法。
本文探讨了双曲线欠采样滤波器在去除关键绩效指标(KPIs)噪声中的应用,以及如何结合相关向量机估计概率基准,以识别改进机会。通过纳米金融数据集的实例展示了这种方法的有效性。同时提供了Matlab代码实现的BayesianLogisticRegressionwithRVM算法。
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录

💥1 概述
【双曲线欠采样和概率基准】双曲线欠采样滤波器去除关键绩效指标(KPIs)的噪声研究
双曲线欠采样和概率基准,双曲线欠采样滤波器去噪变量,相关向量机估计概率基准,基准是标准,可以帮助识别可改进的机会。本文在嘈杂的数据集中执行概率基准的两步估计:
(i) 双曲线欠采样滤波器去除关键绩效指标(KPIs)的噪声,
(ii) 相关向量机使用去噪的KPIs估计概率基准。该方法的实用性通过对纳米金融+数据库的应用进行了说明。
双曲线欠采样和概率基准在去除关键绩效指标(KPIs)噪声方面发挥着重要作用。双曲线欠采样滤波器是一种有效的去噪工具,能够有效地去除KPIs中的噪声,从而提高数据的准确性和可靠性。与此同时,相关向量机则能够使用去噪后的KPIs来估计概率基准,这一基准可以作为标准,帮助我们识别出可改进的机会。
本文针对嘈杂的数据集进行了概率基准的两步估计。首先,我们使用双曲线欠采样滤波器去除KPIs的噪声,确保数据的清晰度和准确性。其次,我们利用相关向量机来估计概率基准,从而找出潜在的改进机会。通过对纳米金融+数据库的应用,我们验证了该方法的实用性和有效性。
综上,双曲线欠采样和概率基准的结合为我们提供了一种强大的工具,可以帮助我们去除噪声、提高数据质量,并且发现潜在的改进机会。这对于各种领域的数据分析和决策都具有重要意义。
📚2 运行结果
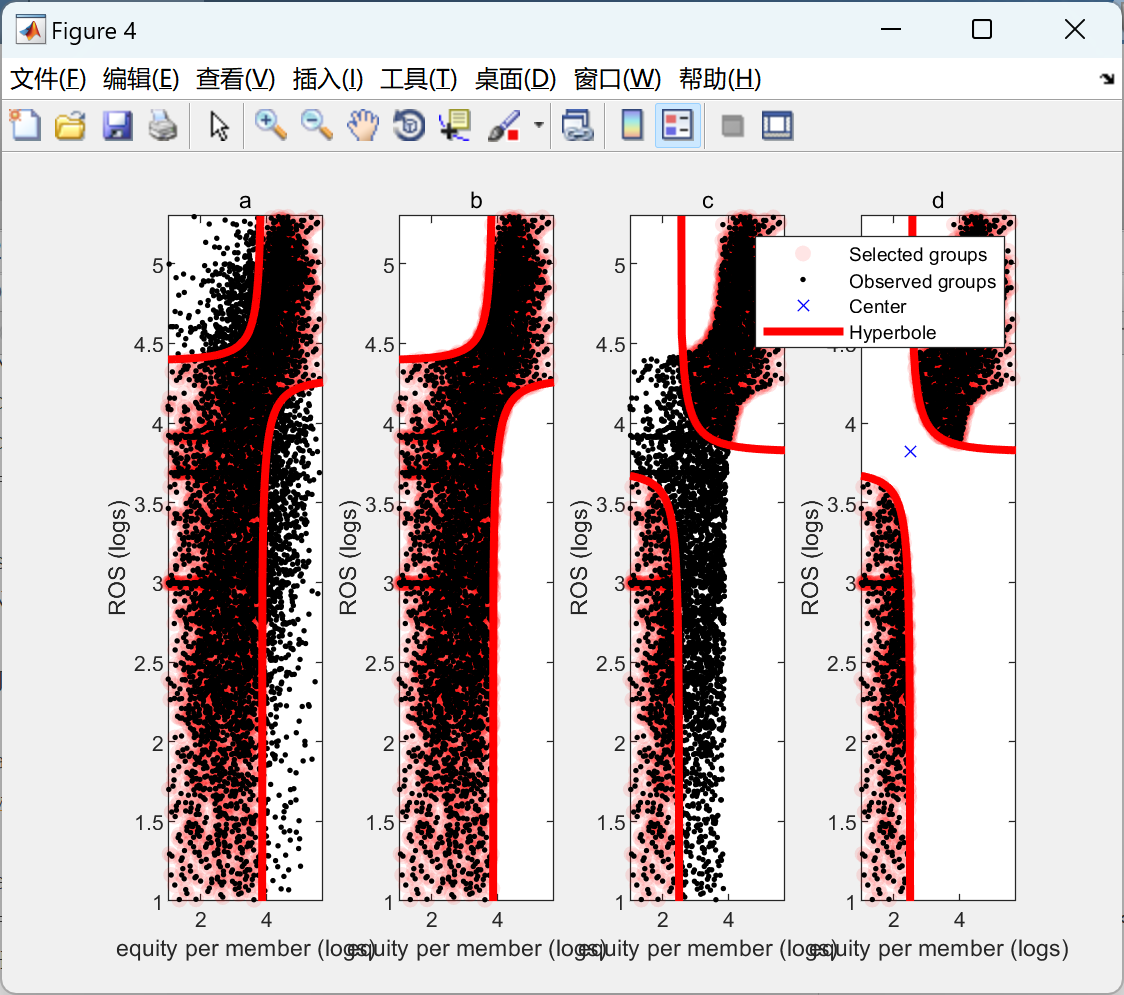
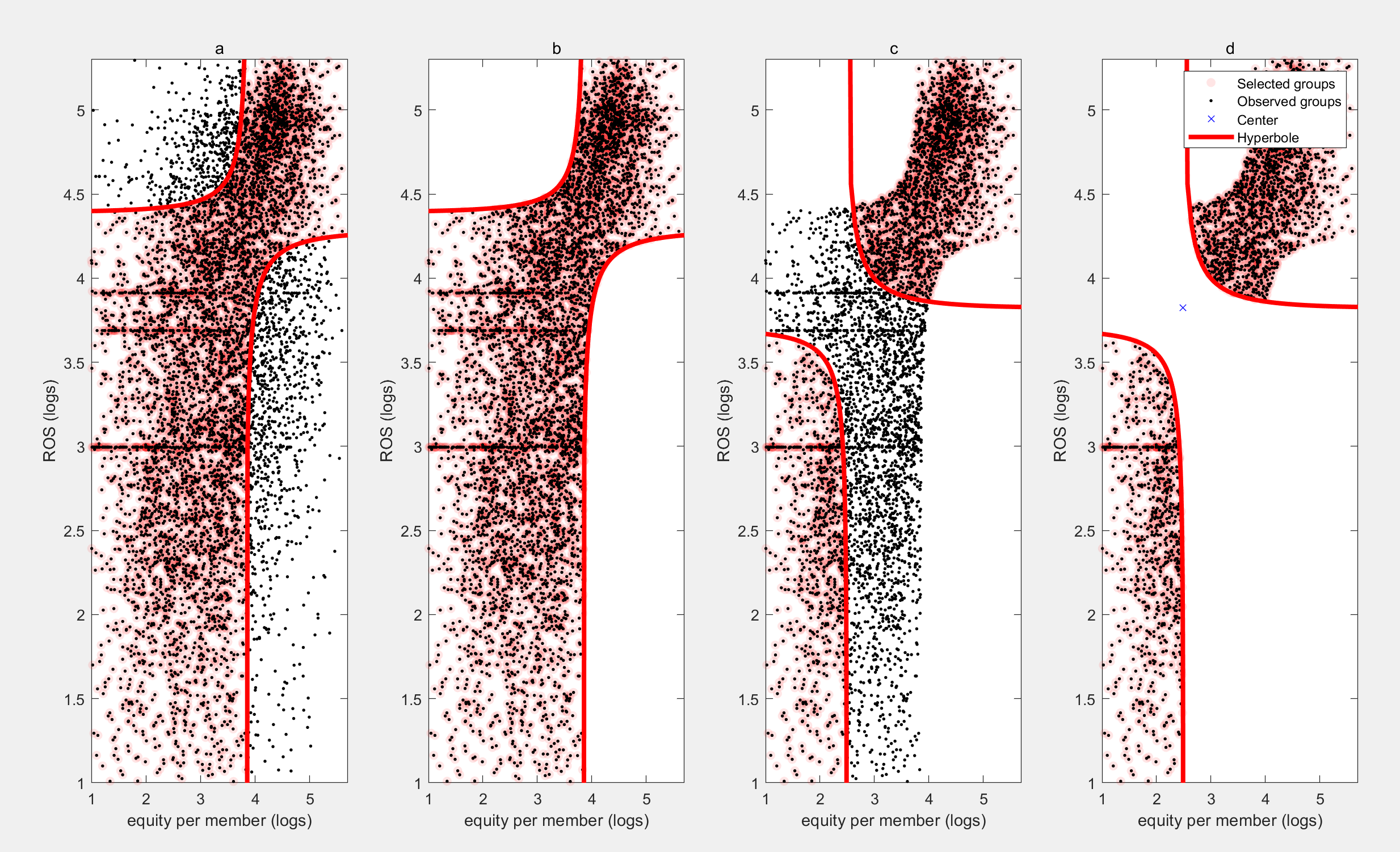
部分代码:
function [w,Smat,alpha,loglik]=BayesLogRegressionRVM(phi,c,w,alpha,opts)
%BAYESLOGREGRESSIONRVM Bayesian Logistic Regression with the Relevance Vector Machine
%[w,Smat,alpha,loglik]=BayesLogRegressionRVM(phi,c,w,alpha,opts)
% Bayesian Logistic Regression
%
% Inputs:
% phi : M*N matrix of phi vectors on the N training points
% c : N*1 vector of associated class lables (0,1)
% w : initial weight vector
% alpha : initial regularisation vector
% opts.HypUpdate : 1 for EM, 2 for Gull-MacKay
% opts.HypIterations : number of hyper parameter updates
% opts.NewtonIterations : number of Newton Updates
%
% Outputs:
% w : learned posterior mean weight vector
% Smat : posterior covariance
% alpha : learned regularisation vector
% loglik : log likelihood of training data for optimal parameters
import brml.*
s=2*c(:)-1; [M, N]=size(phi);
for alphaloop=1:opts.HypIterations
for wloop=1:opts.NewtonIterations % Newton update for Laplace approximation
sigmawh = aux_sigma(s.*(phi'*w));
gE=alpha.*w; J=zeros(M);
tmp=zeros(N,1);
for n=1:N
gE = gE-(1-sigmawh(n))*phi(:,n).*s(n);
J = J + sigmawh(n)*(1-sigmawh(n))*phi(:,n)*phi(:,n)';
end
Hess= diag(alpha)+ J;
w = w-inv(Hess)*gE;
end
Smat = inv(Hess);
L(alphaloop)=-0.5*w'*diag(alpha)*w+sum(log(aux_sigma(s.*(phi'*w))))-0.5*aux_logdet(Hess)+0.5*sum(log(alpha));
switch opts.HypUpdate
case 1
alpha = 1./(w.*w+diag(Smat)); % EM update
case 2
alpha = min(10000,(ones(M,1)-alpha.*diag(Smat))./(w.*w)); % MacKay/Gull update
end
if opts.plotprogess
subplot(1,3,1); plot(L); title('likelihood');
subplot(1,3,2); plot(log(alpha)); title('log alpha');
subplot(1,3,3); bar(w); title('mean weights');drawnow
end
end
loglik=L(end);
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]刘治宇.带通信号欠采样-滤波数字化机理及正交解调技术研究[D].哈尔滨工业大学,2000.
[2]周楠.5GSPS高分辨率数据采集与处理关键技术研究[D].电子科技大学,2019.


















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









