



一. 什么是大模型微调?与预训练的核心区别是什么?
答:(1) 预训练模型是指大模型首先通过海量通用数据(如互联网文本)进行预训练,学习通用的语言表示和知识。大模型微调(Fine-tuning)是指在预训练大模型的基础上,通过特定任务的数据对模型进行进一步训练,使其适应特定任务或领域的过程。
(2)预训练 vs 微调:核心区别
| 维度 | 预训练 | 微调 |
| 目标 | 学习通用表征(语言规律、世界知识),构建“基础智能” | 适配具体任务(如分类、生成),提升任务性能 |
| 数据 | 海量无标注/弱标注的通用数据(TB级,如全网文本) | 少量任务相关的标注数据(MB/GB级,如几千条样本) |
| 训练方式 | 自监督学习(如掩码语言模型MLM、因果语言模型CLM) | 有监督学习(或继续自监督,但目标与任务绑定) |
| 参数调整范围 | 全参数训练(模型所有参数参与更新) | 全参数或部分参数调整(如仅调优最后几层,或用LoRA等技术冻结部分参数) |
| 计算成本 | 极高(需数千GPU/TPU,耗时数周/月) |
较低(通常仅需少量GPU,耗时数小时/天) |
| 输出能力 | 通用语言理解/生成(但缺乏任务针对性) | 任务专用能力(如精准分类、符合要求的生成) |
二. 微调的核心步骤有哪些?
答:(1)确定任务目标:明确微调的具体任务和需求。(2)准备数据:收集和预处理任务相关数据。(3)选择预训练模型:选择适合任务的预训练模型。(4)设置微调环境:配置硬件和软件环境。(5)配置微调参数:设置微调的超参数和训练策略。(6)训练模型:在任务数据上微调模型。(7)评估与验证:评估微调模型的性能。(8)部署与应用:将微调后的模型部署到实际场景中。
三. 常见的微调方法有哪些?
1.全量微调(Full Fine-tuning)
-
核心:用任务数据调整所有预训练参数(包括底层编码器)。
-
特点:适合小模型(如BERT-base)或小数据集,性能上限高,但大模型(如GPT-3)成本极高(需千卡集群)。
2.低秩矩阵微调Lora(Low-Rank Adaptation)
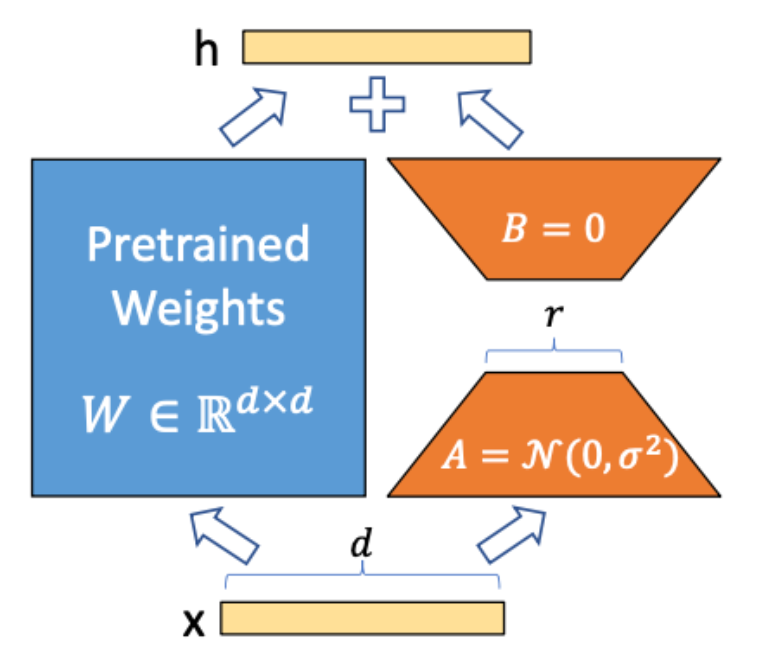
LoRA 的核心思想是将预训练模型的权重矩阵分解为两个低秩矩阵的乘积。假设原有矩阵权重为W微调过程中拆解成两个低秩矩阵A、B的乘积,冻结原有矩阵`+`两个低秩矩阵的乘积来适应新的任务。
优点:减少了训练参数数量,从而降低了计算和存储成本。灵活行较高能使用多种场景。
缺点:有一定技术复杂性相对全参调整需要多次尝试与实验。
3. Qlora
 QLoRA是一种量化LoRA 的方法,它结合了LoRA和量化技术,通过在模型微调过程中引入低秩矩阵和量化技术,降低模型的存储和计算成本,同时保留微调后的模型性能。QLoRA主要用于大模型的微调,对比其他模型微调的好处就是节约微调空间与运行需要的空间。
QLoRA是一种量化LoRA 的方法,它结合了LoRA和量化技术,通过在模型微调过程中引入低秩矩阵和量化技术,降低模型的存储和计算成本,同时保留微调后的模型性能。QLoRA主要用于大模型的微调,对比其他模型微调的好处就是节约微调空间与运行需要的空间。
量化 (Quantization):是将高精度的浮点数(如FP32或FP16)转换为较低精度的整数(如int8或int4)表示,以减少模型的存储空间和加速推理。
4. 适配器微调(Adapter Tuning)
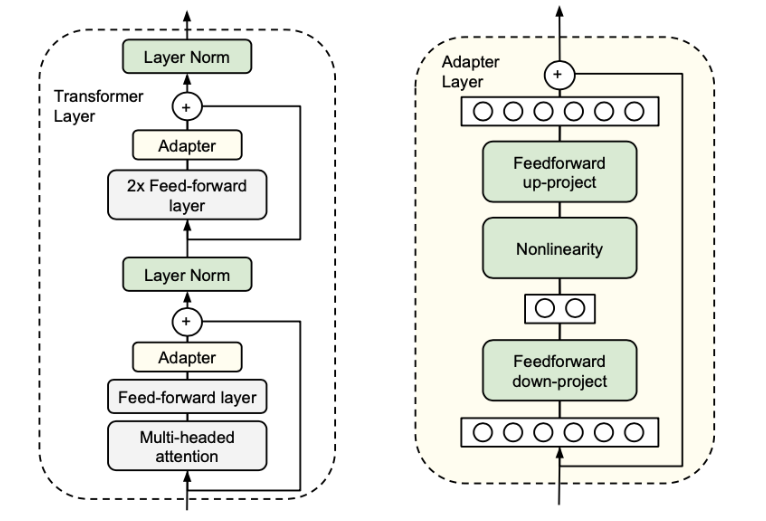
通过在预训练模型中插入适配器模块(Adapters)来实现对特定任务的适应,不需要更新整个模型的参数,适配器模块插入到各个层中,每个模块都仅有少量参数组成。适配器模块主要通过非线性的方式将高纬度数值映射为低纬度,然后再将关键的低纬度数值映射到高纬度中方便大模型的编译计算。同时使用跳跃连接方式保证,如果适配器初始参数过会直接从输入到输出,来保证模型有效。
因原理是在大模型不同层次中插入适配器多个适配器可以存在同一模型中,每种适配器可以处理单独的一类问题,同一模型中可以插入不同的适配器模块,能够同时处理多种不同的任务。
因这种需要直接插入到模型层级中,导致训练复杂度与设计度较高。比较容易产生过拟合等问题。
5. 其他微调
冻结微调(Frozen Fine-tuning)
定义:只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。
应用场景:目标任务与预训练模型之间有一定相似性,或者任务数据集较小。但是微调性能很难达到最佳。
逐层微调(Layer-wise Fine-tuning)
定义:从顶层开始,逐渐向底层推进。这种方法允许更细粒度地控制模型的调整过程,直到所有层应用场景:适用于需要精细调整模型的任务。但是需要多次调整与训练,且花费时间较长
动态微调(Dynamic Fine-tuning)
定义:在微调过程中动态调整学习率、批量大小等超参数,以优化模型性能。
应用场景:适用于需要高性能和高精度的任务。实现方式复杂且对资源要求较高
6. 人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)

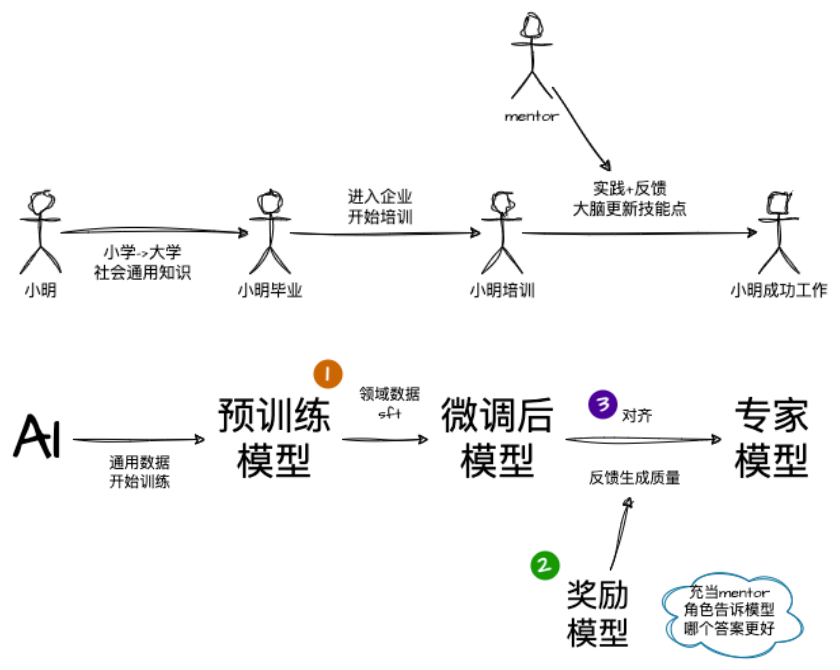
第一步:训练监督策略模型
从提示词数据集中取样一个提示词:首先,从包含各种提示词的数据集中随机选取一个提示词作为初始输入。
数据标记工程师给出期望的输出行为:然后,由人工标注员为这个提示词提供一个期望的故事内容或结构,这将作为模型的目标输出。
通过监督学习微调:接下来,使用监督学习的方法对模型进行微调,使其能够基于提供的提示词生成接近于预期结果的故事。
第二步:训练奖励模型
取样一个提示词和模型多个输出:在这个阶段,再次从数据集抽取一个提示词,并让模型产生多个不同的故事版本。
数据标记工程师给出优劣排序:人工标注员会对这些不同版本的故事进行评估并按质量高低进行排序。
训练奖励模型:最后,用这些带有评分的故事样本去训练一个奖励模型,该模型学会预测哪些故事更符合人类的标准。
第三步:采用近端策略优化进行强化学习
从提示词数据集取样一个新的提示词:继续从数据集中获取新的提示词作为下一个迭代的基础。
PPO模型由模型初始化:使用之前训练好的模型开始生成故事。
模型生成一个输出:模型尝试根据新提示词生成一个完整的故事。
奖励模型计算输出奖励值:接着,奖励模型会评价这个新生成的故事,并给出相应的分数。
利用PPO算法结合奖励更新策略:最后,通过Proximal Policy Optimization (PPO)算法,结合奖励模型的反馈来调整模型的行为,使得它在未来能够生成更加高质量的故事。
7. PPO(近端优化策略)
引入了策略网络与价值网络的概念。通过策略网络生成动作的概率分布。使用价值网络估计当前状态的价值函数,即从当前状态开始的期望累积奖励。在每个训练周期(epoch)内,使用当前策略在环境中收集一批经验(状态、动作、奖励、下一状态等)。在环境内进行交互,并且将每一次循环后的经验存储在一个缓冲区方便后续迭代累计使用。通过限制每次更新的幅度来提高训练的稳定性,比较适合处理复杂的决策任务。
8. DPO(直接偏好优化)
通过直接利用人类的偏好数据来优化模型。与传统的强化学习方法(如RLHF)不同,DPO不需要构建复杂的奖励模型,而是通过比较不同输出的优劣来进行训练。DPO的核心在于创建一个包含人类偏好的数据集,每个数据对由一个提示和两个可能的输出(一个是首选,另一个是不受欢迎)组成。模型通过最大化生成首选输出的概率,同时最小化生成不受欢迎输出的概率来进行微调。这一过程可以看作是一个分类问题,模型的目标是提高对首选输出的生成概率,并降低对不受欢迎输出的生成概率
9. GRPO(组相对策略优化)
GRPO的核心原理 GRPO是一种改进的强化学习策略优化方法,其核心在于通过分组优化和相对策略更新,提升训练效率与稳定性。以下是其关键原理:
-
分组(Grouping)
- 定义:将训练数据划分为多个小组(Group),每组包含具有相似特征或目标的样本。
- 目的:减少全局优化的复杂性,专注于组内相对改进。
- 分组依据:例如任务类型、数据难度、用户偏好等。
-
相对策略优化(Relative Policy Optimization)
- 组内比较:在每组内评估策略的相对表现,而非全局绝对表现。
- 奖励设计:使用组内相对奖励(如排名、进步幅度)作为优化目标,激励模型在组内竞争中提升。
- 示例:在游戏中,若某组玩家水平相近,优化目标是让每个玩家比同组其他玩家表现更好。
-
稳定性控制
- 更新幅度限制:通过裁剪(Clipping)或信任域(Trust Region)方法,防止策略更新过大。
- 平衡探索与利用:在组内优化时,既鼓励改进,又避免过度偏离当前策略。
10. SFT(监督式微调)
是一种通过带标注的数据对预训练大模型进行进一步训练的方法。其核心目标是让模型在特定任务(如文本分类、问答、生成)中表现更好,属于监督学习的范畴。
- 类比:就像让一个通才(预训练模型)通过专业培训(带标注的数据)成为某一领域的专家(任务专用模型)。
SFT 的核心原理
- 预训练模型:模型已通过海量无标注数据(如互联网文本)学习通用语言模式。
- 标注数据:针对目标任务的标注样本(如问答对、分类标签)。
- 微调过程:在预训练模型基础上,用标注数据调整模型参数,使其适配特定任务。
SFT 的优势与挑战
优势
- 简单高效:直接利用标注数据优化模型,无需复杂算法设计。
- 快速适配:少量数据即可显著提升任务表现(如百条标注样本)。
- 可解释性强:监督学习过程透明,易于调试。
挑战
- 数据依赖:需要高质量标注数据,人工标注成本高。
- 过拟合风险:小数据集上易过拟合(表现为训练集高分,测试集低分)。
- 领域局限:微调后的模型可能在其他任务上表现下降。
四. PEFT是什么?为什么需要PEFT?
答:PEFT(Parameter-Efficient Fine-Tuning,参数高效微调):是一种微调策略,核心是仅训练少量额外参数(通常<1%总参数),保留预训练大模型原始权重,通过轻量级调整将通用能力适配到具体任务。
为什么需要PEFT:
-
解决全量微调的高成本问题:
预训练大模型(如LLaMA-65B、GPT-3)参数达百亿/千亿级,全量微调需千卡集群、数月时间,计算/存储成本极高(如GPT-3微调成本超百万美元)。
-
避免小数据集过拟合:
微调通常用小规模标注数据(MB-GB级),全量调整易破坏预训练的通用知识,导致过拟合;PEFT仅调少量参数,保留原模型泛化能力。
-
提升任务适配效率:
PEFT(如LoRA、QLoRA)通过低秩矩阵、适配器模块等轻量级设计,性能接近全量微调,但资源消耗降低90%以上(如QLoRA可在16GB GPU上微调65B模型)。
-
支持多任务灵活切换:
额外参数(如LoRA的低秩矩阵)可与原始模型分离,多任务只需存储少量适配器,无需重复加载全量模型。
核心逻辑:用“最小参数改动”实现“最大任务适配”,平衡性能-成本比,是大模型落地(尤其是消费级/企业级场景)的关键技术。PEFT的典型方法:LoRA,适配器微调,QLoRA。
五. 微调中常用的优化器有哪些?
答:1. AdamW(Adam with Weight Decay)
核心特点:结合Adam的自适应学习率(一阶矩估计+二阶矩估计)与正确的权重衰减(Weight Decay,直接作用于参数而非梯度),解决Adam中权重衰减失效的问题
微调优势:
-
自适应调整各参数学习率,适合小数据集(避免手动调参);
-
权重衰减有效防止过拟合(微调易破坏预训练知识);
-
是Hugging Face Transformers库默认优化器,广泛用于全量微调与PEFT(如LoRA、QLoRA)。
-
典型场景:BERT/RoBERTa分类微调、LLaMA生成任务微调。
2. SGD(Stochastic Gradient Descent)
核心特点:经典优化器,沿负梯度方向更新参数,需手动设置学习率(LR)和动量(Momentum)。
微调优势:
-
收敛稳定,适合小模型+小数据集(如BERT-base微调);
-
对学习率调度(如余弦退火)敏感,可通过调整LR探索最优解。
-
局限:自适应能力差,需更多调参 effort,大模型微调中较少用。
3. Lion(EvoLved Sign Momentum)
核心特点:较新的优化器,用动量符号函数(Sign of Momentum)替代Adam的二阶矩估计,更新规则更简洁(mt=βmt−1+(1−β)gt;θt=θt−1−η⋅sign(mt))。
微调优势:
-
内存占用低于Adam(无需存二阶矩),适合大模型(如LLaMA-65B);
-
在PEFT(如LoRA)中表现优于AdamW,收敛更快且性能相当。
-
典型场景:QLoRA微调、大模型少样本适配。
4. AdaFactor
核心特点:Adam的内存高效变种,将二阶矩估计从向量压缩为标量( per-parameter group),减少内存占用。
微调优势:
-
适合超大模型(如GPT-3),内存消耗仅为Adam的1/3;
-
保持自适应学习率优势,微调时性能接近AdamW。
5. RMSprop
核心特点:用二阶矩的指数移动平均调整学习率(类似Adam但无动量),适合非平稳目标(如生成任务的波动损失)。
微调优势:在文本生成(如对话、摘要)中偶尔使用,缓解损失震荡。


















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









