






 这篇博客深入解析了SAC算法的改进版本,主要亮点在于引入了自动调节的温度因子α,提升了训练速度和稳定性。作者取消了原SAC中的VVV网络,仅保留QQQ网络,减少了计算资源。通过动态调整α,算法在探索与利用之间找到了更好的平衡,解决了超参数调节的难题。实验表明,这些改变对Off-policy算法的性能有显著提升。
这篇博客深入解析了SAC算法的改进版本,主要亮点在于引入了自动调节的温度因子α,提升了训练速度和稳定性。作者取消了原SAC中的VVV网络,仅保留QQQ网络,减少了计算资源。通过动态调整α,算法在探索与利用之间找到了更好的平衡,解决了超参数调节的难题。实验表明,这些改变对Off-policy算法的性能有显著提升。
这篇论文是SAC原作者在SAC上进行改进之后的算法。改进后的SAC在训练速度、稳定性、表现力方面都得到了一定的提升。
论文地址,点这里
TF源码,点这里
PyTorch源码,点这里
改进的方面主要是2部分:
- 引入自动调节的温度因子 α \alpha α。
- 取消了原SAC中的 V V V网络,只是用 Q Q Q网络。
学习这篇论文的前提是要对原SAC有一定了解,以下默认对SAC有一定基础,需要了解第一版SAC论文的同学可参考我的另一篇论文解读:论文笔记之SAC。
该版本的SAC可作为SAC的最终版代码,相比原SAC代码,显然自动调节的
α
\alpha
α的引入是不错的改善。另外在保证了算法稳定性的基础上,取消了
V
V
V网络的训练,节约了计算资源。
Soft Actor-Critic Algorithms and Applications
Abstract
- SAC的作者对原SAC进行了修改——设计了自动调节的温度因子 α \alpha α。
- SAC的改进有助于提升训练速度、提升Off-policy算法的稳定性。
1 Introduction
- 限制Model-free算法表现力的在于其采样复杂度高,即需要成百上千万steps的采样量进行学习,对于更复杂的环境,则需要更多的steps。其次,model-free算法对于超参数十分敏感,不同的值造成表现力的差异还是挺大的,因此超参数的调节也是个问题。
- On-policy算法一直以来都以采样效率低著称,所以Off-policy的优势更大,其采样效率高,利用率高,一般都会有个经验池 D \mathcal{D} D来提供重复利用。但是这里提一下,衡量是否为Off-policy的标准是行为策略和目标策略是否一致,而不是是否有经验池。
- Off-policy的缺陷就是会导致算法稳定性降低,有时候较难收敛,出现过拟合现象。
- SAC是一种Off-policy算法,采样效率高,探索能力强,关键是作者指出对于SAC来说,reward-scaling是唯一需要调节的超参数(参考原论文第五节实验部分的Reward scale部分)。对于稳定性,SAC是一种随机性策略方法,实验表明其稳定性要高于一般的Off-policy的确定性策略算法,如DDPG。另外Target网络也可以提升算法稳定性。总之原SAC算法是一种有助于解决model-free算法缺陷的算法。
- SAC有一大缺陷就是对reward-scaling的调节非常敏感,这个超参数也可以转移到温度因子 α \alpha α上,两者调节其一就行。作者选择了后者进行研究,设计了自动调节 α \alpha α的算法。结果就是这个改进减轻了超参数调节的难度以及在表现力和采样效率上都得到了进一步提升!
2 Related work
略
3 Preliminaries
这部分介绍了SAC的目标函数以及最大含熵目标带来的好处,详细请看SAC原论文,故略。
4 From Soft Policy Iteration to Soft AC
这部分介绍了SAC算法理论上的策略评估和策略提升以及实践中的神经网络化处理等,除了策略评估中省去了
V
V
V网络的优化以外,其余都没变,详细请看SAC原论文,故略。
Note:
- 这篇改进论文只使用了 Q Q Q网络,而没有 V V V网络,目标函数仍和之前一样使用最小二乘误差: J Q ( θ ) = E ( s t , a t ) ∼ D [ 1 2 ( Q θ ( s t , a t ) − ( r ( s t , a t ) + γ E s t + 1 ∼ p [ V θ ˉ ( s t + 1 ) ] ) ) 2 ] (5) J_Q(\theta)=\mathbb{E}_{(s_t,a_t)\sim\mathcal{D}}[\frac{1}{2}(Q_\theta(s_t,a_t)-(r(s_t,a_t)+\gamma\mathbb{E}_{s_{t+1}\sim p}[V_{\bar{\theta}}(s_{t+1})]))^2]\tag{5} JQ(θ)=E(st,at)∼D[21(Qθ(st,at)−(r(st,at)+γEst+1∼p[Vθˉ(st+1)]))2](5),那么单样本更新方式为: ∇ θ J Q ( θ ) = ∇ θ Q θ ( s t , a t ) ( Q θ ( s t . a t ) − ( r ( s t , a t ) + γ ( Q θ ˉ ( s t + 1 , a t + 1 ) − α log ( π ϕ ( a t + 1 ∣ s t + 1 ) ) ) ) ) (6) \nabla_\theta J_Q(\theta)=\nabla_\theta Q_\theta(s_t,a_t)(Q_\theta(s_t.a_t)-(r(s_t,a_t)+\gamma(Q_{\bar{\theta}}(s_{t+1},a_{t+1})-\alpha\log(\pi_\phi(a_{t+1}|s_{t+1})))))\tag{6} ∇θJQ(θ)=∇θQθ(st,at)(Qθ(st.at)−(r(st,at)+γ(Qθˉ(st+1,at+1)−αlog(πϕ(at+1∣st+1)))))(6)
5 Automating Entropy Adjustment for Maximum Entropy RL
这一节才是改论文要讲的重点(3-4节、附录和SAC论文一模一样,感觉像凑字数)。
作者改变了原SAC的最大含熵目标函数,将熵项提到外面作为一项约束处理(entropy-constrained),然后最大化期望累计奖励:
max
π
0
:
T
E
ρ
π
[
∑
t
=
0
T
r
(
s
t
,
a
t
)
]
s
.
t
.
E
(
s
t
,
a
t
)
∼
ρ
π
[
−
log
(
π
t
(
a
t
∣
s
t
)
)
]
≥
H
,
∀
t
(11)
\max_{\pi_{0:T}}\mathbb{E}_{\rho^\pi}[\sum^T_{t=0}r(s_t,a_t)]\\ s.t.\,\,\mathbb{E}_{(s_t,a_t)\sim\rho^\pi}[-\log(\pi_t(a_t|s_t))]\ge\mathcal{H},\,\,\,\forall t\tag{11}
π0:TmaxEρπ[t=0∑Tr(st,at)]s.t.E(st,at)∼ρπ[−log(πt(at∣st))]≥H,∀t(11)对于含约束项的极值问题,我们一般采用拉格朗日乘子法来解决。然后这个优化问题需要转为原问题与其对偶问题来解决。关于对偶问题的理解,也可以参考西瓜书附录里的介绍。
Note:
- 式(11)中的 H \mathcal{H} H是个常数,是个可以预先设置的最小熵。
具体优化过程的推导如下:

Note:
- 最终优化结果: α t ∗ = arg min α t E ρ t ∗ [ − α t log π t ∗ ( a t ∣ s t ) − α t H ˉ ] (17) \alpha^*_t=\argmin_{\alpha_t}\mathbb{E}_{\rho^*_t}[-\alpha_t\log\pi_t^*(a_t|s_t)-\alpha_t\bar{\mathcal{H}}]\tag{17} αt∗=αtargminEρt∗[−αtlogπt∗(at∣st)−αtHˉ](17)其中 H ˉ \bar{\mathcal{H}} Hˉ就是上面说的最小熵常量。 ρ t ∗ \rho^*_t ρt∗表示当前(最优)策略 π \pi π经历的状态动作对,所以也可以写成论文中的 a t ∼ π t ( s t ) a_t\sim\pi_t(s_t) at∼πt(st)。
- 可以看出 α t \alpha_t αt的优化是对以每一个step而言的。
- 算法的优化是将温度因子 α \alpha α看成是对偶变量 λ \lambda λ。因为拉格朗日对偶问题的最优解就是对偶变量的最优值 λ ∗ \lambda^* λ∗,这样的话我们的问题优化出来的就是 α ∗ \alpha^* α∗。
- 以上虽然只推到了2个steps,但足以说明一般化了,之后只要继续往回不断递归,就可以成功解决式(11)的优化问题。
- 在实际实现过程中,由于
α
t
\alpha_t
αt随着时间步变化(自变量就是时间步
t
t
t),这和我们的
Q
t
(
s
t
,
a
t
)
Q_t(s_t,a_t)
Qt(st,at)的优化是一样,如下面的优化结果所示:
π
T
−
1
∗
=
arg max
π
T
−
1
{
E
ρ
π
T
−
1
[
Q
T
−
1
∗
(
s
T
−
1
,
a
T
−
1
)
−
α
T
−
1
log
π
(
a
T
−
1
∣
s
T
−
1
)
−
α
T
−
1
H
ˉ
]
}
α
T
−
1
∗
=
arg min
α
T
≥
0
{
E
ρ
π
T
−
1
∗
[
−
α
T
−
1
log
π
T
−
1
∗
(
a
T
−
1
∣
s
T
−
1
)
−
α
T
−
1
H
ˉ
]
}
\pi^*_{T-1}=\argmax_{\pi_{T-1}}\{\mathbb{E}_{\rho^{\pi_{T-1}}}[Q^*_{T-1}(s_{T-1},a_{T-1})-\alpha_{T-1}\log\pi(a_{T-1}|s_{T-1})-\alpha_{T-1}\bar{\mathcal{H}}]\}\\\alpha_{T-1}^*=\argmin_{\alpha_T\ge0}\{\mathbb{E}_{\rho^{\pi^*_{T-1}}}[-\alpha_{T-1}\log\pi^*_{T-1}(a_{T-1}|s_{T-1})-\alpha_{T-1}\bar{\mathcal{H}}]\}
πT−1∗=πT−1argmax{EρπT−1[QT−1∗(sT−1,aT−1)−αT−1logπ(aT−1∣sT−1)−αT−1Hˉ]}αT−1∗=αT≥0argmin{EρπT−1∗[−αT−1logπT−1∗(aT−1∣sT−1)−αT−1Hˉ]}虽然一开始的
α
∗
\alpha^*
α∗都更新的不是很准确,因为
π
∗
\pi^*
π∗也是不准确的,但是慢慢地到后来,随着时间步增大,随着episodes增多就会准确起来。
α
\alpha
α的这种递归方法就是
动态规划(DP)算法,我们求 Q Q Q也是从DP开始的。观察式(17),所求 α \alpha α是优化目标的参数,有期望——因此综上所述,完全可以把 α \alpha α当成和 Q Q Q一样对待:①对 α \alpha α设置网络。②对式(17)实行随机梯度更新 α \alpha α。具体如下: J ( α ) = E a t ∼ π t [ − α t log π t ( a t ∣ s t ) − α H ˉ ] α ← α − η ⋅ ∇ α J ( α ) (18) J(\alpha)=\mathbb{E}_{a_t\sim\pi_t}[-\alpha_t\log\pi_t(a_t|s_t)-\alpha\bar{\mathcal{H}}]\\\alpha\gets\alpha-\eta\cdot\nabla_\alpha J(\alpha)\tag{18} J(α)=Eat∼πt[−αtlogπt(at∣st)−αHˉ]α←α−η⋅∇αJ(α)(18)这里 a t a_t at采样于当前策略 π ( s t ) \pi(s_t) π(st), s t s_t st采样于经验池的mini-batch个经验。 - 最小熵(entropy target)设置为
H
ˉ
=
−
d
i
m
(
A
)
\bar{\mathcal{H}}=-dim(\mathcal{A})
Hˉ=−dim(A),及动作空间维度的相反数。
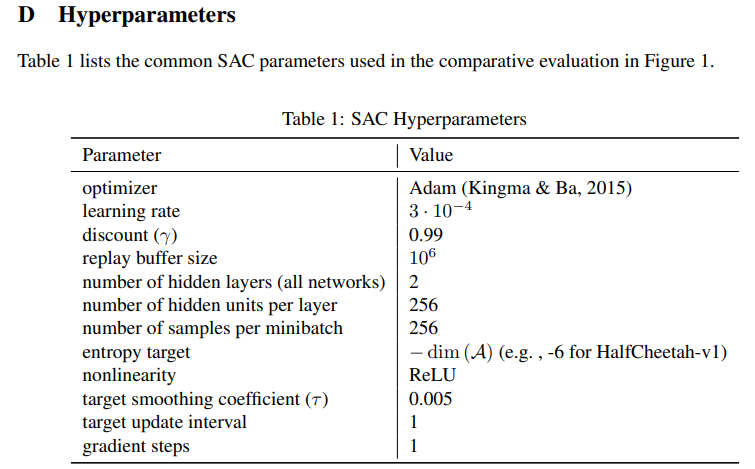
伪代码如下:

总体而言和原SAC基本相似,下面写一下不同之处
Note:
- 第一处就是设置了自动调节的温度因子 α \alpha α。
- 取消了Target V V V网络,只使用 Q Q Q网络。虽然SQL论文中也没有 V V V网络,但却和本文的不同: Q s o f t θ ˉ ( s t , a t ) = r ( s t , a t ) + γ E s t + 1 ∼ p [ V θ ˉ ( s t + 1 ) ] V θ ˉ ( s t ) = E a t ∼ π [ Q θ ˉ ( s t , a t ) − log π ( a t ∣ s t ) ] Q^{\bar{\theta}}_{soft}(s_t,a_t)=r(s_t,a_t)+\gamma\mathbb{E}_{s_{t+1}\sim p}[V^{\bar{\theta}}(s_{t+1})]\\V^{\bar{\theta}}(s_t)=\mathbb{E}_{a_t\sim\pi}[Q^{\bar{\theta}}(s_t,a_t)-\log\pi(a_t|s_t)] Qsoftθˉ(st,at)=r(st,at)+γEst+1∼p[Vθˉ(st+1)]Vθˉ(st)=Eat∼π[Qθˉ(st,at)−logπ(at∣st)]可以看出,本文的做法其实相当于忽略了 V V V函数。而SQL中是通过公式 V = α log ∫ A exp ( 1 α Q s o f t ( s t , a ) ) d a V=\alpha\log\int_{\mathcal{A}}\exp(\frac{1}{\alpha}Q_{soft}(s_t,a))\mathrm{d}a V=αlog∫Aexp(α1Qsoft(st,a))da来实现的(具体优化方式见上面的第4节)。另外,上述公式的 p p p实际中就是采样过程中的经验,即同轨策略分布 ρ \rho ρ,实际中我们通过采样来近似。
- 可以看出,伪代码和原SAC的代码并没有设置Actor的Target网络,只有SQL里面设置了。
6 Practical Algorithms
这里上述都讲过了,几个小技巧:
- 采用双Q消除过估计
- 采用随机梯度下降更新自动调节的温度因子 α \alpha α。
7 Experiment
略
8 Conclusion
- 个人认为SAC一个比较吸引人的地方在于,在设置了自动调节的因子之后,几乎就不需要调节任何超参数。
- 引入自动调节的温度因子 α \alpha α,为什么要引入呢?实际上由于reward的不断变化,采用固定的 α \alpha α并不合理,会让整个训练不稳定,因此,有必要能够自动调节这个 α \alpha α。当policy探索到新的区域时,最优的action还不清楚,应该提高 α \alpha α去探索更多的空间。当某一个区域已经探索得差不多,最优的action基本确定了,那么就减小这个温度因子。
- 因此这样变化的温度因子可以平衡探索与利用,以来不会陷入局部最优,而来不会因为 α \alpha α太大导致无法利用,Agent学不到东西。
- 取消了 V V V网络,采用和SQL里类似的使用 Q θ ˉ Q^{\bar{\theta}} Qθˉ来对 Q Q Q值更新。

















 4176
4176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









