





医学生集合啦,继续挑战 7天一篇nhanes机器学习SCI!
Day 1
进展:确定选题、期刊、文献
前面挑战了一期NHANES机器学习,大家使用NHANES的发文章的热情,火爆程度远超想象!我在下面的评论区看到大家的学习欲爆,也有师妹在私信我,问我能不能继续挑战。我这次依然是继续挑战使用nhanse数据库的数据写SCI,师弟师妹们太刻苦了,搞得我的pressure倍增
实际上是NHANES的高阶内容,数据始终是那些数据,该怎么用起来呢?公开数据库最难的点是数据的清洗,必须要认识到数据的结构和类型,如果我要去使用的话,我应该怎么去提取
经过大家的监督,我也成功挑战了多期GBD、NHANES的论文,大家会发现:方法学一定是最简单的,只要足够的时间和精力就一定能掌握的,这点challenge对于医学生而言简直小菜一碟。融入了机器学习这一个热点,即使以前自己处理过的或者已经发表过文章的数据,还能再次用来尝试这个一新的方法,也是一个新的方向,特别是对于我们这些“资源”较少的朋友来说
机器学习、人工智能一定是未来的方向,从诺贝尔奖到Pubmed那么多的高分文章来看,一定要抓住这一波机会
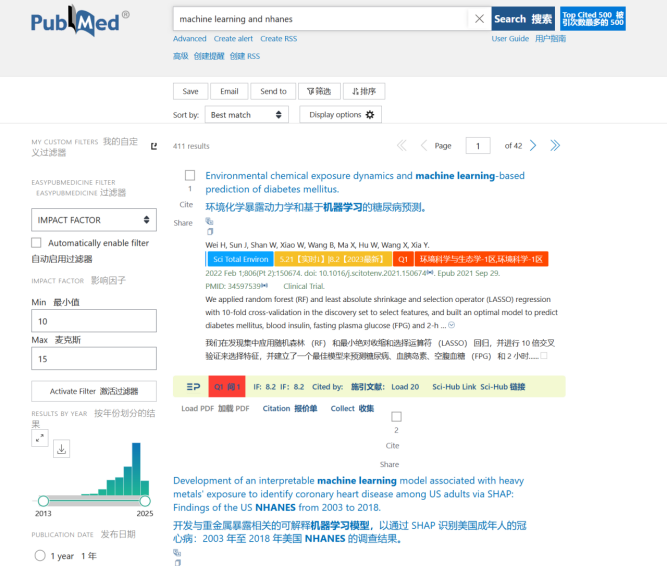
简单一搜,出来的文章可不简单,数量和质量都让人震惊。ML=machine learning,其中XGBOOST、随机森林等等单一模型的文章,还有多种、10种、100多种模型相互比较的文章。也会面临一个现实且严峻的问题,“我一个学医的,懂啥算法啊”但实际上这个担心我个人觉得有点儿多余,因为,他,新!整因为他新,所以所有人都在同一个起跑线!!或者说我只要能够使用数据跑的出来结果,能够解释结果,发几篇SCI文章,完全绰绰有余
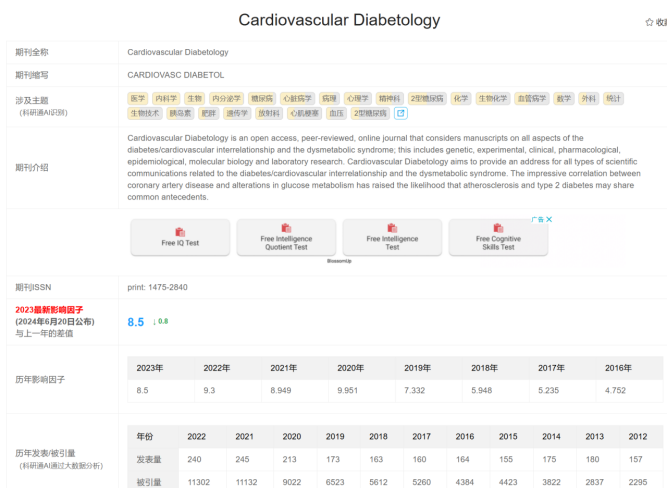
先定方向,写文章之前一定要有目标文章,因为做NHANES机器学习,结合自己也是搞心脏多一些,所以我选的期刊是Cardiovascular Diabetolog Q1区 8.5分的文章,发文量也比较的稳定,这个杂志熟悉的都知道,对于NHANES数据库还是非常有好的,上面也有很多机器学习的文章,这个文章是协和团队的成果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2248
2248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









