






AUC(Area under the Curve of ROC)是ROC曲线下方的面积,判断二分类模型优劣的标准。
ROC(receiver operating characteristic curve)接收者操作特征曲线,是由二战中的电子工程师和雷达工程师发明用来侦测战场上敌军载具(飞机、船舰)的指标,属于信号检测理论。
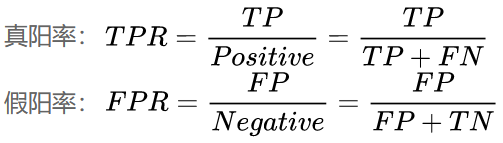
ROC曲线的横坐标是伪阳性率(也叫假正类率,False Positive Rate),纵坐标是真阳性率(真正类率,True Positive Rate),相应的还有真阴性率(真负类率,True Negative Rate)和伪阴性率(假负类率,False Negative Rate)。
伪阳性率(FPR):实际为阴性的样本中,被错误地判断为阳性的比率。
真阳性率(TPR):实际为阳性的样本中,被正确地判断为阳性的比率。
伪阴性率(FNR):实际为阳性的样本中,被错误的预测为阴性的比率。
真阴性率(TNR):实际为阴性的样本中,被正确的预测为阴性的比率。
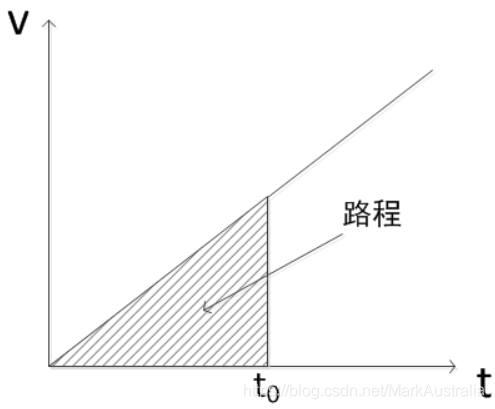
可将ROC类比速度和路程的图像
ROC图从直观上看能得出两个结论:曲线点越接近右下角表示当前阈值预测正例出错的概率越高,准确性较低;曲线点越接近左上角则代表预测正例出错的概率越低,准确性较高。
时间速度曲线是连续的,而ROC曲线是由一组离散的点组成,因为在一般情况下,分类的样本空间有限。其点总数其实就是样本总数,y轴最小步长为1/样本正例数,x轴的最小步长则是1/样本负例数。
假设有一个训练好的二分类器对10个正负样本(正例5个,负例5个)预测,得分按高到低排序得到的最好预测结果为[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],即5个正例均排在5个负例前面,正例排在负例前面的概率为100%。然后绘制其ROC曲线,由于是10个样本,除开原点我们需要描10个点,如下: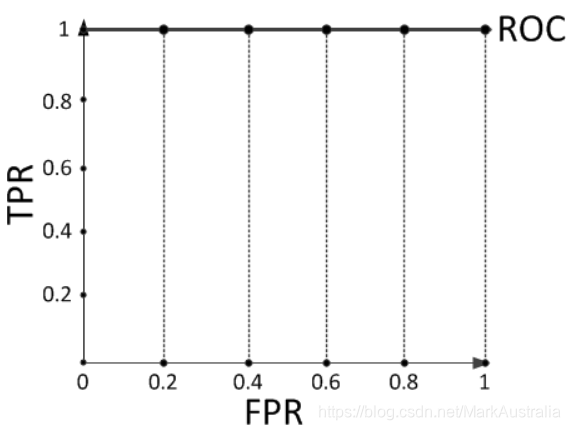
描点方式按照样本预测结果的得分高低从左至右开始遍历。从原点开始,每遇到1便向y轴正方向移动y轴最小步长1个单位,这里是1/5=0.2;每遇到0则向x轴正方向移动x轴最小步长1个单位,这里也是0.2。不难看出,上图的AUC等于1,印证了正例排在负例前面的概率的确为100%。
预测结果序列为[1, 1, 1, 1, 0, 1, 0, 0, 0, 0]
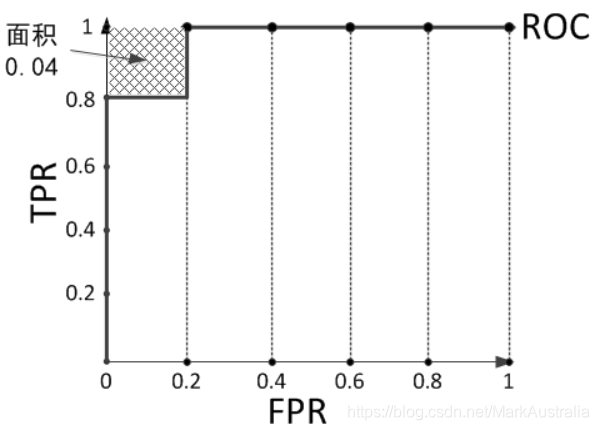
上图的AUC为0.96与计算正例与排在负例前面的概率0.8 × 1 + 0.2 × 0.8 = 0.96相等,而左上角阴影部分的面积则是负例排在正例前面的概率0.2 × 0.2 = 0.04。
AUC相当于给定最小时间单位下分段递增匀速运动时间速度曲线的路程积分问题。
TPR相当于速度,每段“时间”的起始TPR越高,这段“时间”内正例排在负例前面的概率也就越大,这个概率就是路程;FPR则相当于时间,每次旅行总会结束,而FPR也总会到达100%(x值为1),FPR每向x轴正方向移动一步,相当于离“旅行结束”又近了一步。
KS值(Kolmogorov-Smirnov)是在模型中用去区分尝试正负样本分隔程度的评价指标。
KS取值范围是【0,1】。通常值越大,表明正负样本区分度越好。并非所有情况都是KS越高越好。
在模型构建初期KS基本要满足在0.3以上。后续模型监测期间,如果KS持续下降恶化,就要考虑是市场发生了变化所致,或者是客群发生了偏移,或者是评分卡模型不够稳定,或者是评分卡内的某个特征变量发生重大变化所致。如果KS下降至阈值之下,而无法通过重新训练模型进行修正的话,就要考虑上新的评分卡模型代替旧的版本。
不仅评分卡模型整体分数要进行KS的监测,模型内的每个特征变量同样要进行KS监测,这样就能立即发现究竟是模型整体发生恶化,还是单一某个特征变量区分能力在恶化。如果仅仅是单一某个特征变量区分能力在恶化的话,可以考虑更换特征变量或者剔除特征变量的方法进行修正。
征信模型中,最期望得到的信用分数分布是正态分布,对于正负样本分别而言,也都是期望呈正态分布的样子。如果KS值过大,一般超过0.9,就可以认为正负样本分的过开了。不太可能是正态分布,反而是比较极端化的分布状态(U字形,两边多,中间少),这样的分数就不很好,基本可以认为不可用。但如果模式的目的就是完美区分正负样本,那么KS值越大就表明分隔能力越突出。另外,KS值所代表的仅仅是模型的分隔能力,并不代表样本是准确的,即正负样本完全分错,但KS值可以依然很高。
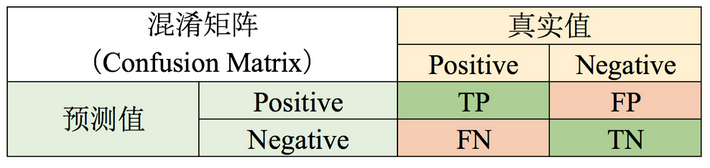
Accuracy = (TP + TN) / (TP + FP + FN + TN)
Precision = TP / (TP + FP); Recall = TP / (TP + FN)
F1 = 2 * Precision * Recall / (Precision + Recall)
PSI,群体稳定性指标(population stability index)
psi = sum((实际占比-预期占比)* ln(实际占比/预期占比) )
如训练一个logistic回归模型,预测时候会有个类概率输出p。在测试数据集上的输出设定为p1,将从小到大排序后将数据集10等分(每组样本数一直,此为等宽分组),计算每等分组的最大最小预测的类概率值。在用模型对新样本预测,结果为p2,用刚才在测试数据集上得到的10等分每等分的上下界。按p2将新样本划分为10分(不一定等分了)。实际占比就是新样本通过p2落在p1划分出来的每等分界限内的占比,预期占比就是测试数据集上各等分样本的占比。
意义就是如果模型稳定,那在新数据上预测所得类概率应该与建模分布一致,这样落在建模数据集所得的类概率所划分的等分区间上的样本占比应该和建模时一样,否则说明模型变化,一般来自预测变量结构变化,通常用作模型效果监测。
一般认为PSI小于0.1时候模型稳定性很高,0.1-0.2一般,需要进一步研究,大于0.2模型稳定性差,建议修复。
参考:
https://blog.youkuaiyun.com/cherrylvlei/article/details/80789379(KS)
https://zhuanlan.zhihu.com/p/79934510(KS)
https://blog.youkuaiyun.com/weixin_39718665/article/details/79198512(PSI)
https://blog.youkuaiyun.com/qq_15111861/article/details/83859737(PSI)

















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









