







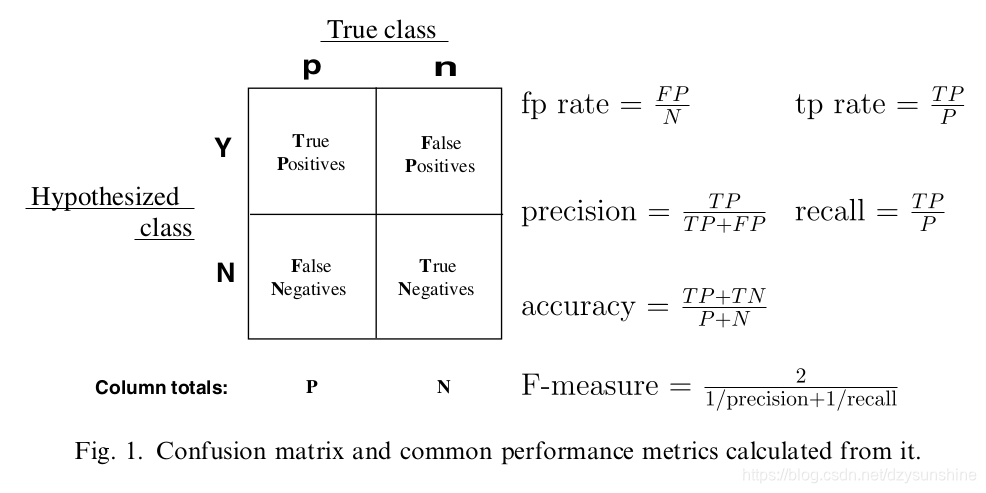
1. FPR和TPR
TPR表示正阳率,FPR表示假阳率。
2. KS曲线与KS值
KS曲线是用来衡量分类型模型准确度的工具。KS曲线与ROC曲线非常的类似。其指标的计算方法与混淆矩阵、ROC基本一致。它只是用另一种方式呈现分类模型的准确性。KS值是KS图中两条线之间最大的距离,其能反映出分类器的划分能力。
KS曲线是两条线,其横轴是阈值,纵轴是TPR与FPR。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
KS值
KS值是MAX(TPR - FPR),即两曲线相距最远的距离。
KS曲线与ROC曲线的区别
KS曲线就是把ROC曲线由原先的一条曲线拆解成了两条曲线。原先ROC的横轴与纵轴都在KS中变成了纵轴,而横轴变成了不同的阈值。
横轴的计算
横轴的指标,是阈值(Threshold)。
分类器的输出一般都为[0,1]之间的概率(Possibilities),那么多少几率我们认为会发生事件,多少几率我们认为不会发生事件。界定“发生”与“不发生”的临界值,就叫做阈值。
比如,我们认为下雨几率高于(含等于)0.7时,天气预报就会显示有雨;而下雨几率低于0.7时,天气预报就不会显示有雨。那么这个0.7,就是阈值。他也是KS曲线的横轴。
纵轴的计算
KS曲线中有两条线,这两条线有共同的横轴,但是纵轴分别有两个指标:FPR与TPR。
KS曲线的解读
KS(Kolmogorov-Smirnov)用于模型风险区分能力进行评估,
指标衡量的是好坏样本累计分部之间的差值。
好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。
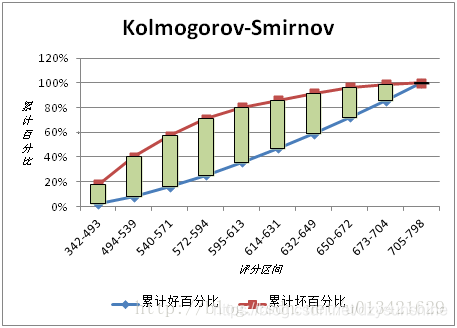
KS的计算步骤如下:
- 计算每个评分区间的好坏账户数。
- 计算每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%)。
- 计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计good%-累计bad%),然后对这些绝对值取最大值即得此评分卡的K-S值。
3. ROC曲线
对于一个特定的分类器和测试数据集,显然只能得到一个分类结果,即一组FPR和TPR结果,而要得到一个曲线,我们实际上需要一系列FPR和TPR的值才能得到这样的曲线,这又是如何得到的呢?
可以通过分类器的一个重要功能“概率输出”,即表示分类器认为某个样本具有多大的概率属于正样本(或负样本),来动态调整一个样本是否属于正负样本(还记得当时阿里比赛的时候有一个表示被判定为正样本的概率的列么?)
假如我们已经得到了所有样本的概率输出(属于正样本的概率),现在的问题是如何改变这个阈值(概率输出)?我们根据每个测试样本属于正样本的概率值从大到小排序。下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。 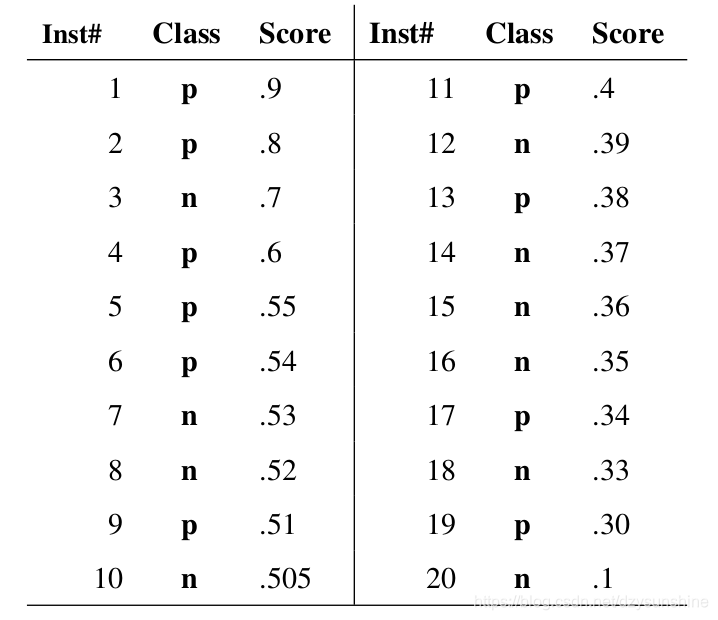
接下来,我们从高到低,依次将“Score”值作为阈值,当测试样本属于正样本的概率大于或等于这个阈值时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的阈值,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图: 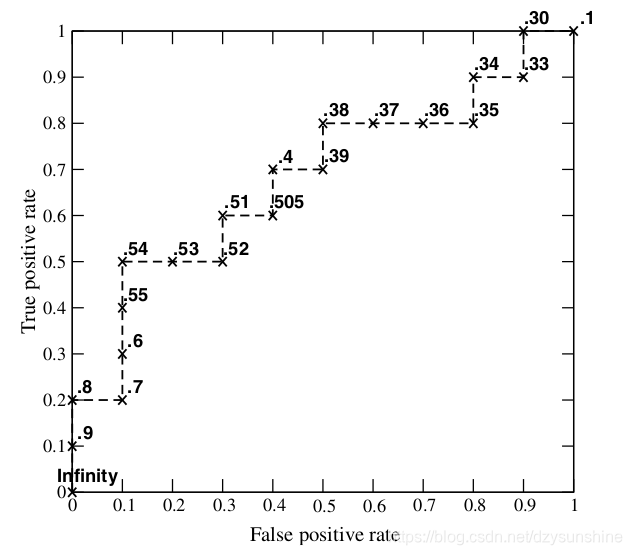
当我们将阈值设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当阈值取值越多,ROC曲线越平滑。
ROC曲线的优点
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线的对比:
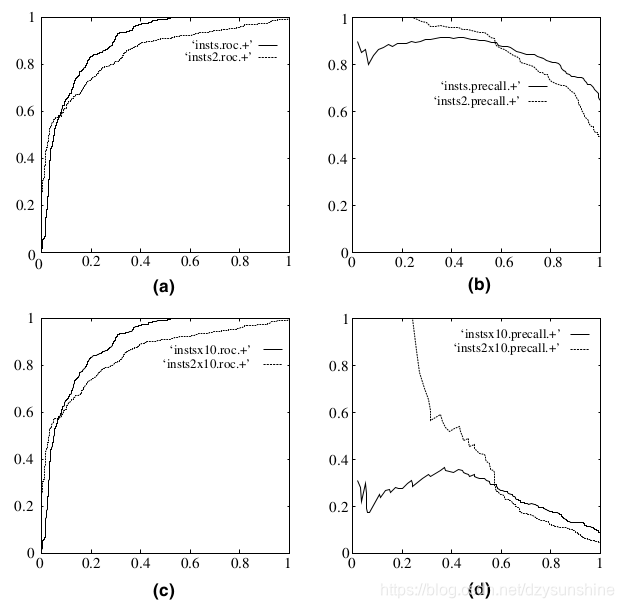
在上图中,(a)和©为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,©和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。

















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









