



一. 什么是RAG?
官方解释:
RAG是一种用附加数据扩充LLM知识的技术。
LLM可以推理广泛的主题,但他们的知识仅限于公共数据,直到他们接受培训的特定时间点。如果你想构建人工智能应用程序来推理私人数据或模型截止日期后引入的数据,你需要用模型所需的特定信息来扩充模型的知识。引入适当信息并将其插入模型提示符的过程被称为检索增强生成(RAG)。
通俗理解:
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合“外部知识检索”与“AI生成”的混合技术框架,核心目标是让AI在回答问题或生成内容时,既依赖自身训练知识,又能实时调用外部权威信息,从而提升输出的准确性、时效性和针对性。
想象你要回答一个专业问题(比如“2025年全球GDP增长预测”),但你的“大脑”(AI模型)里只存了2024年的旧数据。这时候,RAG会先帮你从最新的数据库(如世界银行、IMF报告)里“查资料”(检索),再把查到的信息和你的“大脑”知识结合,最终生成更准确的答案。
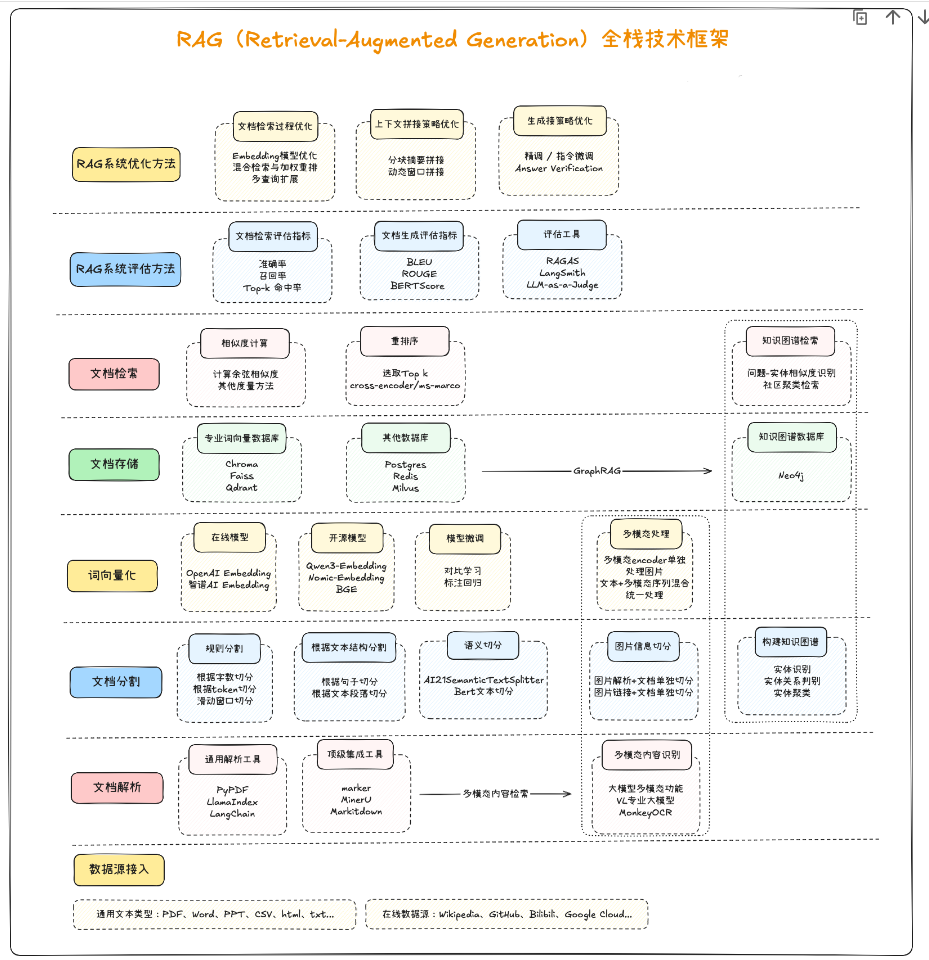
二. RAG全栈技术体系介绍
以下是RAG技术全栈技术框架概览:
三. RAG工作流程
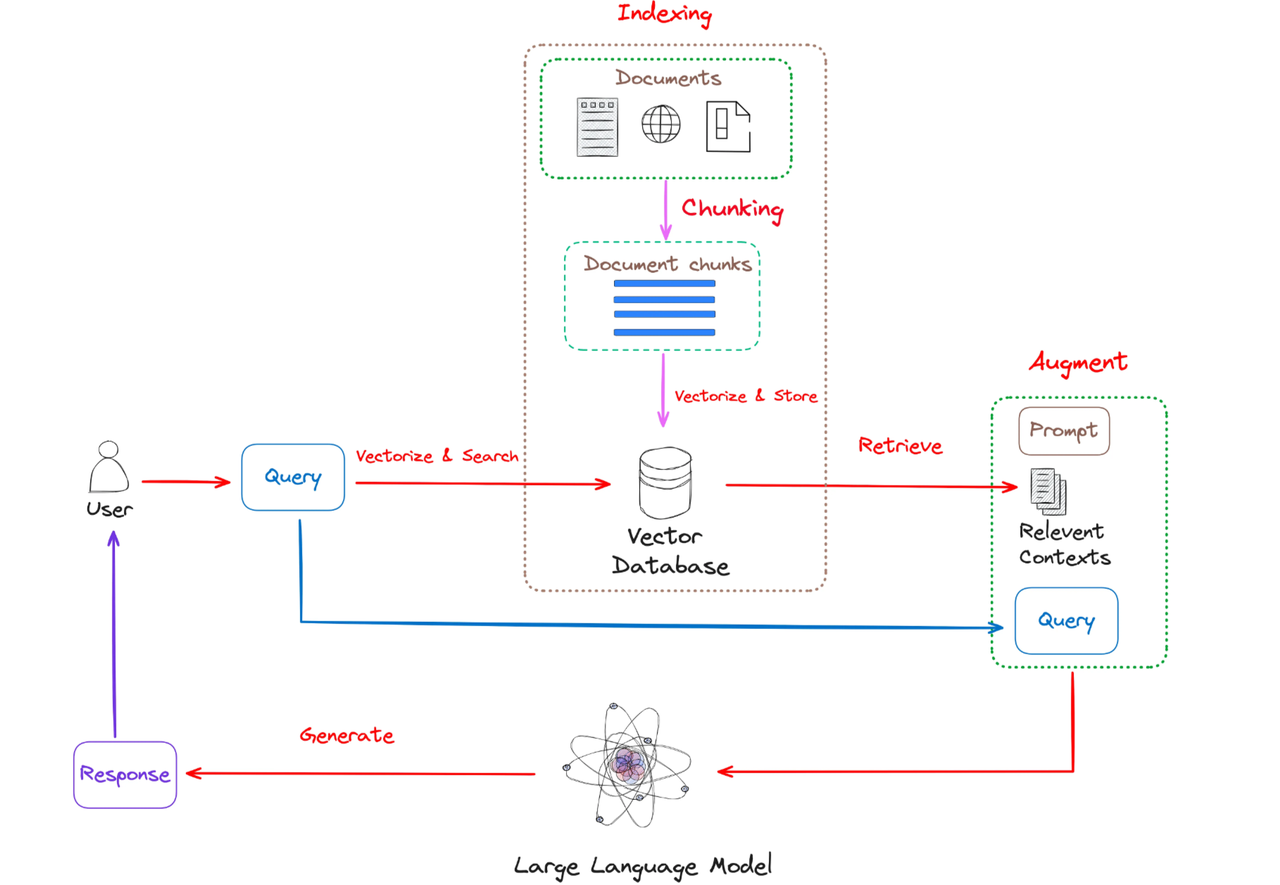
如上图所示,RAG主要包括以下步骤:
- 索引(Indexing)
索引过程是离线执行的关键初始步骤。首先清理和提取原始数据,将 PDF、HTML 和 Word 等各种文件格式转换为标准化纯文本。为了适应语言模型的上下文约束,这些文本被分为更小且更易于管理的块,这个过程称为分块。然后使用嵌入模型将这些块转换为向量表示。最后,创建一个索引来将这些文本块及其向量嵌入存储为键值对,从而实现高效且可扩展的搜索功能。
-
检索(Retrieval)
用户查询用于从外部知识源检索相关上下文。为了实现这一点,用户查询由编码模型处理,该模型生成语义相关的嵌入。然后,对向量数据库进行相似性搜索,以检索前k个最接近的数据对象。
-
生成(Generation)
将用户查询和检索到的附加上下文填充到提示模板中。最后,将检索步骤中的增强提示输入到LLM中。
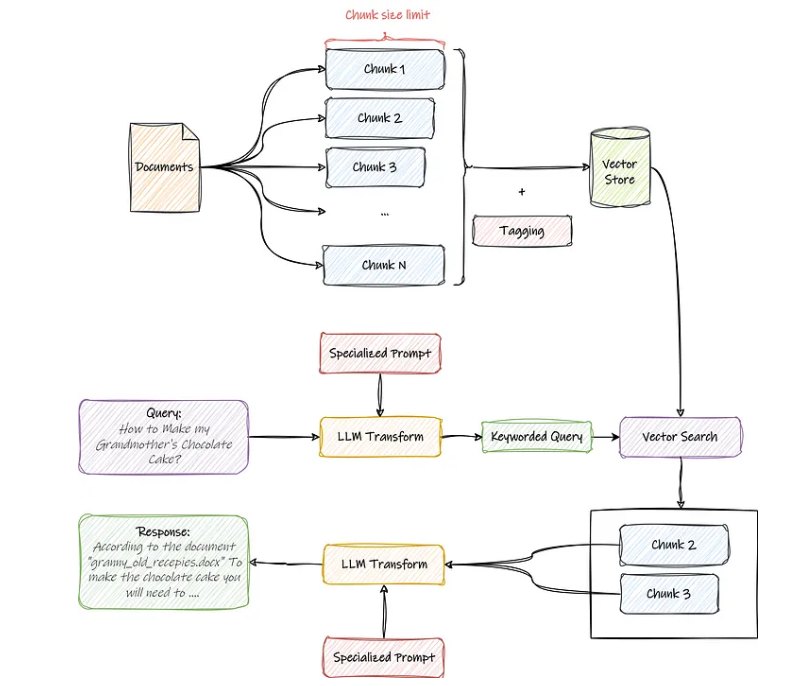
更加细化的数据处理流程如下:
四. RAG系统开发框架
- 最佳RAG系统开发开源框架:LangChain&LangGraph
在当前的大模型应用开发生态中,LangChain 已经成为构建RAG(Retrieval-Augmented Generation)系统最受欢迎的框架之一。LangChain 不仅提供了面向开发者的高层API,还整合了文档加载、文本分块、向量检索、上下文拼接、输出解析等全流程工具,极大降低了RAG应用的开发门槛。在检索阶段,LangChain 提供了多种Document Loaders(如PDF、Markdown、网页、数据库加载器),并内置了RecursiveCharacterTextSplitter、MarkdownHeaderTextSplitter等分块工具,方便将原始文本转化为高质量的检索单元。向量化方面,LangChain兼容主流Embedding模型(OpenAI Embedding、Hugging Face模型、Cohere等),并支持Chroma、FAISS、Weaviate、Pinecone等多种向量数据库无缝集成。
在生成与问答环节,LangChain封装了RetrievalQA、ConversationalRetrievalChain、MultiQueryRetriever等常用组件,能够快速搭建基于单轮或多轮对话的检索增强问答系统。对于更高阶的能力,LangChain还支持LLM Chain与Agent模式,开发者可以通过工具调用和多步骤推理,构建具备复杂交互逻辑的Agentic RAG系统。总体来看,LangChain为RAG开发提供了丰富的工具集和模块化能力,使构建一个可扩展的知识检索与生成系统从“几周工程”缩短为“几天内可原型验证”。
- 新一代Agents SDK、ADK内置的在线RAG服务
在最新的大模型技术体系中,OpenAI Agent SDK和谷歌 Agent Development Kit(ADK)分别代表了两大云平台对检索增强生成(RAG)能力的官方支持路径,两者虽然同属“Agent+RAG”范式,但在功能侧重点和生态整合方面各有特色。
OpenAI Agent SDK通过原生File Search机制,为开发者提供了极简化的RAG接入方式。用户仅需在Assistant配置中启用文件检索工具,便可实现自动分块、向量化与高效召回,整个过程在OpenAI云端一体化托管,无需额外配置数据库或索引管理。该模式支持多轮对话的上下文跟踪和结果拼接,能够与Function Calling无缝结合,实现“先检索后调用工具”的闭环逻辑,尤其适合对系统稳定性和开发便捷性要求较高的场景。
相比之下,谷歌ADK则在多模态检索与推理流水线方面提供了更强的灵活性。其核心能力之一“Grounding”不仅支持文本向量检索,还能原生处理PDF、表格、扫描件等多模态数据,并提供自动可追溯引用功能,使答案生成过程更加透明可信。ADK允许开发者通过流水线(Pipeline)将检索、摘要、分类等步骤串联组合,构建复杂的多步推理流程,并支持与谷歌云生态(Drive、Gmail、Cloud Storage)深度集成。
总体而言,OpenAI Agent SDK更加专注于“一体化、低门槛的RAG体验”,而谷歌ADK则以“多模态、可编排、高可扩展性”为核心定位。两者均标志着RAG技术从最初的工程框架(如LangChain、LlamaIndex)走向平台原生支持,也体现了未来智能体开发将更加重视知识检索、自动推理和可追溯性等能力的趋势。

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









