 5天速成代谢组学分析挑战
5天速成代谢组学分析挑战





医学生必修课!5天代谢组学分析速成挑战
DAY1!
在孟德尔随机化研究领域,我们已经完成了多项挑战,并且见证了许多追随我们步伐的学者们取得了显著成就,成功发表了自己的SCI论文。
然而,随着孟德尔随机化研究的投稿标准日益提高,大家肯定也发现现在对于孟德尔的要求越来越高,简单的双样本想被接收就是难上加难,如何破除这个困境,我们进一步开启一系列进阶版的孟德尔挑战,旨在提升大家的论文接受率。今天,我们将开启这一新的挑战旅程!
医学生朋友们,尤其是那些尚未发表文章的同学们,是时候行动起来了!加入我们,一起学习,一起进步,共同在科研的道路上迈出坚实的步伐。
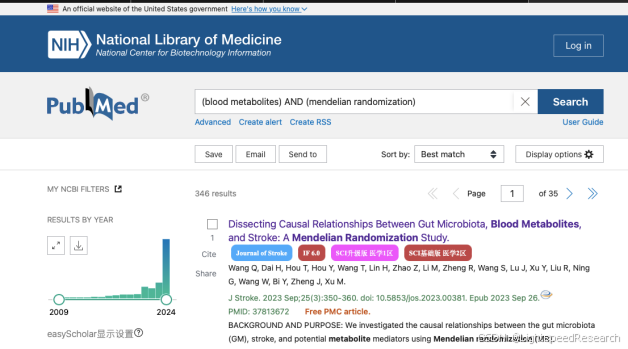
第1天:收集信息。
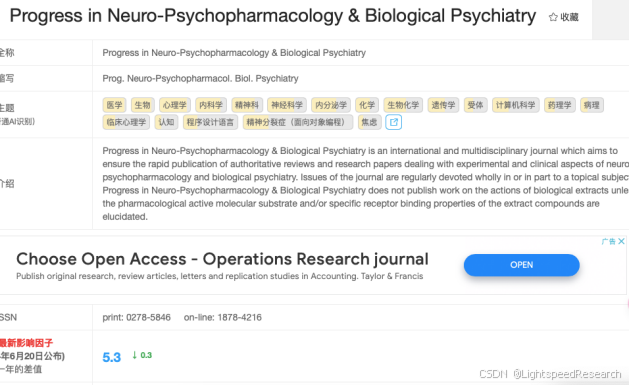
检索关键词:“(plasma metabolome) AND (mendelian randomization)”,发文量、发表的杂志影响因子和分区都还不错,但是目前的趋势都是多组学孟德尔,加大文章的工作量和创新度。
Progress in Neuro-Psychopharmacology & Biological Psychiatry(Q1,5.3),Frontiers in Immunology(Q1,5.7),都是今年发表的Q1级别文章。说明组学孟德尔还是有很大的发挥空间,有条件的师弟师妹还能作为实验或者申报课题的前期准备,甚至可以补充一定的实验作为湿实验验证,那这篇文章就是高分文章了!
面对紧张的学术日程,你们在有限的时间内已经阅读了海量的文献,却常常感到没有足够的空间去探索和实践那些新兴的研究领域。现在,就让我们一起跟随我的思路,开始这段写作之旅吧!
除了搜集信息,我还精选了10余篇近期的组学孟德尔研究范文,准备进行深入研读。今天,我们的挑战就此拉开序幕!
注:本次挑战将安排在非工作时间、考试或原定学习计划之外,大家可以借鉴我的思路,特别适合那些没有固定课题、希望从零开始的同学们!
随着第一天挑战的圆满结束,我们满怀期待地迎接明天更加精彩的内容。敬请期待,精彩即将继续!
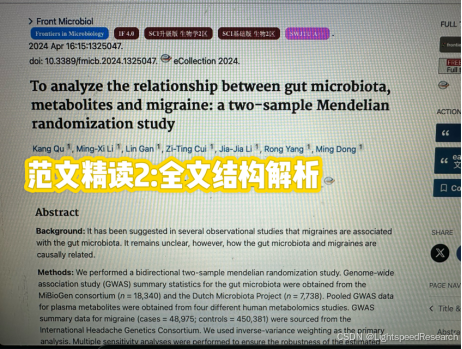


Day 2!
经过初步的文献检索,我对自己的研究选题充满了信心。目前,我选择的疾病领域尚未有文献报道,这意味着我的研究具有创新性和独特性。因此,我必须抓住这一机遇,迅速启动我的研究工作。
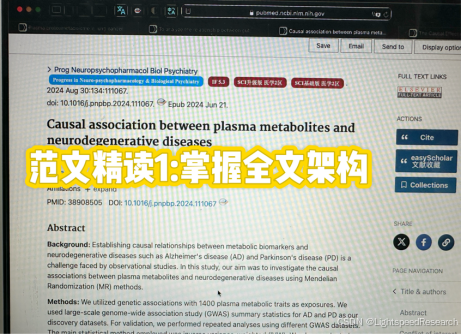
为了确保研究的顺利进行,我精心挑选了三篇最新发表的的文章,都是Q2级别,分数可观,可以进行进一步研究和学习。
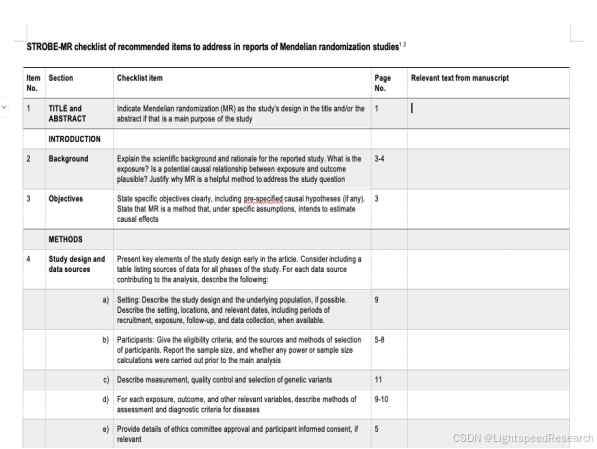
之前的挑战也提到了在学术写作中,遵循行业规范是至关重要的。因此,我特别关注了STROBE-MR声明,这是一项旨在提高研究报告质量和透明度的国际指南。该声明涵盖了六个主要部分:“题目与摘要”(条目1)、“引言”(条目2-3)、“方法”(条目4-9)、“结果”(条目10-13)、“讨论”(条目14-17)以及“其他信息”(条目18-20)。这些条目为我们提供了撰写高质量学术论文的指导和规范。
注释:我鼓励师弟师妹们也积极参与学习,明天,我们将开始运行代码,以进一步推进我们的研究工作。让我们共同努力,以确保我们的研究成果既规范又具有影响力。

Day 3!
今天临床工工作比较忙,但是也不能忘记继续挑战,今天任务不重,把工作交给勤勤恳恳的电脑吧!
我们的代码太给力了,工作交给电脑,我还能去忙别的事情~
今日任务==下载数据+整理数据格式+开始跑代码。
Step1 运用我们提供的小工具处理我们的结局数据,将其整理成标准格式表头,这步还是很关键的,准确的格式是确保最强代码不失误的开端。
Step2 运行内置代码(这个是必须的哦!)→开启第二步运行循环代码→设置工作路径(注意要核对文件数量)→开启跑代码咯(这时候我已经去忙自己的事情)
Hey师弟师妹们!如果你也想挑战一下孟德尔分析的文章,但现在还一头雾水,那我有个小建议:先别急着动笔,先去读一读最近发表的那些高分孟德尔分析文章,至少10篇哦!这样你就能对整个研究流程有个大概的了解。
别忘了,在你开始之前,一定要好好检查一下,看看你的研究点子是不是已经有别人写过了。特别是那些可能藏在别人文章的某个小角落里的,要是不小心撞车了,那你的努力可能就白费了哦!
倒计时两天啦!大家快来围观,一起加油打气,期待你的研究大作哦!


Day 4来啦!
大家好啊!我们的5天代谢组学分析速成挑战已经到了第四天,时间过得真快,但我们的进展可是杠杠的!今天时间比较充裕,那就给自己任务重一些吧!
今天的计划是这样的:
- 数据跑起来:我们的循环代码跑完咯,我们就能拿到一个整理好的汇总表格,离成功又近了一步!这说明我们的所有结果和图表都已经跑出来咯~
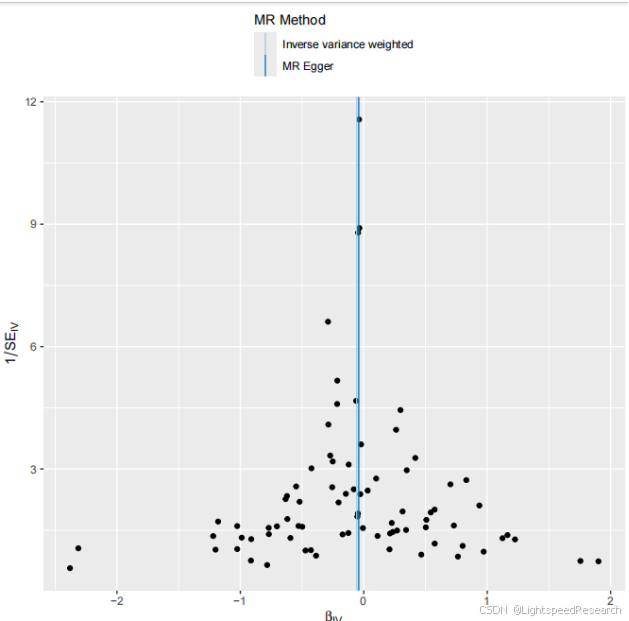
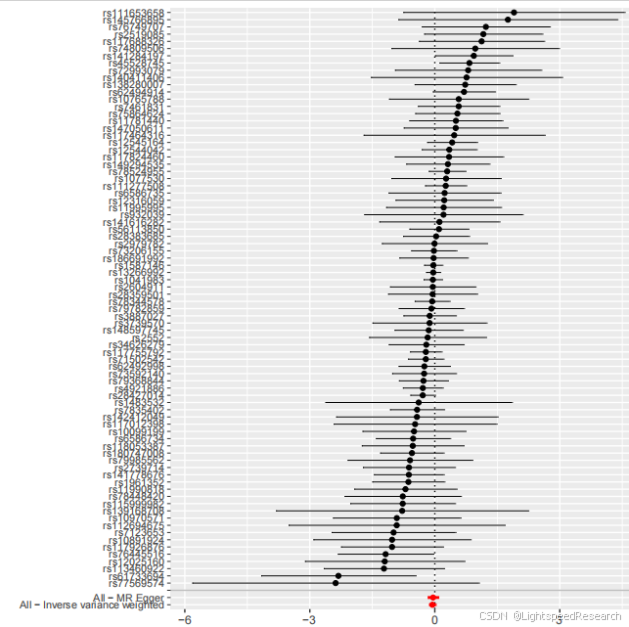
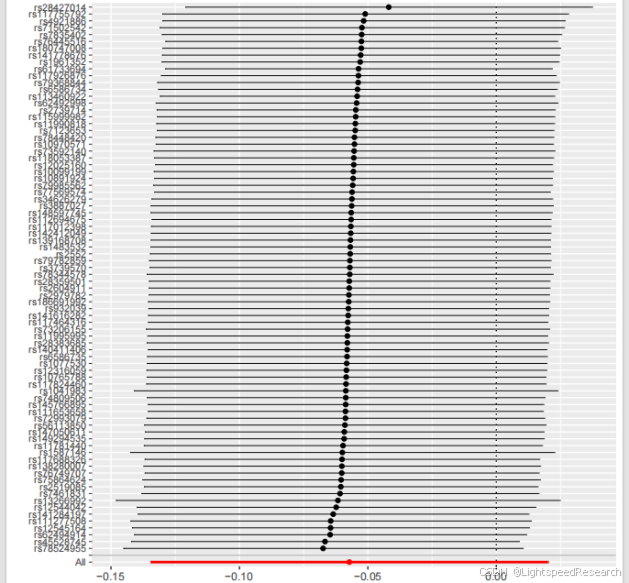
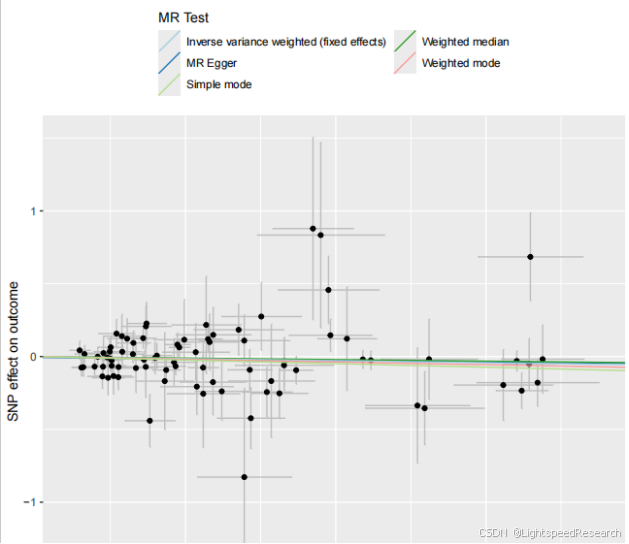
- 数据筛选:筛选出符合我们要求的数据。筛选标准可以根据自己初步的阳性结果数量进一步严格自己的筛选结果,结果分析超级给力。每个代谢物的留一法图、森林图、散点图、漏斗图都已经准备好了,只需要筛选自己想要的结果即可。现在数据要求越来越高,我设的矫正P值要小于0.05,这种筛选标准也比较符合目前审稿人的要求,这感觉真是太棒了!
- 森林图汇总:阳性代谢物结果汇总成一张总的森林图,图片很漂亮~(如果有实验条件的小伙伴们,可以把这作为前期结果,后面做湿实验验证一下,送一些标本代谢组学分析验证一些,这样一篇高分文章就到手啦!)
- 图表汇总:除了绘制图片,还需要将阳性结果整理为表格,包括异质性、多效性等整理,这种就类似一个三线表,把数据从汇总表格复制粘贴即可~
- 高分范文模仿:拿出我们第三天精读的3篇高分孟德尔分析文献,开始模仿写作吧!有了这些优秀范文做榜样,我们的写作也会越来越得心应手!文章的书写方法就是万变不离其宗,掌握方法后它可以适用每种类型文章的写作~
明天就是最后的冲刺了!我们要一口气完成引言部分的写作,还要搞定摘要、文献引用、模板化写作等一系列收尾工作。然后,就可以按照目标期刊的要求,投出我们的稿件啦!
只要我们流程清晰,步步为营,一定能顺利产出满意的分析结果的!第一篇成功了,第二篇、第N篇就都不在话下啦!大家一起加油冲刺吧!



第5天,圆满收官!
嘿,师弟师妹们!
来来来,给你们汇报一下今天的战果!今天我可是大有斩获——搞定了引言部分的写作,还用Endnote20进行了文献引用,连模块化部分的写作(伦理、致谢、利益冲突声明、作者贡献等等)也都一并搞定了。最后,我还给我的文章来了个美容大法——润色了一遍。看着自己的劳动成果,成就感简直爆棚!
回头看看这次挑战,其实写一篇孟德尔分析的文章,大概就这么几个步骤:
1.确定选题:这步超级重要,得先搜搜文献,看看你的疾病领域有没有人写过,得创新,得独一无二。选好疾病,挑几篇高分的文章好好读读。
2.数据整理与分析:跟着我们的资料和视频教程,一步步来。资料全,讲解清楚,下载你的疾病数据,用我们的小工具整理好,再用我们的代码分析。电脑跑程序的时间因人而异,别急,慢慢来。
3.阳性代谢物筛选与后续分析:按要求挑出阳性结果,可以严格点。然后整理图片,直观展示结果。再做汇总森林图和表格。
4.文章撰写:最后,就按照STROBE-MR声明的指导和范文,完成孟德尔分析的文章。这一步得按结构和格式来,保证报告完整、好读。
以上就是代谢组学分析的基本流程啦!你们可以照着我这几天分享的思路去写自己的论文。相信跟着这个流程,一定能写出一篇高质量的孟德尔分析论文!目前的趋势是多组学孟德尔,所以大家可以融合多组学进行验证,甚至融合中介分析,发现进一步深入的关联~
最后,虽然这次挑战结束了,但科研的路还长着呢。希望大家都能保持对知识的热爱和好奇心,不断学习新方法、新技能。加油,科研小达人们!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









